 一种创新的存内计算架构
一种创新的存内计算架构

摘要
传感器和数据生成设备的大规模发展推动了现代计算范式的转变,从以算术逻辑为中心向以数据为中心的处理。在硬件层面,这迫切需要将密集、高性能和低功耗的存储单元与Si逻辑处理器单元集成起来。然而,像搜索和模式匹配这样的数据密集型问题也需要在电路和架构级别进行范式更改创新,以支持内存计算(CIM)操作。CIM体系结构结合了数据存储,同时提供低延迟和小占用是非常受欢迎的,但尚未实现。在这里,我们提出了氮化铝钪(AlScN)铁电二极管(FeD)忆阻器件,允许存储,搜索和基于神经网络的模式识别在一个无晶体管的架构。我们的设备可以直接集成在Si处理器的顶部,以可扩展的后端流程。我们利用联邦储备系统的现场可编程性、非波动性和非线性来演示电路块,该电路块可以支持原位内存搜索操作,搜索延迟时间< 0.1 ns,单元占用面积< 0.12µm²。此外,我们还演示了用FeD的4位运算进行矩阵乘法运算。我们的研究结果表明,FeD是快速、高效和多功能CIM平台的有前途的候选者。
简介
大数据与人工智能(AI)的融合催生了多个新兴技术,涵盖了一系列计算应用。传感器和边缘/物联网设备的日益普遍的存在创造了大量的数据,这暴露了计算硬件的巨大效率差距,从移动和边缘设备到数据中心和云计算硬件。此外,基于硅的互补金属氧化物半导体(CMOS)器件小型化的放缓进一步加剧了基于传统冯·诺依曼计算硬件架构(特别是中央处理单元(CPU)、图形处理单元(GPU)和现场可编程门阵列(FPGA))之间的资源需求差距。此外,众所周知,在冯·诺依曼架构中,许多以数据为中心的任务,大部分的能量和时间都消耗在内存访问和数据移动上,而不是实际的计算上。为了缓解和克服这一瓶颈,已经提出了几种解决方案,其中一个突出的解决方案是将内存和逻辑单元放置在物理上非常接近的位置。虽然在材料和设备层面上这些方面已经取得了重大进展,但一种革命性的方法将是使用原位存储器执行计算功能。这通常称为存内计算(CIM)。CIM的首要目标是通过在数据存储的位置就地完成计算,从根本上改变计算架构,而不是通过在内存带宽、新的非易失性内存(NVM)技术和数据并行性方面的单独优化来重新设计传统的冯·诺依曼架构架构。虽然已经有几个使用冯·诺依曼架构的CIM体系结构演示,但大部分工作都被限制在单一类型的计算任务上,例如矩阵乘法加速器,通常使用记忆交叉条阵列实现。然而,利用“大数据”的AI计算任务通常需要在同一个芯片上进行多个数据密集型计算操作,最好使用相同的架构来处理管道中的信息。三个最重要的功能或操作是:1)片上存储,2)并行搜索,3)矩阵乘法。构建CIM体系结构的一个关键挑战是实现这三个功能所需的性能和灵活性之间的矛盾权衡。因此,虽然CIM加速器已经被证明可以在矩阵乘法加速方面实现高性能,但从根本上来说,它们并不适合于并行搜索等其他大数据操作。因此,为CIM概念化和开发可重构和操作灵活的硬件非常重要,以同时支持基本的数据操作,如片上存储器、并行搜索和矩阵乘法加速。
在这项工作中,我们利用了氮化铝钪(AlScN)铁电二极管(FeD)器件的独特特性——特别是其现场可编程性、非波动性和非线性——并演示了基于FeD器件的电路块,该器件在无晶体管设计中支持多个基本原始数据操作的原位存储器(图1)。具体来说,首先,我们展示了非易失性且具有自整流行为的FeD装置,其非线性> 106,高开/关比超过10²,续航超过104个周期,现场编程速度超过500ns,并与CMOS线后端(BEOL)处理兼容。然后,我们利用这些独特的特性,并演示了使用0-晶体管/2-FeD单元的非易失性三元内容寻址存储器(TCAM)。这些都是大数据应用中并行搜索过程的内存计算硬件实现的关键构建块。这种无晶体管的方法是我们的设备和存储单元设计的一个关键优点。因此,与基于2-晶体管/2电阻(2T-2R)的TCAM细胞相比,2-馈源TCAM具有最紧凑的设计(45 nm节点0.12µm²/cell),搜索延迟显著降低(45 nm节点< 0.1 ns),通过集成电路强调(SPICE)模拟进行评估。最后,我们还表明,通过电脉冲,FeD器件可以编程成具有优越线性和对称性的4位独特导电状态。利用这种可编程的、多比特的铁电二极管属性,我们以模拟电压-振幅矩阵乘法的形式演示了神经网络计算的硬件实现,这是神经网络计算的一个关键核心。我们演示了接近理想的、基于软件的神经网络的准确性。通过在卷积神经网络体系结构中将神经网络权重映射到实验FeD电导状态,对矩阵乘法操作进行基准测试,用于推理和原位学习任务,结果表明我们的精度接近MNIST数据集的理想软件级模拟。我们的研究结果表明,基于氮化铝钪(AlScN)、现场可编程、非volatile的FEDS为构建可重构CIM体系结构提供了独特的机会,可以在性能和灵活性之间取得卓越的平衡。
现场可编程氮化铝钪(AlScN)
铁电二极管(FeD)存储器
我们的FeD器件由一层45纳米厚的溅射沉积铁电AlScN层夹在顶部和底部的铝电极之间。这形成了金属绝缘体(MIM)结构,如图2a左面板所示。AlScN是一种新发现的铁电材料,具有近乎理想的铁电滞回线、剩余极化记录值和成分可调的矫顽力场。此外,它可以直接集成在8英寸晶圆上的CMOS BEOL兼容工艺技术中。它也被证明是最有前途的高性能铁电存储器件的候选人之一,可扩展到小于10 nm的厚度。AlScN薄膜进行了电性表征,并表现出2-4.5 MV/cm的大矫顽力场EC。这对于扩展到更薄的铁电层非常重要,同时保持大的内存窗口、高的开/关比和良好的保持。当结合测量到的高残留极化(Pr为80-150μC/cm²)时,基于强的隧道势垒调制,会产生显著的隧穿电阻效应,从而产生高的开/关比(补充注释1)。图2(a)给出了MIM FeD器件的代表性截面透射电子显微镜(TEM)图像,该器件由AlScN薄膜和Al顶部电极组成,沉积在Al/AlScN/Si衬底上。AlScN薄膜的原子分辨率TEM图像如图2(b1)所示。图2(b2)显示了AlScN/底部Al界面处约2nm厚的界面层。
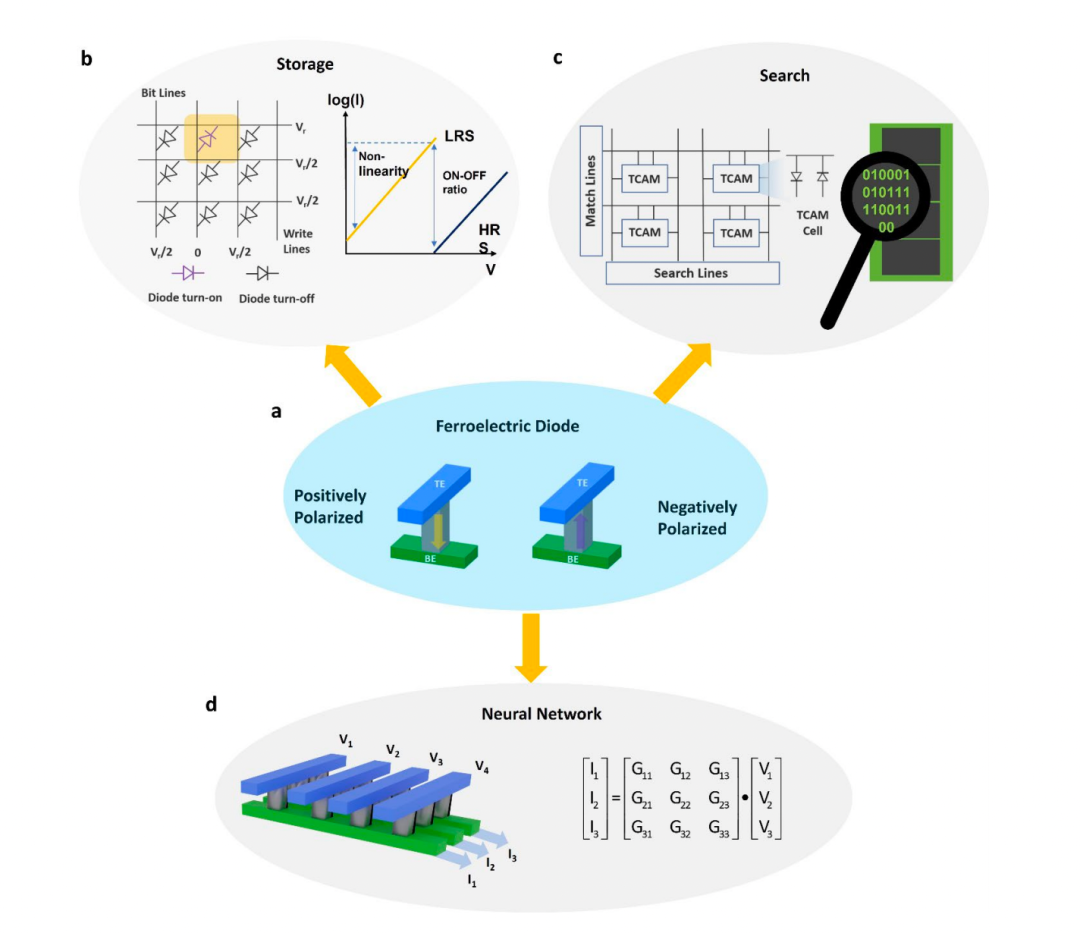
图1所示。基于现场可编程铁电二极管的可重构CIM。
a.具有铁电AlScN上下极化的交叉杆结构中的FeD器件示意图。如b-d所示,这些设备的现场可编程性、非波动性和非线性可以用于多个基本数据操作,如存储、搜索和神经网络,而不需要额外的晶体管。
b.两端FeD器件表现出类似二极管的自整流行为,具有非线性> 106,同时具有超过10²的开/关比和超过104循环的耐久性,使FeD器件在存储的内存层次中处于很好的位置。此外,高非线性可以抑制潜电流,而不需要额外的接入晶体管或选择器。
c.对于搜索操作,一个非易失性TCAM可以建立在0-晶体管/2-FeD单元上,这是大数据应用中并行搜索的内存计算硬件实现的构建块。
d.对于神经网络,FeD器件可以提供不同的多重导电状态的可编程性,且与电脉冲的数量有高度的线性关系。这允许映射矩阵乘法运算(神经网络计算的一个关键核心),通过将输入向量编码为模拟电压幅值,并将矩阵元素编码为一组FeD装置的电导,读取FeD装置每位线上的累积电流。
45nm AlScN薄膜的铁电响应通过在半径为25μm的圆形金属/铁电/金属电容上进行正上,负下(PUND)测量来表征,使用的方波延迟为2μs,脉冲宽度为400 ns(补充图S11)。PUND测试优于偏振-电场迟滞回线(P-E回线)测量,因为45 nm AlScN的P-E回线显示出偏振依赖的漏电,这妨碍了对将材料切换到金属-极性态的正应用场的极化饱和的观测。PUND结果显示,残余极化约为150 μ C/cm²,如图2c所示,与之前的观察结果一致。为了进一步验证铁电开关,进行了动态电流响应,观察到铁电开关对应的峰值(补充图S12)。为了进一步表征记忆效应和可靠性,我们在正极化和负极化状态之间进行了耐力测试,如图2d所示。图2d显示了从20,000个PUND循环中提取的剩余正负极化。同一AlScNFeD装置的循环设置/重置操作表明,正负极化状态都是稳定的,并且在相当数量的循环内都是可重写的。如图2e所示,我们通过对顶部电极施加负/正电压,同时对底部电极接地,在低电阻状态(LRS)和高电阻状态(HRS)之间反复设置/重置FeD装置,使用准直流电压扫描,循环100次。FeD器件显示超低工作电流和自整流行为,在9v到0v之间具有非线性> 106,这有助于抑制隐藏电流,而不需要额外的接入晶体管或选择器。LRS和HRS电阻的分布如图2f所示,显示了LRS和HRS之间的比值在周期与周期变化上的紧密分布。
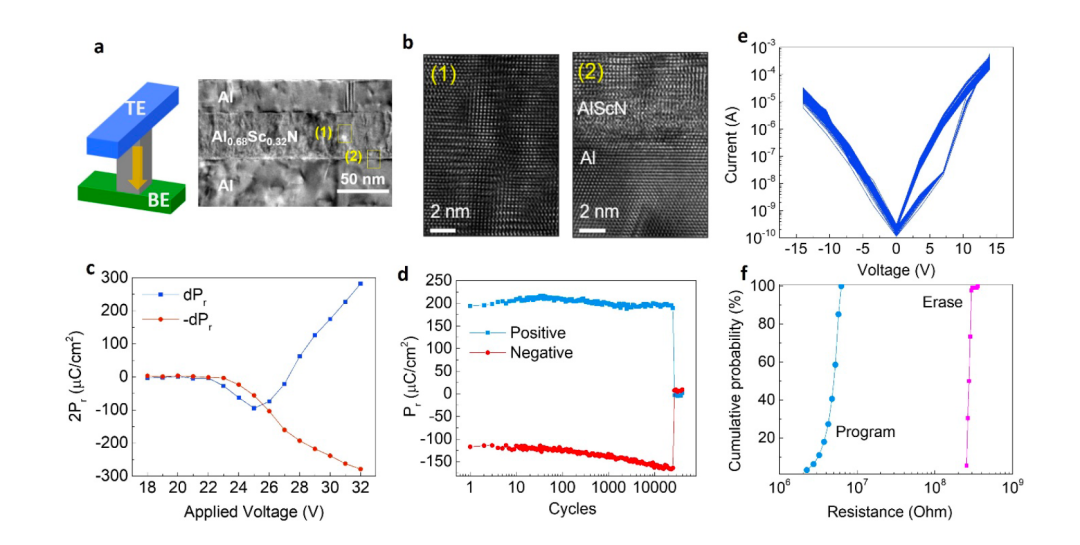
图2所示。AlScN/MoS2 fe - fet的室温电性表征。
a, AlScN FeD器件的3D示意图和AlScN FeD的截面TEM图像,显示45nm AlScN为铁电开关层。
b,在(a)中所示区域(1)和(2)获得的铁电体和界面原子结构可见的高分辨率相位对比TEM图像。
c,脉冲宽度为400ns,脉冲间延迟为2μs的45nm AlScN薄膜的PUN结果。PUND测试显示饱和剩余极化为150μC/cm²。
d,利用1.5μs脉冲宽度和26 V振幅对AlScN薄膜进行持久测试时的PUND测量提取的剩余极化值。
e,在基于45纳米 AlScN的FEDs上进行100个周期的程序和擦除测量。
f, e中程序和擦除测量过程中HRS和LRS电阻的分布。
2-FeD TCAM单元用于搜索
接下来,我们关注CIM电路架构和计算应用程序,包括上述作为非易失性存储器的FeDs。我们首先演示一个使用FeDs的TCAM实现。TCAM是大数据应用中快速高效并行搜索CIM硬件实现的关键构件。TCAM通过并行比较输入数据与存储在内存数组中的数据来执行搜索功能,并在检测到匹配时返回数据地址。这种并行搜索允许TCAM在一个时钟周期内执行查找表功能。与存储“0”或“1”位值的二进制内容寻址存储单元不同,TCAM单元可以存储额外的“X”(“不在乎”)位,这将导致匹配状态,而不管输入的搜索数据是什么,并使TCAM在搜索应用程序中更加强大。然而,在传统的Si CMOS结构中,需要多个晶体管(~16)来构建一个具有静态随机访问存储器(SRAM)的TCAM单元(图3a)。由于晶体管的充放电和互连寄生电容,这种配置导致了大的占地面积和高功耗。这限制了该配置在高速、大规模和功率受限系统中的使用。非易失性存储器(NVM)是实现TCAM的有前途的替代方案,因为它们更节约占地面积和更节能。这是因为它们在更紧凑的体系结构中形成了一个单独的TCAM单元,并且即使电源被切断,它们也保留了存储的信息。基于电阻性随机存取存储器(RRAMs)的TCAM、磁隧道结(MTJ) RAM、浮栅晶体管存储器(FLASH)和相变存储器(PCMs)已经被证实。然而,所有这些架构仍然构建在线前端晶体管之上,没有一个完全兼容BEOL。
在这项工作中,TCAM的单元结构可以通过仅使用两个FeDs而显著简化,由于FeDs具有很大的非线性,因此不需要加入晶体管(图3a)。图3b演示了单个FeD TCAM电池的工作。电池结构使利用FeD crossbar存储器阵列变得很自然,其中连接到阳极和阴极的信号线在TCAM演示的位搜索中并行,如补充图S3所示。首先,我们讨论了基于FeDs的TCAM如何存储和搜索“0”或“1”位(图3b)。在单元操作过程中,首先将互补状态写入两个FeDs,如果搜索数据在搜索线(SL和非SL)上有偏差,与存储的信息匹配,匹配线(ML)保持高;否则,ML被下拉。正如我们在超真空中所展示的,FeD设备具有高度的自整流能力,并能维持较高的开/关比。因此,只有当FeD被编程为低电阻状态且读电压高于FeD的打开电压时,ML上才会发生放电。
如图3b所示,我们将逻辑“1”状态写入到FeD TCAM单元中,分别将左/右FeD设置为低阻/高阻状态。在搜索操作中,匹配线被一个读电压VS所偏置,它高于FeD的启动电压。接下来,我们通过分别对左/右FeD施加高/低电压来搜索逻辑“1”,并通过分别对左/右FeD施加低/高来搜索逻辑“0”。在这种情况下,“高压”指的是读电压VS,它高于FeD的打开电压,但低于写电压。相反,“低电压”指的是接近零的读电压,远低于FeD的打开电压。由于左FeD与右FeD平行,只有当单元中的两个FeD都被截断时,才会观察到匹配状态(图3b,左面板)。根据这些写入和搜索方案,当存储数据和搜索数据匹配时(如图3b左面板所示,存储位为逻辑' 1 ',搜索位为逻辑' 1 '),低电阻为0的FeD器被关闭,因为它的阳极和阴极之间的压降接近于零,低于它的打开电压。此外,高阻状态下的FeD也是截止的,因为电流在高阻状态下通过FeD时自然是低的。因此,在两个通道的放电电流都是最小的,ML保持较高。但是,当搜索数据与存储数据不匹配时,即使处于高阻状态的右侧FeD仍然被切断,但左侧FeD没有被切断。左FeD低阻通电时,其正极和阴极之间的压降为VS,且高于其接通电压的值为0。因此,放电电流显著,ML电压较低(图3b,中面板)。我们还演示了两个基于美联储的TCAM中的三元“不在乎”状态。如图3b的右面板所示,通过将左右两个FeD设置为高电阻状态,我们将逻辑“不在乎”状态写入FeD TCAM单元。使用上面的写方案和逻辑“1”和“0”相同的搜索方案,无论什么信号到达两个FeDs,这两个FeDs总是被切断,因为它们处于高电阻状态。图3c显示了在搜索数据和存储数据位' 1 '之间的匹配和不匹配状态下,使用7 V的中等搜索电压对两个基于FeD的TCAM单元的电阻进行重复准直流读取。图3d显示了使用查询位“1”和“0”对存储数据位“Don’t care”的两个FeD TCAM单元电阻的重复准直流读取。这表明,对于这两个查询,两个基于FeDs的TCAM的ML阻力仍然很高,因此没有通过任何两个FeDs进行放电。因此,带有两个FeDs的TCAM单元在所有三种状态下都能完全工作。两种基于FeD的TCAM单元的完整查找表汇总在补充表中。
传统的双端忆阻器通常与前端晶体管配对构成TCAM单元。这是因为晶体管需要切断通道,因为它们与双端nvm串联在一起。基于FeD的设计得益于高自整流比,无需任何晶体管就能切断通道。换句话说,FeD将晶体管的功能抽象为自身的自整流行为。没有晶体管导致更小的电池足迹和面积效率,并提高了基于美联储的TCAM的搜索速度。通过SPICE模拟,我们验证了基于FeD的TCAM中的搜索延迟与之前基于2晶体管2电阻(2T-2R)的TCAM体系结构相比有所降低。图3e显示了各种TCAM单元横向足迹与搜索延迟的基准对比图。我们的两个基于FeD的超CMOS SRAM TCAM和其他基于晶体管+ NVM设备的架构的卓越性能是显而易见的。
基于FeDs的TCAM的感知度是自整流比和ON/OFF电导(或电流)比的函数。根据我们详细的紧凑模型(见补充注释1),通过在FeD层顶部集成一个非铁电绝缘体,并对这些铁电绝缘体和非铁电绝缘体层之间的厚度比以及铁电层的矫顽场进行工程设计,可以进一步提高FeD的开/关比。未来的研究将专注于通过设计这些变量来进一步提高感知边缘。
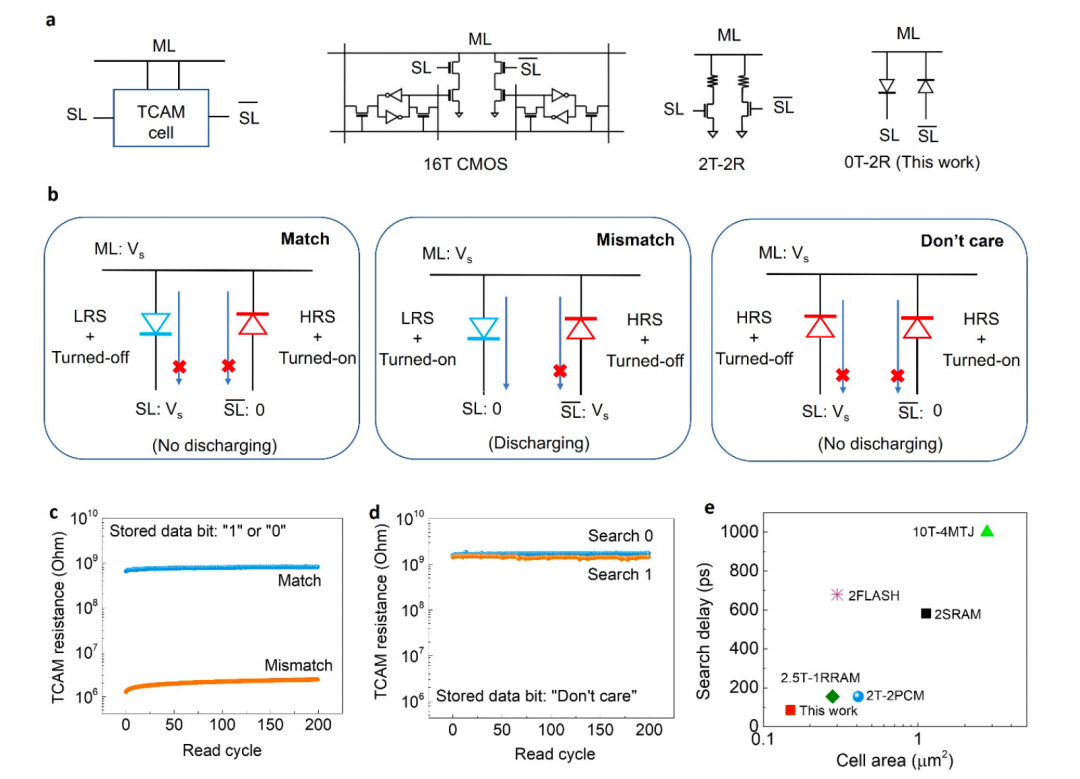
图3。2-FeD TCAM单元用于搜索操作
a,带有匹配线(ML)、搜索线(SL)和搜索线(SL条)电极(左)的TCAM单元的方框示意图。基于CMOS voltle静态随机存取存储器(SRAM)技术的单16晶体管(16T) TCAM电池电路图,以及基于PCM和RRAM等电阻性存储元件的2晶体管2电阻(2T2R) TCAM电路。(中间)。本工作中提出的两个基于二铁二极体的TCAM电池(右)通过使用两个平行但极性相反的FeDs连接显著简化了TCAM设计。
b.由2个federal组成的单个TCAM单元对“匹配”、“不匹配”和“不在乎”状态的操作。
c,对于搜索数据和存储数据位' 1 '之间的匹配和不匹配状态,重复准直流读取两个FeDs TCAM单元的电阻,显示在ML电阻上有>100 X的差异。
d,使用查询位“1”和“0”重复准dc读取存储数据位“Don’t care”的两个铁二极管TCAM单元的电阻,结果表明,对于两个查询,两个FeDs TCAM的ML电阻都很高,因此没有通过两个FeDs中的任何一个放电。
e,各种存储技术中TCAM细胞横向足迹与搜索延迟的基准对比图。这个估计假设单一FeD面积为0.0081μm2。
神经网络
接下来,我们将关注我们的FeD设备阵列在深度神经网络(DNN)推理中的应用,这涉及到重复矩阵乘法/累积(MMAC)操作。MMAC操作和DNN通常在软件级别实现。然而,它们的软件实现使得在电力和资源受限的设备或环境中部署它们特别具有挑战性。同样,这在很大程度上是由于传统的冯诺依曼计算硬件方法,它在内存访问方面是密集的,很难并行化。在模拟域进行MMAC操作提供了一种有前途的替代方案:具有模拟导管的忆阻器已被证明是执行MMAC操作的优越硬件介质。通过利用基尔霍夫电流定律(KCL)的高并行性,MMAC操作可以显著减少到读取单个时钟在忆阻器的每个位线上的累积电流。这是通过将输入矢量编码到模拟电压幅值和将矩阵元素编码到忆阻器阵列的电导来实现的。
理想的适合MMAC的忆性器件应该在电气编程中实现线性排列的电导值,电流对驱动电压的线性依赖,以及抑制电流量的高电阻。该领域的先前研究主要集中在具有优异欧姆性能和大量电导状态的记忆器件上,如RRAM和PCM。在DNN推理精度的背景下,电流和电压之间的线性关系是最小化输入基准失真的必要条件,大量的电导将使权矩阵上的精度损失最小化,这对于执行高度精确的推理任务是必不可少的。然而,从功率和面积效率的角度来看,一个优秀的欧姆行为和大量的电导状态将损害结构指标的功率效率和每次计算的低延迟。这有几个原因。首先,具有优异欧姆性能的忆性器件以高器件导电性为代价,这意味着高工作电流限制了阵列的缩放。其次,大量的电导将相应地需要高精度的模数转换器(adc)。从先前的工作中我们已经知道,在忆阻阵列系统中,电路级别上的adc支配着能量和面积成本。因此,更多的电导状态意味着在DNN推理引擎的架构级别上更多的功率开销。因此,DNN推理的准确性与功率和面积效率之间存在明显的权衡。在这里,我们展示了FeD忆阻器可以用于执行这些指标之间的最佳权衡。首先,为了实现器件导电性的权衡,重要的是在保持线性行为的同时降低记忆器件的操作导电性。前一个条件对于高度自整流的设备来说很容易满足,这是联邦储备银行的固有属性;后一个条件可以通过在输入电压振幅上应用编码器来线性化电流-电压关系(见补充注2)来满足。第二,为了放松电导状态数量上的权衡,需要少量但稀疏且线性排列的电导状态。与实现大量电导状态的方法相比,这种方法可以获得等效的推理精度。
图4a显示了通过逐步电压脉冲调制的FeD系统的逐步切换。使用逐步电压脉冲,FeD电池逐渐编程成16个不同的电导状态。这些电导状态显示与编程脉冲数量的高度线性,如下所述。图(左)显示了一系列编程操作,其中逐步电压脉冲(范围从16 V到19 V)应用于FeDs的顶部电极上,然后每次都进行擦除操作。标注窗口(右)显示了一个代表性周期的电导与脉冲数的关系。图4b显示,FeD器件能够实现电压脉冲诱导模拟双极开关(范围从16v到19v,左)。标注窗口(右)显示了一个逐步编程和逐步擦除的循环。在双向调制中,FeD器件对16种不同的电导状态表现出优越的线性(线性拟合的R2分数为0.9997)。图4c显示了16种不同电导状态下的电导保留率,并没有显示明显的退化。图4d显示了在16个程序脉冲(脉冲宽度为2 μs),交错读取(8 V)的相同序列下,五个独立的FeD器件的电导状态分布。结果显示,这些FeD设备之间的设备间的差异可以忽略不计。我们注意到,用于编程这些状态的FeD器件的电导范围(~25-250 nS)比用于TCAM操作的电导范围(~ 2-250 nS)小得多。这主要是因为在较小的电导范围内可以更好地实现工作中的线性。此外,DNN推理应用不一定需要高范围的电导调制。我们在一个用于计算机视觉的训练卷积神经网络(CNN)的实际应用中,模拟了由这种FeD设备组成的阵列的性能。在MNIST数据集(MNIST, Modified National Institute of Standards and Technology database)上训练一个CNN(包括两个卷积层和一个全连接层),然后将预训练的权重转移到FeD电导范围。该网络的示意图如图4e所示。我们分析了由于重量转移到低精度的电导值,加上一个附加的可变因子A,这是一个非线性指标,精度下降。A因子与非线性的关系已在补充注3中详细讨论。因此,全精度训练网络的权重被量化为若干电导状态(从1位到9位不等)。然后,对网络在MNIST测试数据集上的准确性进行重新评估。卷积神经网络对于低精度的权值传递具有较低的非线性(A > 0.5)的鲁棒性,如图4f所示。图4f中,对于低精度的权值传递变化,在单精度浮动点数格式(FP32)上仅用3位的权值精度恢复了97.5%的全精度测试精度。对于较高的非线性(A <0.35), FP32上需要1 ~ 2位权精度才能恢复全精度测试精度,这说明线性排列稀疏的电导状态具有良好的线性性,可以替代大量的电导状态,实现等效推理精度。此外,我们在FeD阵列上模拟原位训练的内存实现,其中训练相同的卷积神经网络,并在每次反向传播后将权值更新直接映射到FeD的实际电导状态。如图4g所示,对于图4a中FeD器件中演示的16个独立电导状态,原位学习精度比在FP32上训练的精度下降了约2%。然而,使用更先进的低精度训练技术和软件上的模型压缩技术,我们相信这个数字可以大幅减少,允许在训练阶段执行低精度权重转移到FeD设备时几乎没有精度下降。
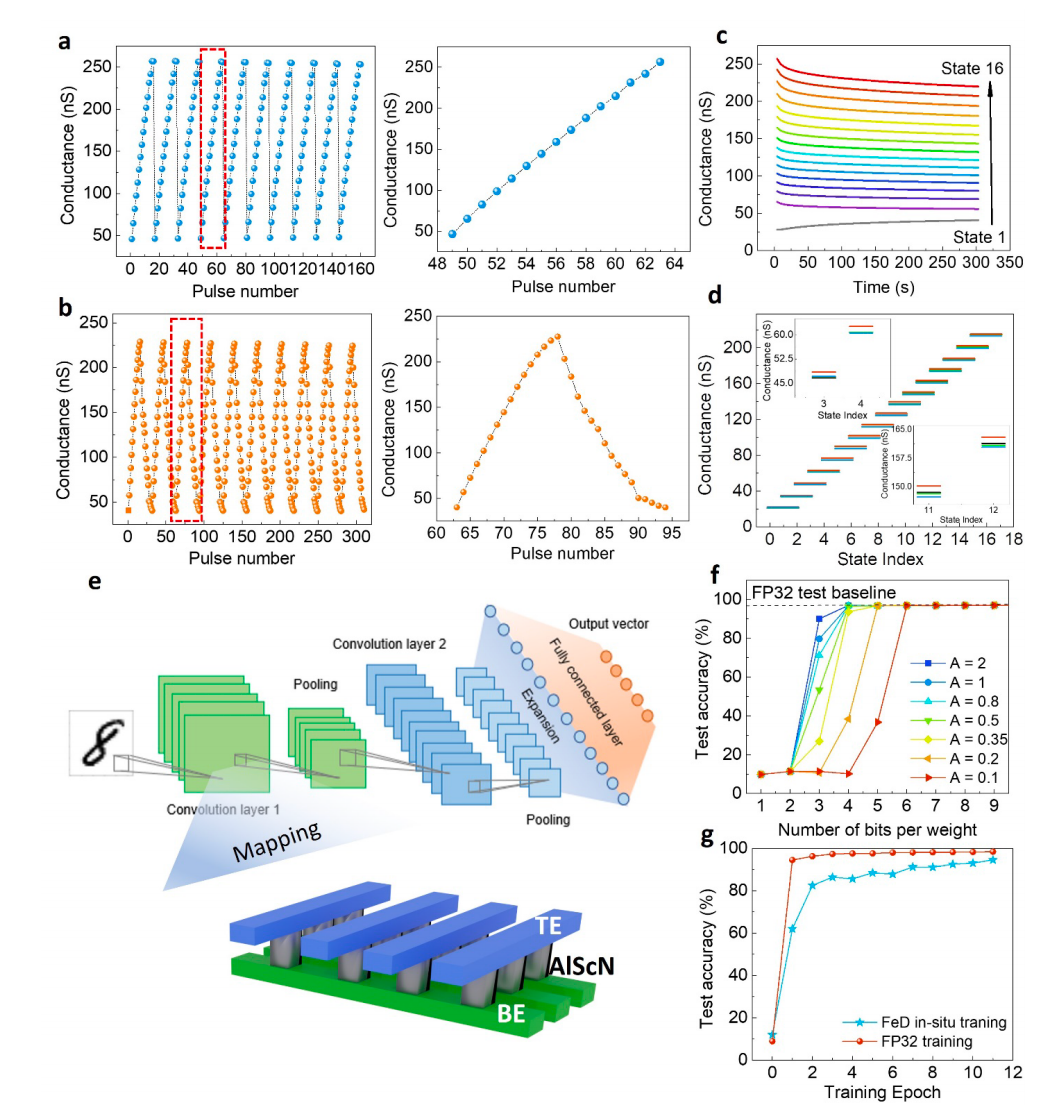
图4。FeD-based神经网络。
a,通过逐步电压调制脉冲在铁二极管(FeD)中逐步开关。使用逐步电压脉冲将FeD电池逐步编程成各种电导状态。左面板显示了一系列编程操作,其中逐步电压脉冲偏向于联邦电极上的顶部电极,每次都跟着一个擦除操作。标注窗口(右面板)显示一个代表性周期的电导与脉冲数的关系。
b, FeD被证明能够进行电压脉冲诱导模拟双极开关(左)。标注窗口(右)显示了一个逐步编程和逐步擦除的循环。在16个不同的状态下,FeD器件显示了优越的线性。
c, 16个不同电阻状态的电阻保留率。
d,受16个程序脉冲(2 μs脉冲宽度)序列和交错读取(8 V)的影响,五个独立的FeDs的电阻状态分布。
e,为MNIST数据集训练的CNN的插图。使用铁二极管阵列进行矩阵乘法的神经网络硬件实现可以在完全模拟模式下运行,而无需外围的模数转换器。
f.仿真包括实现模拟权层的FeD设备,以及在MNIST上训练的带有FP32计算的网络的不准确权映射。(f)中的模拟表明,当A < 0.5时权重精度仅为3位时,网络推理精度的退化小于1%。
g,直接使用实现模拟权层的FeD设备对(e)中的网络进行原位训练的模拟。利用fbi渐进编程中的优越线性,模拟权值层具有16个电阻状态,其推理精度可与FP32计算基线相媲美。
结论
总之,我们证明了基于AlScN的ferrodiode(铁二极管器件)是一种新颖的、BEOL兼容的无晶体管架构多功能CIM平台。我们通过一个TCAM电路实现了搜索功能的实验演示,该电路具有横向单元足迹和搜索延迟,优于所有现有和实验NVM技术。最后,我们演示了一种稳定的、脉冲可编程的4位存储器,来自ferrodiode,结合卷积神经网络的硬件实现,其推理精度可与软件相媲美。因此,我们的工作通过使新型ferroelectric和使用它们制造的二极管器件成为可能,为CIM平台打开了新的可能性。
番外
FeD设备制造的方法
FeD由Si/Al0.8Sc0.2N (85 nm)衬底上的Al (80 nm)/Al0.68Sc0.32N (45 nm)/Al (30 nm) 的薄膜堆栈组成。为了准备这个堆栈,我们首先溅射沉积一层85纳米厚的Al0.8Sc0.2N模板在6英寸Si <100>晶圆的顶部。采用脉冲-直流无功溅射沉积单合金Al0.8Sc0.2N靶材料,靶功率为5 kW,压力为7.47x10-3 mbar,沉积温度为375℃,在N2气氛中沉积了Al0.8Sc0.2N。第一层85 nm的Al0.8Sc0.2N将随后80 nm厚的Al层定向为{111}取向。这一层Al (80 nm厚)作为第二层Al0.68Sc0.32N(45 nm厚)的底部电极,这是本器件使用的铁电层。在Evatec CLUSTERLINE200 II脉冲直流物理气相沉积系统中,45nm厚的铁电Al0.68Sc0.32N薄膜从单独的4英寸Al和Sc目标共溅射。Al和Sc靶分别在1250 W和695 W下工作,卡盘温度350℃,Ar气体流量10 sccm和N2气体流量25 sccm。腔室压力维持在~1.45x10-3 mbar。这种溅射条件导致沉积速率为0.3 nm/秒。高取向{111}Al层促进了AlScN的生长,其[0001]轴方向垂直于衬底,因此,产生了高纹理的FE薄膜。在不破真空的情况下,溅射出一层30 nm的Al层作为顶电极和盖层,防止铁电Al0.68Sc0.32N的氧化。
设备特征
使用Keithley 4200A半导体表征系统在环境温度下的空气中进行电流电压测量。利用Keithley 4200A半导体表征系统和辐射精度Premier II测试平台进行了FeD AlScN的P-E迟滞回线和PUND测量。在FEI Helios Nanolab 600聚焦离子束(FIB)系统中,采用原位提升技术制备TEM横截面样品。样品被涂上薄薄的碳质保护层,用记号笔在表面写上一条线。随后使用电子束和离子束沉积铂保护层,以防止FIB铣削过程中的电荷和加热效应。在最后的清洗阶段,低能的Ga+离子束(5 keV)用于减少fib诱导的损伤。在200kv加速电压下运行的JEOL F200上进行了TEM表征和图像采集。样品定向于[001]区轴进行成像。所有捕获的TEM图像都是使用数字显微软件收集的。
审核编辑:汤梓红
-
存储器
+关注
关注
39文章
7774浏览量
172512 -
存内计算
+关注
关注
0文章
35浏览量
1684
原文标题:一种创新的存内计算架构
文章出处:【微信号:半导体科技评论,微信公众号:半导体科技评论】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究

一种基于数字改良的SRAM设计存内计算方案
什么是存内计算
开源芯片系列讲座第24期:基于SRAM存算的高效计算架构




评论