 跨域小样本语义分割新基准介绍
跨域小样本语义分割新基准介绍

前言
继医学图像处理系列之后,我们又回到了小样本语义分割主题上,之前阅读笔记的链接我也在文末整理了一下。
小样本语义分割旨在学习只用几个带标签的样本来分割一个新的对象类,大多数现有方法都考虑了从与新类相同的域中采样基类的设置(假设源域和目标域相似)。
然而,在许多应用中,为元学习收集足够的训练数据是不可行的。这篇论文也将小样本语义分割扩展到了一项新任务,称为跨域小样本语义分割(CD-FSS),将具有足够训练标签的域的元知识推广到低资源域,建立了 CD-FSS 任务的新基准。
在开始介绍 CD-FSS 之前,我们先分别搞明白广义上跨域和小样本学习的概念(这个系列后面的文章就不仔细介绍了)。小样本学习可以分为 Zero-shot Learning(即要识别训练集中没有出现过的类别样本)和 One-Shot Learning/Few shot Learning(即在训练集中,每一类都有一张或者几张样本)。几个相关的重要概念:
域:一个域 D 由一个特征空间 X 和特征空间上的边缘概率分布 P(X) 组成,其中 X=x1,x2,.....,xn,P(X) 代表 X 的分布。
任务:在给定一个域 D={X, P(X)} 之后,一个任务 T 由一个标签空间 Y 以及一个条件概率分布 P(Y|X) 构成,其中,这个条件概率分布通常是从由特征—标签对 ∈X,∈Y 组成的训练数据(已知)中学习得到。父任务,如分类任务;子任务,如猫咪分类任务,狗狗分类任务。
Support set:支撑集,每次训练的样本集合。
Query set:查询集,用于与训练样本比对的样本,一般来说 Query set 就是一个样本。
在 Support set 中,如果有 n 个种类,每个种类有 k 个样本,那么这个训练过程叫 n-way k-shot。如每个类别是有 5 个 examples 可供训练,因为训练中还要分 Support set 和 Query set,那么 5-shots 场景至少需要 5+1 个样例,至少一个 Query example 去和 Support set 的样例做距离(分类)判断。
现阶段绝大部分的小样本学习都使用 meta-learning 的方法,即 learn to learn。将模型经过大量的训练,每次训练都遇到的是不同的任务,这个任务里存在以前的任务中没有见到过的样本。所以模型处理的问题是,每次都要学习一个新的任务,遇见新的 class。 经过大量的训练,这个模型就理所当然的能够很好的处理一个新的任务,这个新的任务就是小样本啦。
meta-learning 共分为 Training 和 Testing 两个阶段。
Training 阶段的思路流程如下:
将训练集采样成支撑集和查询集。
基于支撑集生成一个分类模型。
利用模型对查询集进行预测生成 predict labels。
通过查询集 labels(即ground truth)和 predict labels 进行 loss 计算,从而对分类模型 C 中的参数 θ 进行优化。
Testing 阶段的思路:
利用 Training 阶段学来的分类模型 C 在 Novel class 的支撑集上进一步学习。
学到的模型对 Novel class 的查询集进行预测(输出)。
总的来说,meta-learning 核心点之一是如何通过少量样本学习分类模型C。
再来解释下为什么要研究跨域的小样本学习,当目标任务与源任务中数据分布差距过大,在源域上训练得到的模型无法很好的泛化到目标域上(尤其是基于元学习的方法,元学习假设源域和目标域相似),从而无法提升目标任务的效果,即在某一个域训练好的分类模型在其他域上进行分类测试时,效果不理想。
如果能用某种方法使得源域和目标域的数据在同一分布,则源任务会为目标任务提供更加有效的先验知识。至此,如何解决跨域时目标任务效果不理想的问题成了跨域的小样本学习。
如下图,跨域小样本学习对应当源域和目标域在不同子任务(父任务相同)且不同域下时,利用通过源域获得的先验知识帮助目标任务提高其 performance,其中已有的知识叫做源域(source domain),要学习的新知识叫目标域(target domain)。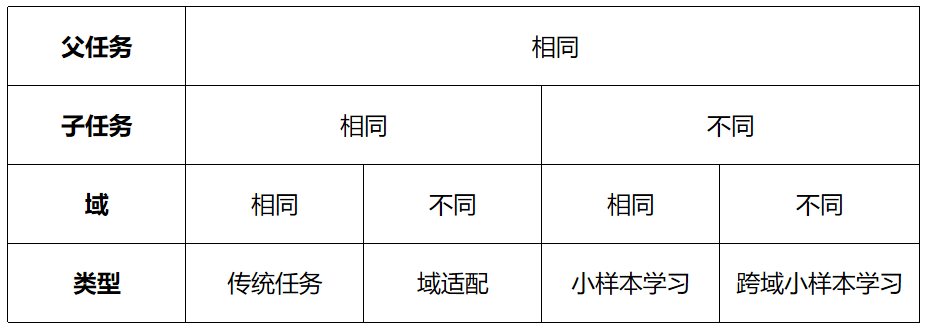
概述
在经过对跨域小样本学习的详细介绍后,我们再回到发表在 ECCV 2022 的 Cross-Domain Few-Shot Semantic Segmentation 这篇论文上。这篇文章为 CD-FSS 建立了一个新的基准,在提出的基准上评估了具有代表性的小样本分割方法和基于迁移学习的方法,发现当前的小样本分割方法无法解决 CD-FSS。
所以,提出了一个新的模型,被叫做 PATNet(Pyramid-Anchor-Transformation),通过将特定领域的特征转化为下游分割模块的领域无关的特征来解决 CD-FSS 问题,以快速适应新的任务。
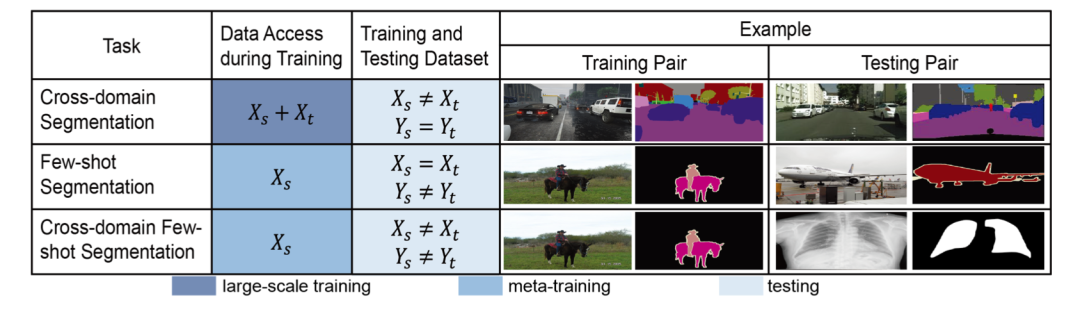
下图是论文里给出的跨域的小样本分割与现有任务的区别。 和 分别表示源域和目标域的数据分布。 代表源标签空间, 代表目标标签空间。
Proposed benchmark
提出的 CD-FSS 基准由四个数据集组成,其特征在于不同大小的域偏移。包括来自 FSS-1000 、Deepglobe、ISIC2018 和胸部 X-ray 数据集的图像和标签。
这些数据集分别涵盖日常物体图像、卫星图像、皮肤损伤的皮肤镜图像和 X 射线图像。所选数据集具有类别多样性,并反映了小样本语义分割任务的真实场景。如下图:
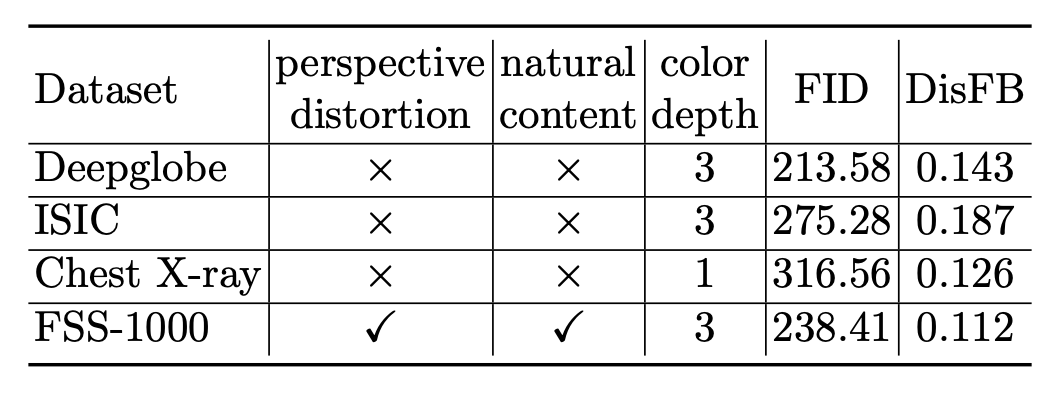
在下表中,每个域的任务难度从两个方面进行衡量:1)域迁移(跨数据集)和 2)单个图像中的类别区分(在数据集中)。 Fŕechet Inception Distance (FID) 用于测量这四个数据集相对于 PASCAL 的域偏移,于是单个图像中的域偏移和类别区分分别由 FID 和 DisFB 测量。由于单个图像中类别之间的区分对分割任务有重要影响,使用 KL 散度测量前景和背景类别之间的相似性。
整体机制 with CD-FSS
CD-FSS 的主要挑战是如何减少领域转移带来的性能下降。以前的工作主要是学习 Support-Query 匹配模型,假设预训练的编码器足够强大,可以将图像嵌入到下游匹配模型的可区分特征中。
然而在大领域差距下,只在源域中预训练的 backbone 在目标域中失败了,如日常生活中的物体图像到 X-ray 图像。
为了解决这个问题,模型需要学会将特定领域的特征转化为领域无关的特征。这样一来,下游模型就可以通过匹配 Support-Query 的领域无关的特征来进行分割,从而很好地适应新领域。
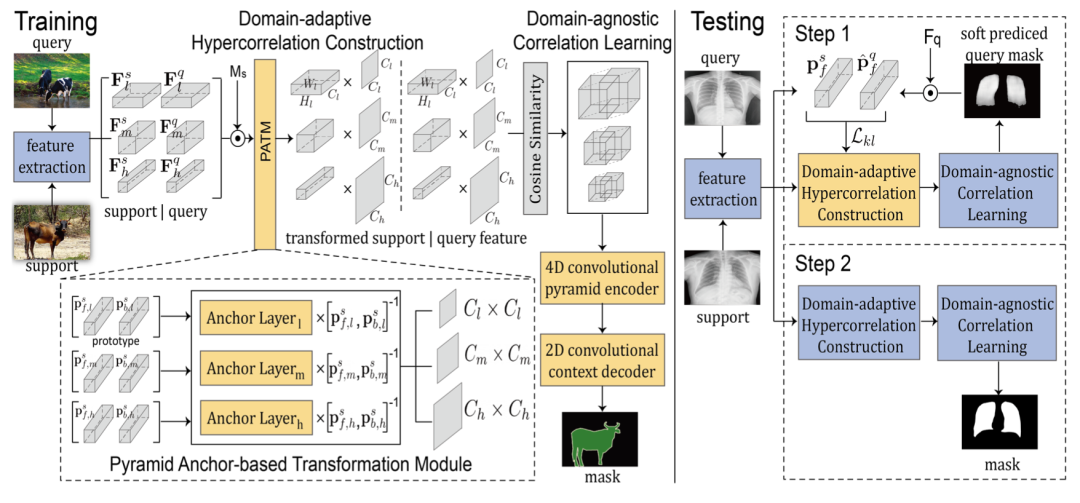
如下图所示(左边训练,右边测试),整体机制由三个主要部分组成,即特征提取 backbone、domain-adaptive hypercorrelation construction 和 domain-agnostic correlation learning。对于输入的 Support-Query 图像,首先用特征提取器提取所有的中间特征。然后,我们在 domain-adaptive hypercorrelation construction 部分引入一个特别新颖的模块,称为 Pyramid Anchor-based Transformation Module(PATM),将特定领域的特征转换为领域无关的特征。
接下来,用所有转换后的特征图计算多层次的相关图,并将其送入 domain-agnostic correlation learning 部分。使用两个现成的模块,分别为 4D 卷积金字塔编码器和 2D 卷积上下文解码器,被用来以粗到细的方式产生预测掩码,并具有高效的 4D 卷积。
在测试阶段,论文里还提出了一个任务自适应微调推理(TFI)策略,以鼓励模型通过 Lkl 损失微调 PATM 来快速适应目标领域,Lkl 损失衡量 Support-Query 预测之间的前景原型相似度。
PATNet
上一部分提到 PATM 将特定领域的特征转换为领域无关的特征,这一部分我们仔细看一下。Pyramid Anchor-based Transformation Module(PATM)的核心思想是学习 pyramid anchor layers,将特定领域的特征转换为领域无关的特征。直观地说,如果我们能找到一个转化器,将特定领域的特征转化为领域无关的度量空间,它将减少领域迁移带来的不利影响。由于领域无关的度量空间是不变的,所以下游的分割模块在这样一个稳定的空间中进行预测会更容易。
理想情况下,属于同一类别的特征在以同样的方式进行转换时将产生类似的结果。因此,如果将 Support 特征转换为领域空间中的相应锚点,那么通过使用相同的转换,也可以使属于同一类别的 Query 特征转换为接近领域空间中的锚点。采用线性变换矩阵作为变换映射器,因为它引入的可学习参数较少。
如上一部分中的图,使用 anchor layers 和 Support 图像的原型集来计算变换矩阵。如果 A 代表 anchor layers 的权重矩阵,P 表示 Support 图像的原型矩阵。既通过寻找一个矩阵来构建转换矩阵 W,使 WP=A。
任务自适应微调推理(TFI)策略
为了进一步提高 Query 图像预测的准确率,提出了一个任务自适应微调推理(TFI,Task- adaptive Fine-tuning Inference)策略,以便在测试阶段快速适应新的对象。
如果模型能够为 Query 图像预测一个好的分割结果,那么分割后的 Query 图像的前景类原型应该与 Support 的原型相似。
与优化模型中的参数不同,我们只对 anchor layers 进行微调,以避免过拟合。上图右侧显示了该策略的流程,在测试阶段,在第 1 步(step 1)中,只有锚层使用提议的 Lkl 进行相应的更新,Lkl 衡量 Support 和 Query set 的前景类原型之间的相似性。在第 2 步(step 1)中,模型中的所有层都被冻结,并对 Query 图像进行最终预测。通过这种方式,模型可以快速适应目标域,并利用经过微调的 anchor layers 产生的辅助校准特征对分割结果进行完善。
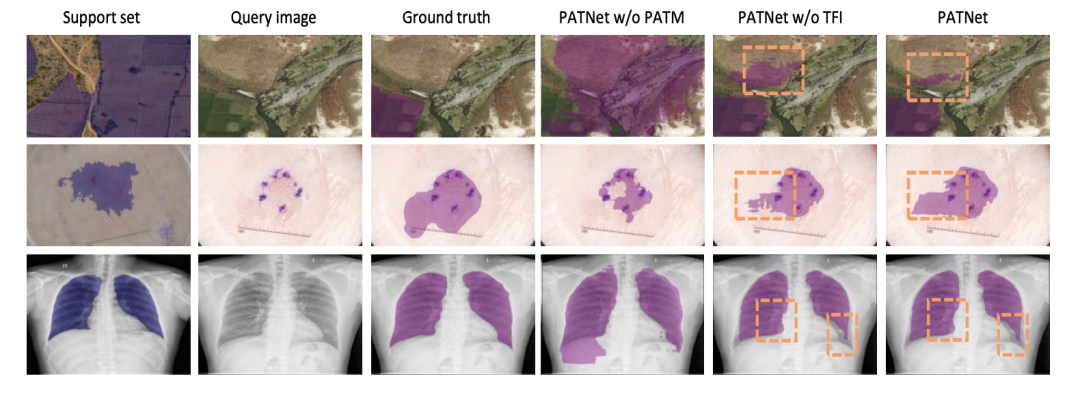
如下图是几个 1-shot 任务的可视化比较结果。对于每个任务,前三列显示 Support 和 Query set 的金标准。接下来的两列分别表示没有PATM 和没有 TFI 的分割结果,最后一列显示了用 Lkl 微调后的最终分割结果。
实验和可视化
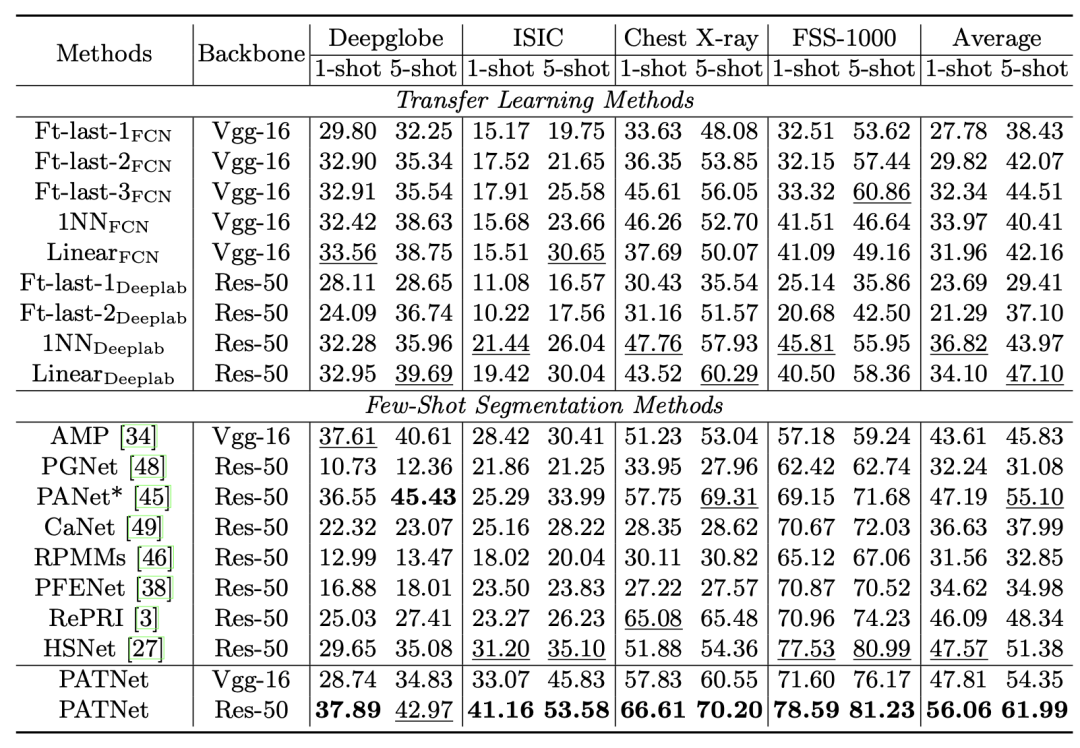
如下表所示,是元学习和迁移学习方法在 CD-FSS 基准上的 1-way 1-shot 和 5-shot 结果的平均 IoU。所有的方法都是在 PASCAL VOC 上训练,在 CD-FSS 上测试。
下图是模型在 CD-FSS 上进行 1-way 1-shot 分割的定性结果。其中,Support 图像标签是蓝色。Query 图像标签和预测结果是另一种颜色。
总结
这篇论文也将小样本语义分割扩展到了一项新任务,称为跨域小样本语义分割(CD-FSS)。建立了一个新的 CD-FSS benchmark 来评估不同域转移下小样本分割模型的跨域泛化能力。实验表明,由于跨域特征分布的巨大差异,目前 SOTA 的小样本分割模型不能很好地泛化到来自不同域的类别。所以,提出了一种新模型,被叫做 PATNet,通过将特定领域的特征转换为与领域无关的特征,用于下游分割模块以快速适应新的领域,从而也解决了 CD-FSS 问题。
审核编辑:刘清
-
图像处理
+关注
关注
28文章
1340浏览量
59181 -
FSS
+关注
关注
0文章
13浏览量
9932
原文标题:ECCV 2022: 跨域小样本语义分割新基准
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
航盛电子搭载QNX技术的墨子跨域融合平台正式量产
黑芝麻智能武当C1200家族作为跨域计算芯片的核心突破
模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题


黑芝麻智能跨域时间同步技术:消除多域计算单元的时钟信任鸿沟

【正点原子STM32MP257开发板试用】基于 DeepLab 模型的图像分割
凡亿Allegro Skill布线功能-检查跨分割
跨异步时钟域处理方法大全
航盛电子推出基于高通和QNX技术的全新一代墨子舱驾跨域融合平台
探索对抗训练的概率分布偏差:DPA双概率对齐的通用域自适的目标检测方法

SparseViT:以非语义为中心、参数高效的稀疏化视觉Transformer

TSP研究:车内网联服务向跨域融合、全场景融合、舱驾融合方向拓展





 工商网监
工商网监
评论