 第一个大规模点云的自监督预训练MAE算法Voxel-MAE
第一个大规模点云的自监督预训练MAE算法Voxel-MAE

作者:Chen Min, Xinli Xu, Dawei Zhao, Liang Xiao, Yiming Nie, Bin Dai
基于掩码的自监督预训练方法在图像和文本领域得到了成功的应用。但是,对于同样信息冗余的大规模点云,基于掩码的自监督预训练学习的研究还没有展开。在这篇文章中,我们提出了第一个将掩码自编码器引入大规模点云自监督预训练学习的方法:Voxel-MAE。不同于2D MAE采用RGB像素回归,3D点云数量巨大,无法直接学习每个点云的数据分布,因此Voxel-MAE将点云转成体素形式,然后进行体素内是否包含点云的二分类任务学习。这种简单但是有效的分类学习策略能使模型在体素级别上对物体形状敏感,进而提高下游任务的精度。即使掩蔽率高达90%,Voxel-MAE依然可以学习有代表性的特征,这是因为大规模点云的冗余度非常高。另外考虑点云随着距离增大变稀疏,设计了距离感知的掩码策略。2D MAE的Transformer结构无法处理大规模点云,因此Voxel-MAE利用3D稀疏卷积来构建encoder,其中position encoding同样可以只处理unmasked的体素。我们同时在无监督领域自适应任务上验证了Voxel-MAE的迁移性能。Voxel-MAE证明了对大规模点云进行基于掩码的自监督预训练学习,来提高无人车的感知性能是可行的。KITTI、nuScenes、Waymo数据集上,SECOND、CenterPoint和PV-RCNN上的充分的实验证明Voxel-MAE在大规模点云上的自监督预训练性能。
Voxel-MAE是第一个大规模点云的自监督掩码自编码器预训练方法。
不同于MAE中,Voxel-MAE为大规模点云设计了适合的体素二分类任务、距离感知的掩码策略和3D稀疏卷积构建的encoder等。
Voxel-MAE的自监督掩码自编码器预训练模型有效提升了SECOND、CenterPoint和PV-RCNN等算法在KITTI、nuScenes、Waymo数据集上的性能。
Voxel-MAE同时在无监督领域自适应3D目标检测任务上验证了迁移性能。
算法流程
![]()
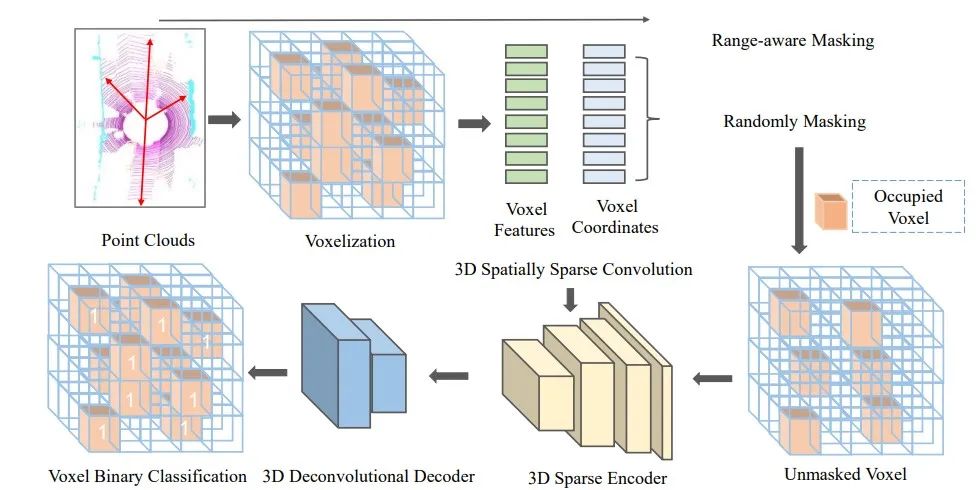
图1 Voxel-MAE的整体框图:首先将大规模点云转成体素表示,然后采用距离感知的掩码策略对体素进行mask,再将unmasked的体素送入不对称的encoder-decoder网络,重建体素。最后,采用判断体素内是否包含点云的二分类交叉熵损失函数端到端训练整个网络。Encoder采用三维稀疏卷积网络构建,Decoder采用三维反卷积实现。
Range-aware Masking
遵循常见的3D点云目标检测的设置,我们将WXHXD范围内的大规模点云沿着XYZ方向分成大小为VWXVHXVD的体素。所有体素的个数为nl,包含点云的体素个数为nv。
不同于2D图像,3D点云的分布随着离激光雷达的距离增加越来越稀疏。因此不能对不同位置的点云采用相同的掩码策略。
对此我们设计了距离感知的掩码策略。即对近处稠密的点云masking多,对远处稀疏的点云masking少。具体我们将点云分成30米以内,30-50米,50米以外,然后分别采用r1,r2和r3三种掩码率来对点云体素进行随机掩蔽,其中r1》r2》r3。剩余的unmasked的体素个数为nun。对于所有包含点云的体素nl,我们将其点云体素分类目标设为1,其他设为0。
3D Sparse Convolutional Encoder
MAE论文中采用Transformer网络架构对训练集中的unmasked部分进行自注意力机制学习,不会被masked部分影响。但是由于unmasked的点云数量仍然很大,几十万级别,Transformer网络无法处理如此大规模unmasked的点云数据。研究者通常采用3D SparseConvolutions来处理大规模稀疏3D点云。因此不同于2D MAE,Voxel-MAE采用3D SparseConvolutions来构建MAE中的encoder,其采用positional encoding来只对unmasked的体素聚合信息,从而类似MAE中的Transformer结构,可以降低训练模型的计算复杂度。
3D Deconvolutional Decoder
Voxel-MAE采用3D反卷积构建decoder。最后一层输出每个体素包含点云的概率。decoder网络简单,只用于训练过程。
Voxel-MAE的encoder和decoder的结构如下:

Reconstruction Target
2D MAE中采用masked部分的RGB像素回归作为掩码自编码器自监督学习的目标,但是3D点云的数量很大,回归点云需要学习每个点云的数据分布,是难以学习的。
对于3D点云的体素表示,体素内是否包含点云非常重要。因此我们为Voxel-MAE设计了体素是否包含点云的二分类任务。目标是恢复masked的体素的位置信息。虽然分类任务很简单,但是可以学习到大规模点云的数据分布信息,从而提高预训练模型的性能。
实验结果
![]()
采用OpenPCDet算法基准库,在KITTI、nuScenes、Waymo数据集上进行了实验验证。
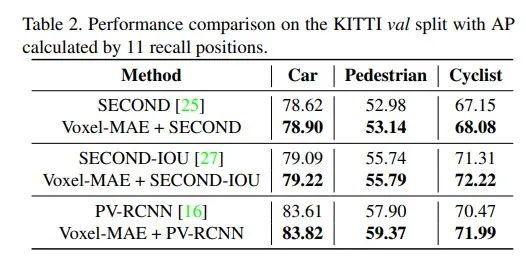
1.KITTI
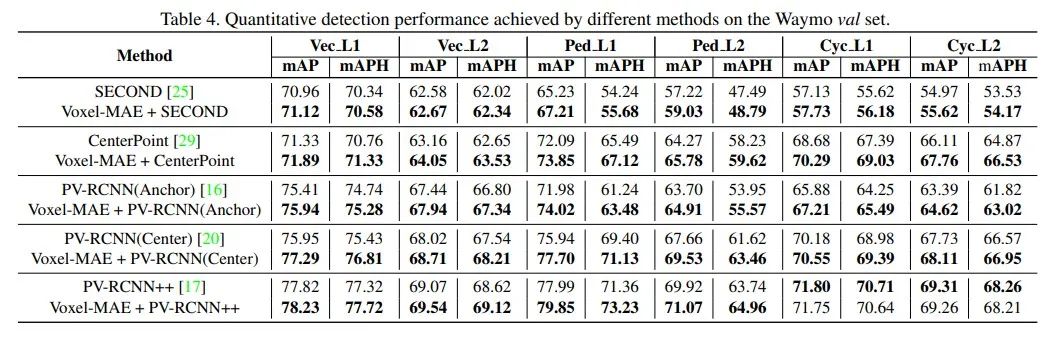
2. Waymo
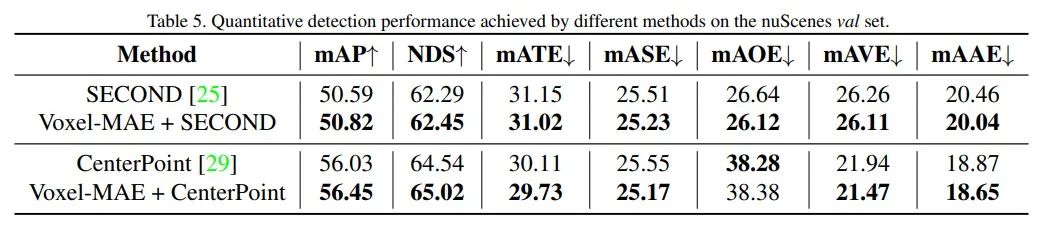
3. nuScenes
4. 3D点云无监督领域自适应任务验证迁移性能
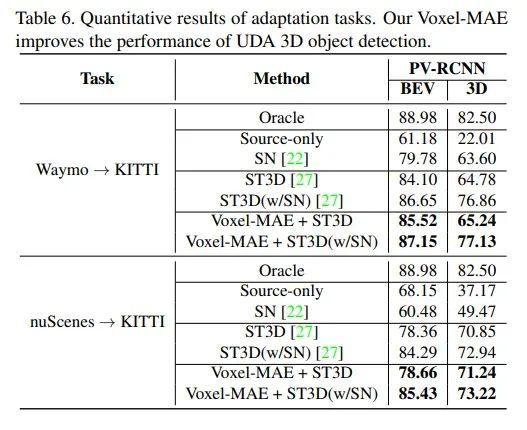
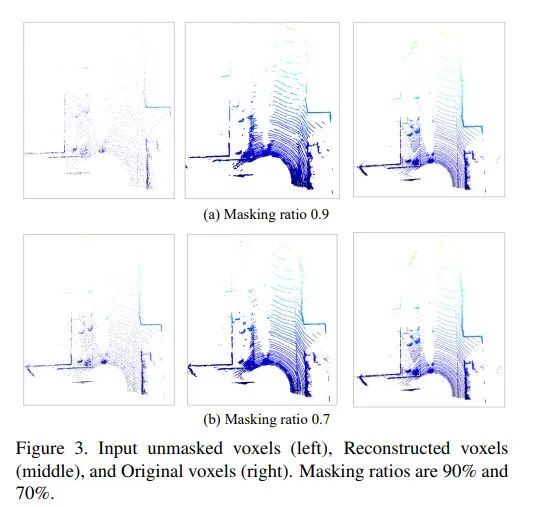
5. 3D点云重建可视化图
审核编辑:郭婷
-
编码器
+关注
关注
45文章
3903浏览量
141397 -
激光雷达
+关注
关注
977文章
4377浏览量
195324 -
数据集
+关注
关注
4文章
1230浏览量
26036
原文标题:Voxel-MAE: 第一个大规模点云的自监督预训练MAE算法
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
一个大规模电路是怎么设计出来的???
AU1200 MAE驱动程序的开发流程是什么?
神经网络在训练时常用的一些损失函数介绍
AU 1200 MAE驱动程序开发流程

一种基于点云的Voxel(三维体素)特征的深度学习方法

用于弱监督大规模点云语义分割的混合对比正则化框架
PyTorch教程11.9之使用Transformer进行大规模预训练

基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?

NeurIPS 2023 | 全新的自监督视觉预训练代理任务:DropPos






 工商网监
工商网监
评论