 NVIDIA AI平台为大型语言模型带来巨大收益
NVIDIA AI平台为大型语言模型带来巨大收益

随着大型语言模型( LLM )的规模和复杂性不断增长, NVIDIA 今天宣布更新 NeMo Megatron 框架,提供高达 30% 的训练速度。
这些更新包括两种开拓性技术和一个超参数工具,用于优化和扩展任何数量 GPU 上的 LLM 训练,提供了使用 NVIDIA AI 平台训练和部署模型的新功能。
BLOOM ,世界上最大的开放科学、开放获取多语言模型,具有 1760 亿个参数,最近 在 NVIDIA AI 平台上接受培训 ,支持 46 种语言和 13 种编程语言的文本生成。 NVIDIA AI 平台还支持最强大的 transformer 语言模型之一,具有 5300 亿个参数, Megatron-Turing NLG 模型 (MT-NLG)。
法学硕士研究进展
LLM 是当今最重要的先进技术之一,涉及数万亿个从文本中学习的参数。然而,开发它们是一个昂贵、耗时的过程,需要深入的技术专业知识、分布式基础设施和全堆栈方法。
然而,在推进实时内容生成、文本摘要、客户服务聊天机器人和对话 AI 界面的问答方面,它们的好处是巨大的。
为了推进 LLM ,人工智能社区正在继续创新工具,例如 Microsoft DeepSpeed , 巨大的人工智能 , 拥抱大科学 和 公平比例 –由 NVIDIA AI 平台提供支持,涉及 Megatron LM , 顶 ,以及其他 GPU 加速库。
这些对 NVIDIA AI 平台的新优化有助于解决整个堆栈中存在的许多难点。 NVIDIA 期待着与人工智能社区合作,继续让所有人都能使用 LLM 。
更快地构建 LLM
NeMo Megatron 的最新更新为训练 GPT-3 模型提供了 30% 的加速,模型大小从 220 亿到一万亿参数不等。现在,使用 1024 个 NVIDIA A100 GPU 只需 24 天,就可以在 1750 亿个参数模型上完成训练——在这些新版本发布之前,将得出结果的时间减少了 10 天,或约 250000 个小时的 GPU 计算。
NeMo Megatron 是一种快速、高效且易于使用的端到端集装箱化框架,用于收集数据、训练大规模模型、根据行业标准基准评估模型,以及用于推断最先进的延迟和吞吐量性能。
它使 LLM 训练和推理在广泛的 GPU 簇配置上易于重复。目前,这些功能可供早期访问客户使用 DGX 叠加视图 和 NVIDIA DGX 铸造厂 以及 Microsoft Azure 云。对其他云平台的支持将很快提供。
你可以试试这些功能 NVIDIA LaunchPad ,这是一个免费项目,提供对 NVIDIA 加速基础设施上的动手实验室目录的短期访问。
NeMo Megatron 是 NeMo 的一部分, NeMo 是一个开源框架,用于为会话人工智能、语音人工智能和生物学构建高性能和灵活的应用程序。
加速 LLM 训练的两种新技术
优化和扩展 LLM 训练的更新中包括两种新技术,即序列并行( SP )和选择性激活重新计算( SAR )。
序列并行性扩展了张量级模型并行性,注意到之前未并行的 transformer 层的区域沿序列维度是独立的。
沿着序列维度拆分这些层可以实现计算的分布,最重要的是,这些区域的激活内存可以跨张量并行设备分布。由于激活是分布式的,因此可以为向后传递保存更多激活,而不是重新计算它们。
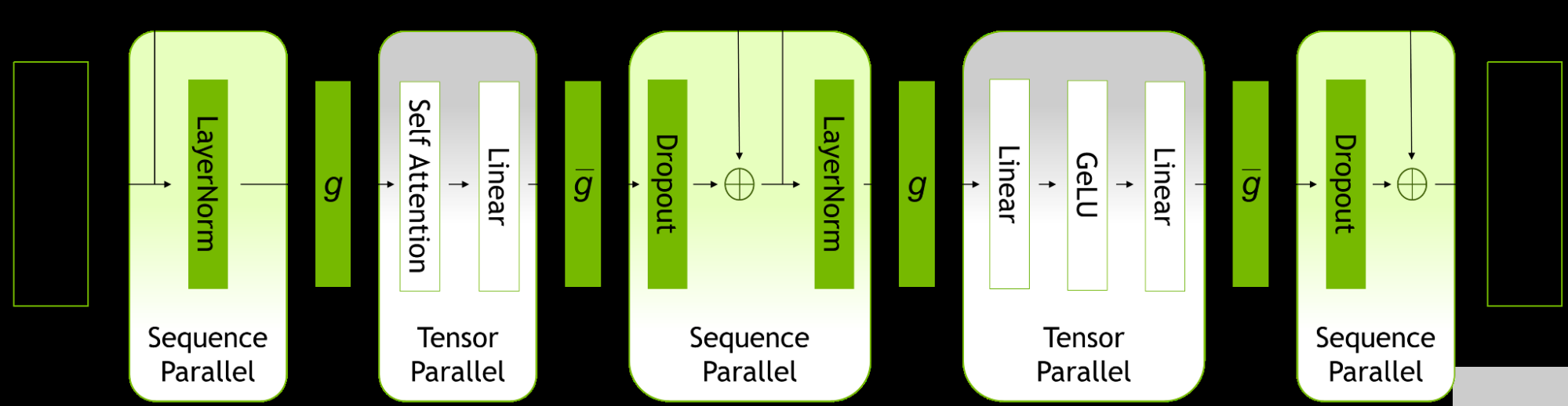
图 1.ZFK8 层内的并行模式。
选择性激活重新计算通过注意到不同的激活需要不同数量的操作来重新计算,从而改善了内存约束强制重新计算部分(但不是全部)激活的情况。
与检查点和重新计算整个 transformer 层不同,可以只检查和重新计算每个 transformer 层中占用大量内存但重新计算计算成本不高的部分。
有关更多信息,请参阅 减少大型 transformer 模型中的激活重新计算 。
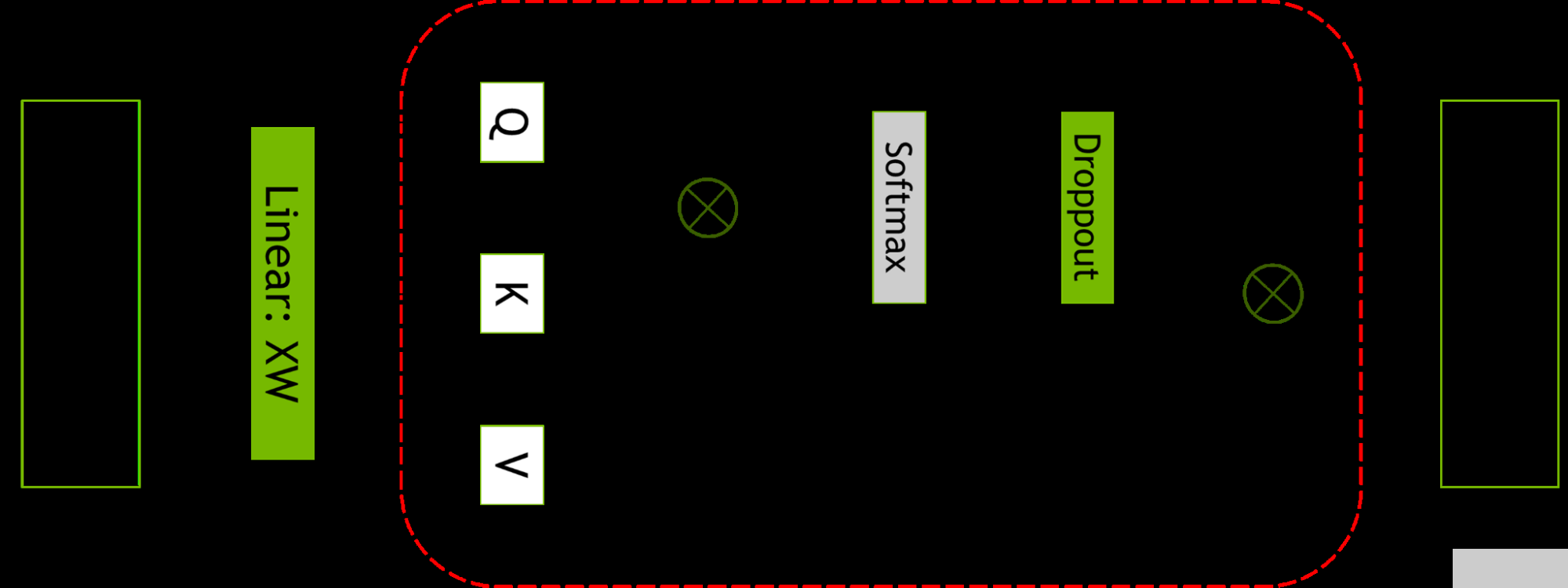
图 2.自注意力块。红色虚线显示了应用选择性激活重新计算的区域。
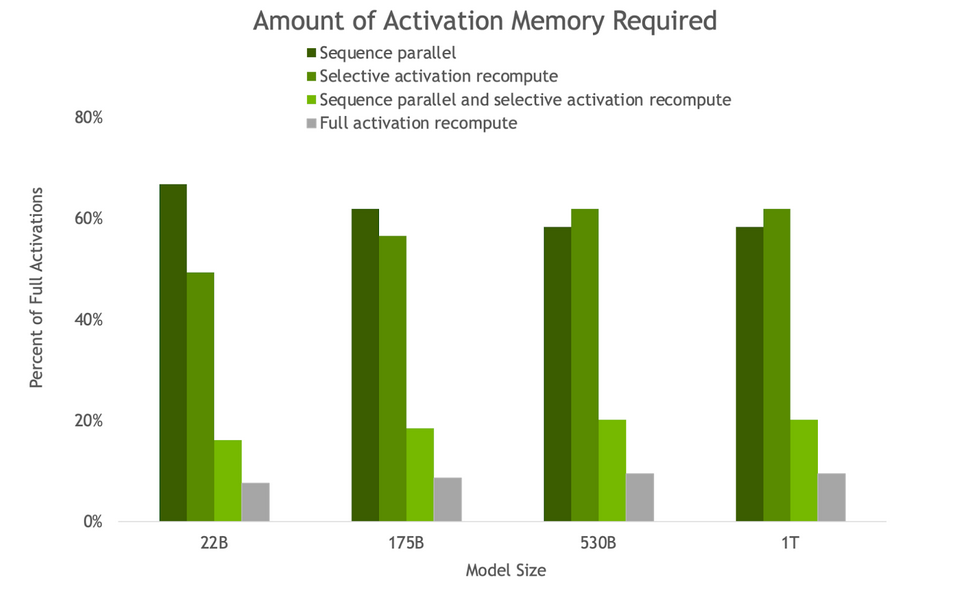
图 3.由于 SP 和 SAR ,反向传递所需的激活内存量。随着模型尺寸的增加, SP 和 SAR 的内存节省量相似,所需内存减少了约 5 倍。
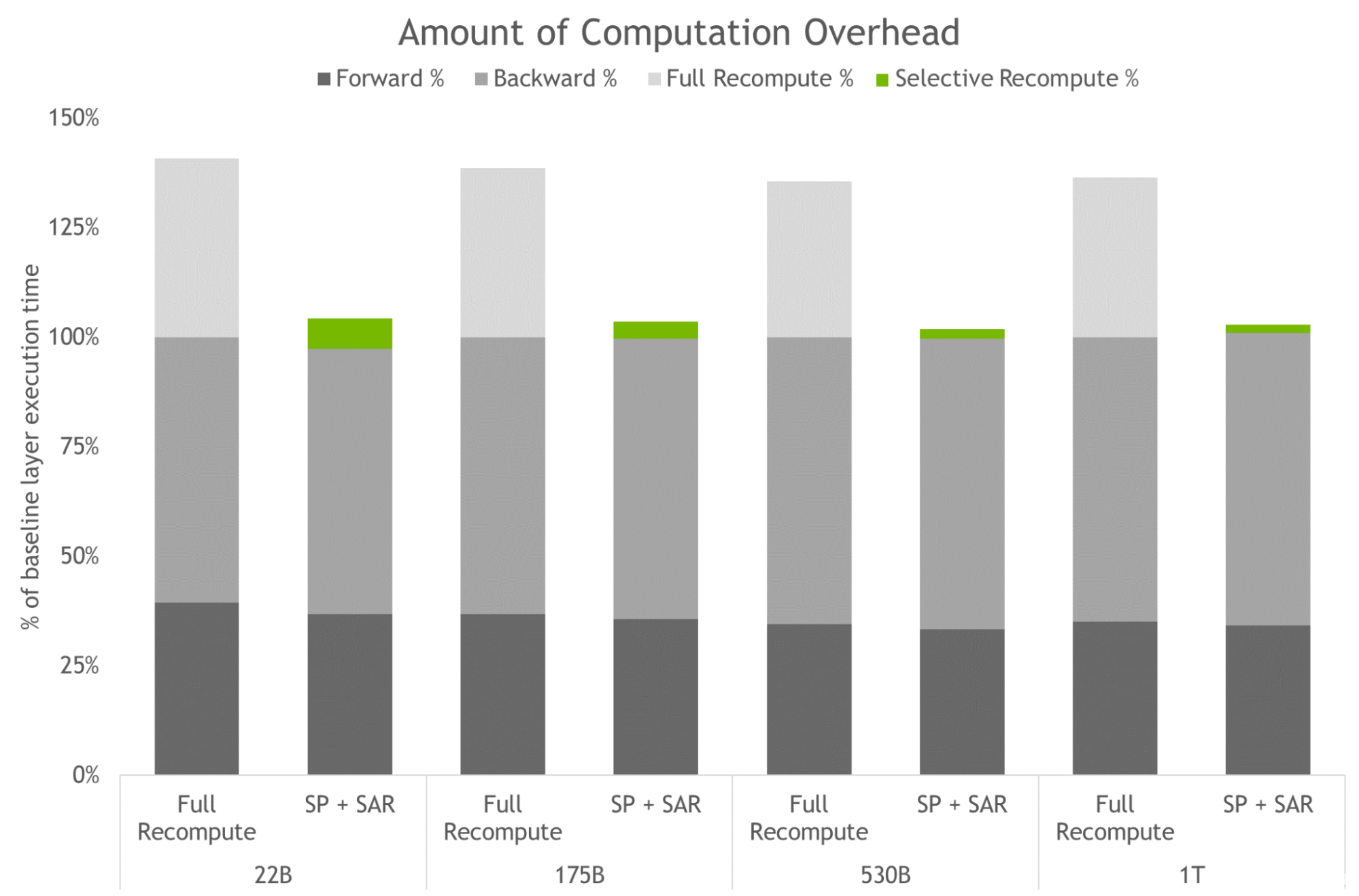
图 4.完全激活重新计算和 SP 加 SAR 的计算开销量。条形图表示向前、向后和重新计算时间的每层分解。基线是指没有重新计算和序列并行性的情况。这些技术可以有效地减少重新计算而不是保存所有激活时产生的开销。对于最大型号,开销从 36% 降至 2% 。
访问 LLM 的功能还需要高度优化的推理策略。用户可以轻松地使用经过训练的模型进行推理,并使用 p- 调优和即时调优功能针对不同的用例进行优化。
这些功能是微调的参数有效替代方案,并允许 LLM 适应新的用例,而无需对完全预训练模型进行严格的微调。在这种技术中,原始模型的参数不会改变。因此,避免了与微调模型相关的灾难性“遗忘”问题。
用于训练和推理的新超参数工具
跨分布式基础设施查找 LLM 的模型配置是一个耗时的过程。 NeMo Megatron 引入了一种超参数工具,可以自动找到最佳的训练和推理配置,无需更改代码。这使得 LLM 能够从第一天开始训练收敛以进行推理,从而消除了搜索有效模型配置所浪费的时间。
它跨不同参数使用启发式和经验网格搜索,以找到具有最佳吞吐量的配置:数据并行性、张量并行性、管道并行性、序列并行性、微批量大小和激活检查点层的数量(包括选择性激活重新计算)。
使用超参数工具和 NVIDIA 对 NGC 上的容器进行测试,我们在 24 小时内获得了 175B GPT-3 模型的最佳训练配置(见图 5 )。与使用完全激活重新计算的常见配置相比,我们实现了 20%-30% 的吞吐量加速。使用最新技术,对于参数超过 20B 的模型,我们实现了额外 10%-20% 的吞吐量加速。
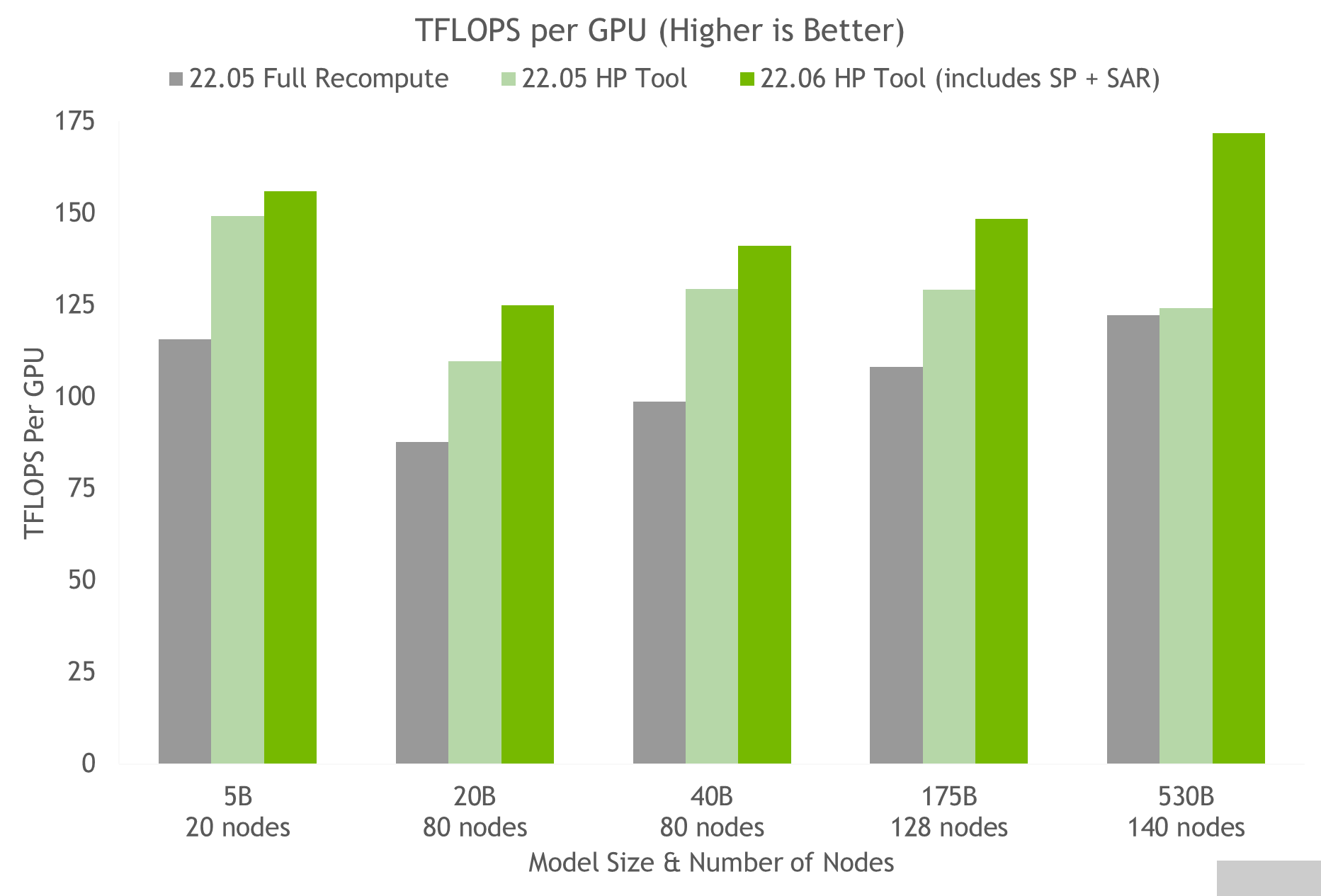
图 5.HP 工具在多个容器上的结果,表明序列并行和选择性激活重新计算的速度加快,其中每个节点是一个 NVIDIA DGX A100 。
hyperparameter 工具还允许查找在推理过程中实现最高吞吐量或最低延迟的模型配置。可以提供延迟和吞吐量约束来为模型服务,该工具将推荐合适的配置。
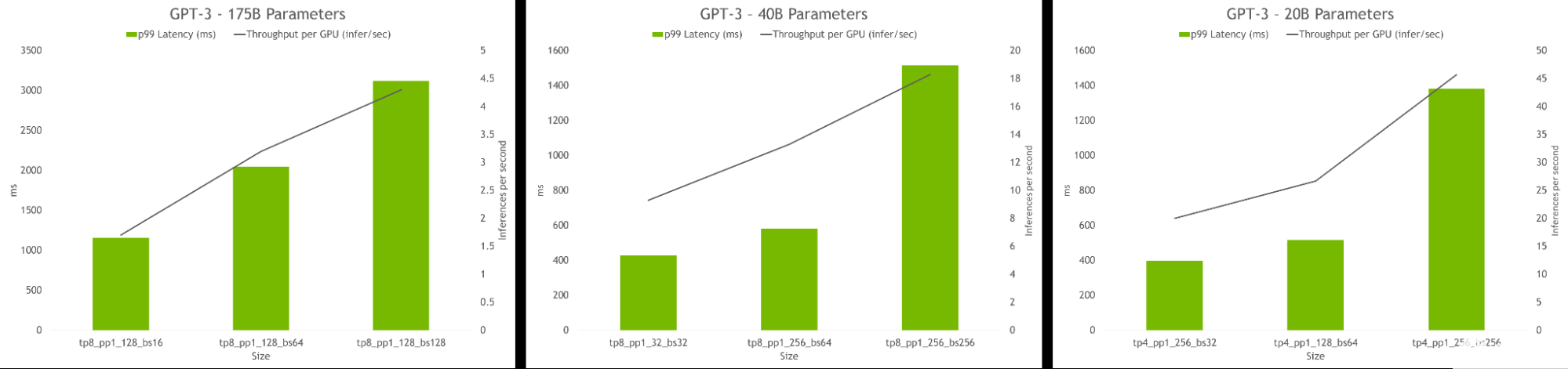
图 6.HP 工具推断结果,显示了每 GPU 的吞吐量和不同配置的延迟。最佳配置包括高吞吐量和低延迟。
关于作者
Markel Ausin 是 NVIDIA 的深度学习算法工程师。在目前的角色中,他致力于构建和部署大型语言模型,作为 NeMo- Megatron 框架的一部分。
Vinh Nguyen 是一位深度学习的工程师和数据科学家,发表了 50 多篇科学文章,引文超过 2500 篇。
Annamalai Chockalingam 是 NVIDIA 的 NeMo Megatron 和 NeMo NLP 产品的产品营销经理。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5696浏览量
110125 -
AI
+关注
关注
91文章
41250浏览量
302656 -
深度学习
+关注
关注
73文章
5609浏览量
124644
发布评论请先 登录
解读大型语言模型的偏见

NVIDIA 扩展开放模型系列,推动代理式、物理和医疗 AI 下一阶段发展

NVIDIA Jetson模型赋能AI在边缘端落地

NVIDIA推出代理式AI蓝图与电信推理模型
NVIDIA携手Mistral AI发布全新开源大语言模型系列
NVIDIA推动面向数字与物理AI的开源模型发展
利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
NVIDIA DGX Spark助力构建自己的AI模型




评论