 ClickHouse与esProc SPL性能对比
ClickHouse与esProc SPL性能对比

开源分析数据库 ClickHouse 以快著称,真的如此吗?我们通过对比测试来验证一下。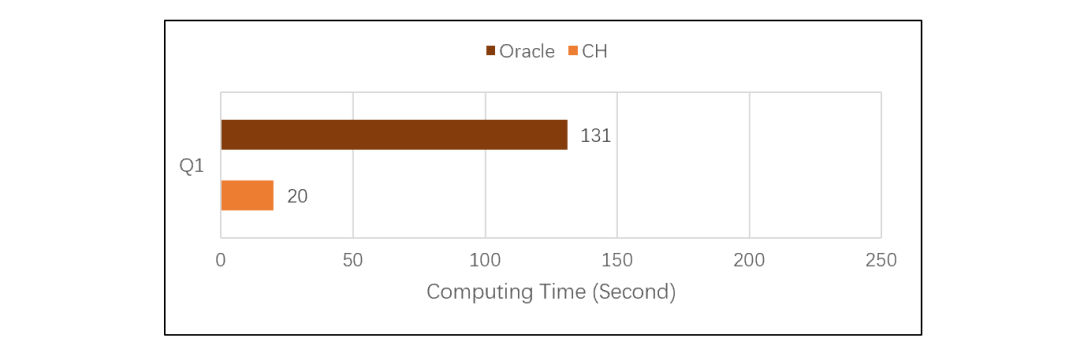 CH 计算 Q1 的表现要好于 ORA,说明 CH 的列式存储做得不错,单表遍历速度很快。而 ORA 主要吃亏在使用了行式存储,明显要慢得多了。但是,如果我们加大计算复杂度,CH 的表现怎么样呢?继续看 TPC-H 的 Q2、Q3、Q7,测试结果如下:
CH 计算 Q1 的表现要好于 ORA,说明 CH 的列式存储做得不错,单表遍历速度很快。而 ORA 主要吃亏在使用了行式存储,明显要慢得多了。但是,如果我们加大计算复杂度,CH 的表现怎么样呢?继续看 TPC-H 的 Q2、Q3、Q7,测试结果如下: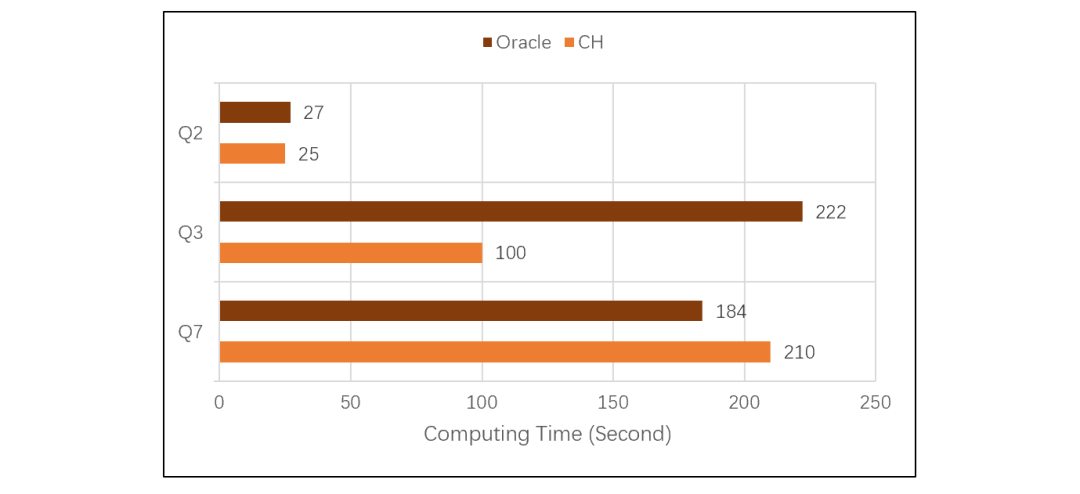 计算变得复杂之后,CH 性能出现了明显的下降。Q2 涉及数据量较少,列存作用不大,CH 性能和 ORA 几乎一样。Q3 数据量较大,CH 占了列存的便宜后超过了 ORA。Q7 数据也较大,但是计算复杂,CH 性能还不如 ORA。做复杂计算快不快,主要看性能优化引擎做的好不好。CH 的列存占据了巨大的存储优势,但竟然被 ORA 用行式存储赶上,这说明 CH 的算法优化能力远不如 ORA。TPC-H 的 Q8 是更复杂一些的计算,子查询中有多表连接,CH 跑了 2000 多秒还没有出结果,应该是卡死了,ORA 跑了 192 秒。Q9 在 Q8 的子查询中增加了 like,CH 直接报内存不足的错误了,ORA 跑了 234 秒。其它还有些复杂运算是 CH 跑不出来的,就没法做个总体比较了。CH 和 ORA 都基于 SQL 语言,但是 ORA 能优化出来的语句,CH 却跑不出来,更证明 CH 的优化引擎能力比较差。坊间传说,CH 只擅长做单表遍历运算,有关联运算时甚至跑不过 MySQL,看来并非虚妄胡说。想用 CH 的同学要掂量一下了,这种场景到底能有多大的适应面?
计算变得复杂之后,CH 性能出现了明显的下降。Q2 涉及数据量较少,列存作用不大,CH 性能和 ORA 几乎一样。Q3 数据量较大,CH 占了列存的便宜后超过了 ORA。Q7 数据也较大,但是计算复杂,CH 性能还不如 ORA。做复杂计算快不快,主要看性能优化引擎做的好不好。CH 的列存占据了巨大的存储优势,但竟然被 ORA 用行式存储赶上,这说明 CH 的算法优化能力远不如 ORA。TPC-H 的 Q8 是更复杂一些的计算,子查询中有多表连接,CH 跑了 2000 多秒还没有出结果,应该是卡死了,ORA 跑了 192 秒。Q9 在 Q8 的子查询中增加了 like,CH 直接报内存不足的错误了,ORA 跑了 234 秒。其它还有些复杂运算是 CH 跑不出来的,就没法做个总体比较了。CH 和 ORA 都基于 SQL 语言,但是 ORA 能优化出来的语句,CH 却跑不出来,更证明 CH 的优化引擎能力比较差。坊间传说,CH 只擅长做单表遍历运算,有关联运算时甚至跑不过 MySQL,看来并非虚妄胡说。想用 CH 的同学要掂量一下了,这种场景到底能有多大的适应面?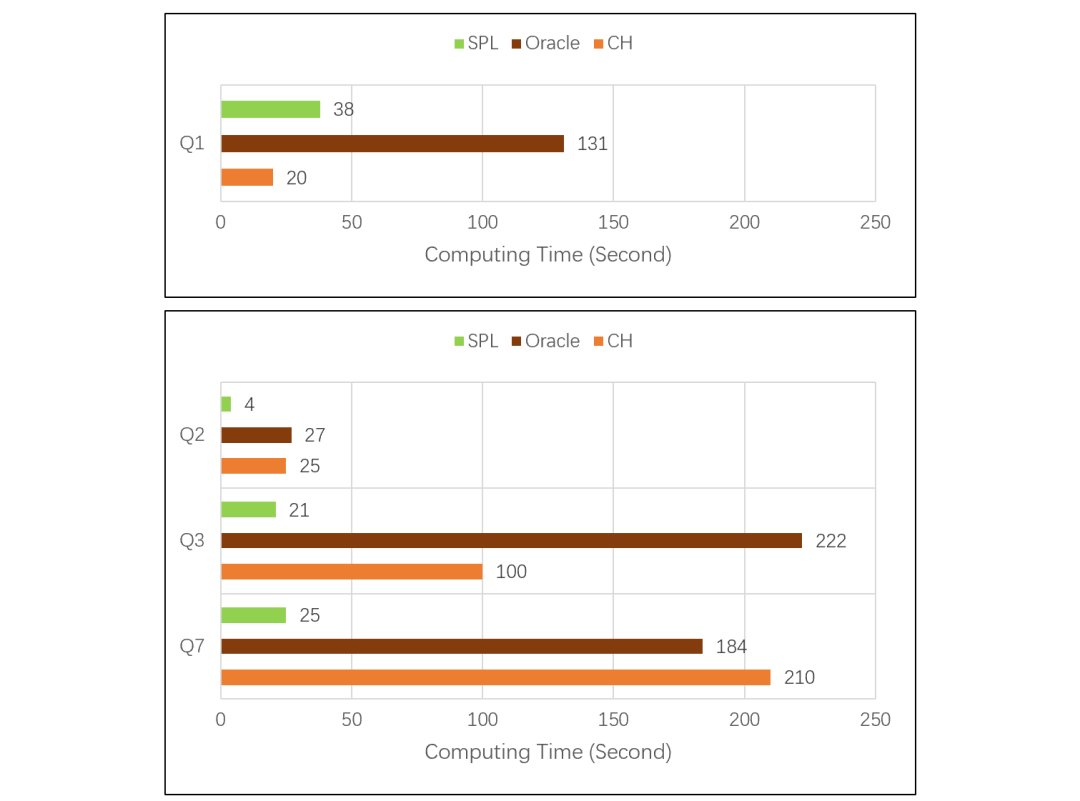 Q2、Q3、Q7 这些较复杂的运算,SPL 比 CH 和 ORA 跑的都快。CH 跑不出结果的 Q8、Q9,SPL 分别跑了 37 秒和 68 秒,也比 ORA 快。原因在于 SPL 可以采用更优的算法,其计算复杂度低于被 ORA 优化过的 SQL,更远低于 CH 执行的 SQL,再加上列存,最终是用 Java 开发的 SPL 跑赢了 C++ 实现的 CH 和 ORA。大概可以得到结论,esProc SPL 无论做简单计算,还是复杂计算性能都非常好。不过,Q1 这种简单运算,CH 比 SPL 还是略胜了一筹。似乎可以进一步证明前面的结论,即 CH 特别擅长简单遍历运算。且慢,SPL 还有秘密武器。SPL 的企业版中提供了列式游标机制,我们再来对比测试一下:在 8 亿条数据量下,做最简单的分组汇总计算,对比 SPL(使用列式游标)和 CH 的性能。(采用的机器配置比前面做 TPC-H 测试时略低,因此测出的结果不同,不过这里主要看相对值。)简单分组汇总对应 CH 的 SQL 语句是:SQL1:
Q2、Q3、Q7 这些较复杂的运算,SPL 比 CH 和 ORA 跑的都快。CH 跑不出结果的 Q8、Q9,SPL 分别跑了 37 秒和 68 秒,也比 ORA 快。原因在于 SPL 可以采用更优的算法,其计算复杂度低于被 ORA 优化过的 SQL,更远低于 CH 执行的 SQL,再加上列存,最终是用 Java 开发的 SPL 跑赢了 C++ 实现的 CH 和 ORA。大概可以得到结论,esProc SPL 无论做简单计算,还是复杂计算性能都非常好。不过,Q1 这种简单运算,CH 比 SPL 还是略胜了一筹。似乎可以进一步证明前面的结论,即 CH 特别擅长简单遍历运算。且慢,SPL 还有秘密武器。SPL 的企业版中提供了列式游标机制,我们再来对比测试一下:在 8 亿条数据量下,做最简单的分组汇总计算,对比 SPL(使用列式游标)和 CH 的性能。(采用的机器配置比前面做 TPC-H 测试时略低,因此测出的结果不同,不过这里主要看相对值。)简单分组汇总对应 CH 的 SQL 语句是:SQL1:
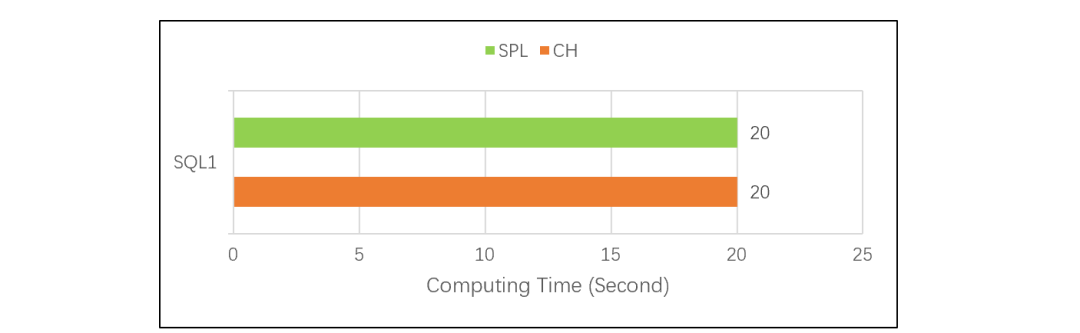 SPL 使用列式游标机制之后,简单遍历分组计算的性能也和 CH 一样了。如果在 TPC-H 的 Q1 测试中也使用列式游标,SPL 也会达到和 CH 同样的性能。测试过程中发现,8 亿条数据存成文本格式占用磁盘 15G,在 CH 中占用 5.4G,SPL 占用 8G。说明 CH 和 SPL 都采用了压缩存储,CH 的压缩比更高些,也进一步证明 CH 的存储引擎做得确实不错。不过,SPL 也可以达到和 CH 同样的性能,这说明 SPL 存储引擎和算法优化做得都比较好,高性能计算能力更加均衡。当前版本的 SPL 是用 Java 写的,Java 读数后生成用于计算的对象的速度很慢,而用 C++ 开发的 CH 则没有这个问题。对于复杂的运算,读数时间占比不高,Java 生成对象慢造成的拖累还不明显;而对于简单的遍历运算,读数时间占比很高,所以前面测试中 SPL 就会比 CH 更慢。列式游标优化了读数方案,不再生成一个个小对象,使对象生成次数大幅降低,这时候就能把差距拉回来了。单纯从存储本身看,SPL 和 CH 相比并没有明显的优劣之分。接下来再看常规 TopN 的对比测试,CH 的 SQL 是:SQL2:
SPL 使用列式游标机制之后,简单遍历分组计算的性能也和 CH 一样了。如果在 TPC-H 的 Q1 测试中也使用列式游标,SPL 也会达到和 CH 同样的性能。测试过程中发现,8 亿条数据存成文本格式占用磁盘 15G,在 CH 中占用 5.4G,SPL 占用 8G。说明 CH 和 SPL 都采用了压缩存储,CH 的压缩比更高些,也进一步证明 CH 的存储引擎做得确实不错。不过,SPL 也可以达到和 CH 同样的性能,这说明 SPL 存储引擎和算法优化做得都比较好,高性能计算能力更加均衡。当前版本的 SPL 是用 Java 写的,Java 读数后生成用于计算的对象的速度很慢,而用 C++ 开发的 CH 则没有这个问题。对于复杂的运算,读数时间占比不高,Java 生成对象慢造成的拖累还不明显;而对于简单的遍历运算,读数时间占比很高,所以前面测试中 SPL 就会比 CH 更慢。列式游标优化了读数方案,不再生成一个个小对象,使对象生成次数大幅降低,这时候就能把差距拉回来了。单纯从存储本身看,SPL 和 CH 相比并没有明显的优劣之分。接下来再看常规 TopN 的对比测试,CH 的 SQL 是:SQL2: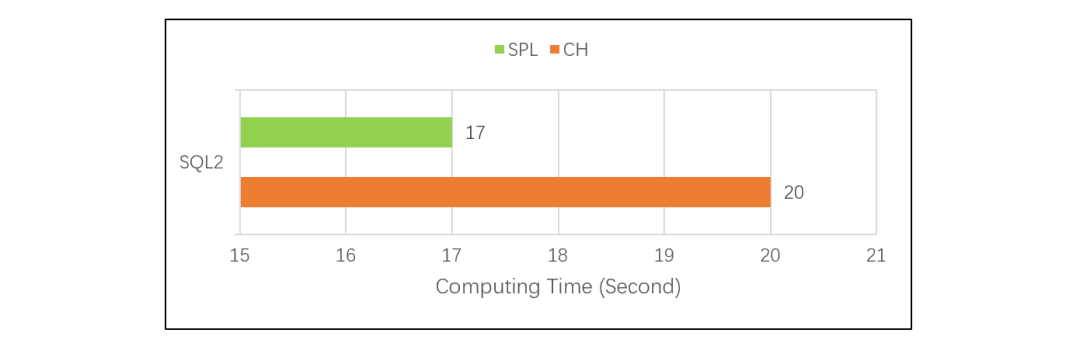 单看 CH 的 SQL2,常规 TopN 的计算方法是全排序后取出前 N 条数据。数据量很大时,如果真地做全排序,性能会非常差。SQL2 的测试结果说明,CH 应该和 SPL 一样做了优化,没有全排序,所以两者性能都很快,SPL 稍快一些。也就是说,无论简单运算还是复杂运算,esProc SPL 都能更胜一筹。
单看 CH 的 SQL2,常规 TopN 的计算方法是全排序后取出前 N 条数据。数据量很大时,如果真地做全排序,性能会非常差。SQL2 的测试结果说明,CH 应该和 SPL 一样做了优化,没有全排序,所以两者性能都很快,SPL 稍快一些。也就是说,无论简单运算还是复杂运算,esProc SPL 都能更胜一筹。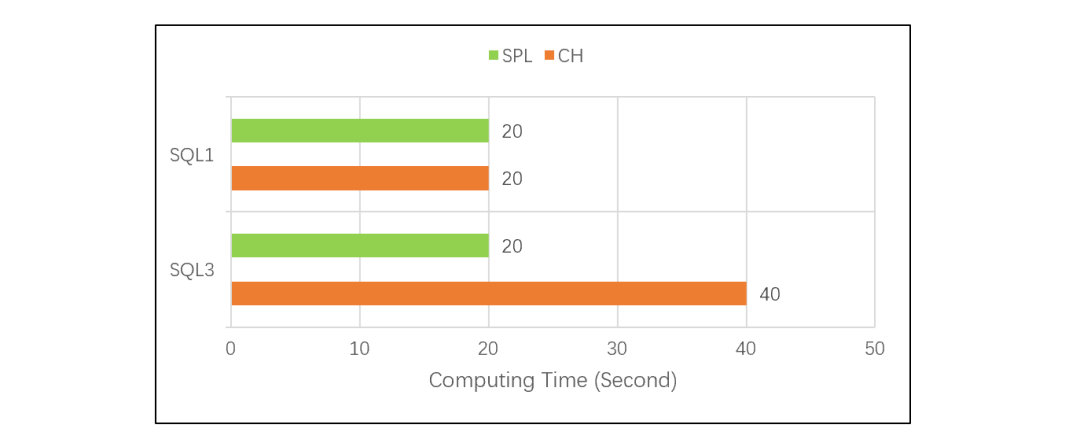 这是因为 SPL 不仅使用了列式游标,还使用了遍历复用机制,能在一次遍历过程中计算出多种分组结果,可以减少很多硬盘访问量。CH 使用的 SQL 无法写出这样的运算,只能靠 CH 自身的优化能力了。而 CH 算法优化能力又很差,其优化引擎在这个测试中没有起作用,只能遍历两次,所以性能下降了一倍。SPL 实现遍历复用的代码很简单,大致是这样:
这是因为 SPL 不仅使用了列式游标,还使用了遍历复用机制,能在一次遍历过程中计算出多种分组结果,可以减少很多硬盘访问量。CH 使用的 SQL 无法写出这样的运算,只能靠 CH 自身的优化能力了。而 CH 算法优化能力又很差,其优化引擎在这个测试中没有起作用,只能遍历两次,所以性能下降了一倍。SPL 实现遍历复用的代码很简单,大致是这样:
 CH 做分组 TopN 计算比常规 TopN 慢了 42 倍,说明 CH 在这种情况下很可能做了排序动作。也就是说,情况复杂化之后,CH 的优化引擎又不起作用了。与 SQL 不同,SPL 把 TopN 看成是一种聚合运算,和 sum、count 这类运算的计算逻辑是一样的,都只需要对原数据遍历一次。这样,分组求组内 TopN 就和分组求和、计数一样了,可以避免排序计算。因此,SPL 计算分组 TopN 比 CH 快了 22 倍。而且,SPL 计算分组 TopN 的代码也不复杂:
CH 做分组 TopN 计算比常规 TopN 慢了 42 倍,说明 CH 在这种情况下很可能做了排序动作。也就是说,情况复杂化之后,CH 的优化引擎又不起作用了。与 SQL 不同,SPL 把 TopN 看成是一种聚合运算,和 sum、count 这类运算的计算逻辑是一样的,都只需要对原数据遍历一次。这样,分组求组内 TopN 就和分组求和、计数一样了,可以避免排序计算。因此,SPL 计算分组 TopN 比 CH 快了 22 倍。而且,SPL 计算分组 TopN 的代码也不复杂:
审核编辑:汤梓红 ClickHouse vs Oracle
先用 ClickHouse(简称 CH)、Oracle 数据库(简称 ORA)一起在相同的软硬件环境下做对比测试。测试基准使用国际广泛认可的 TPC-H,针对 8 张表,完成 22 条 SQL 语句定义的计算需求(Q1 到 Q22)。测试采用单机 12 线程,数据总规模 100G。TPC-H 对应的 SQL 都比较长,这里就不详细列出了。Q1 是简单的单表遍历计算分组汇总,对比测试结果如下:CH 计算 Q1 的表现要好于 ORA,说明 CH 的列式存储做得不错,单表遍历速度很快。而 ORA 主要吃亏在使用了行式存储,明显要慢得多了。但是,如果我们加大计算复杂度,CH 的表现怎么样呢?继续看 TPC-H 的 Q2、Q3、Q7,测试结果如下:计算变得复杂之后,CH 性能出现了明显的下降。Q2 涉及数据量较少,列存作用不大,CH 性能和 ORA 几乎一样。Q3 数据量较大,CH 占了列存的便宜后超过了 ORA。Q7 数据也较大,但是计算复杂,CH 性能还不如 ORA。做复杂计算快不快,主要看性能优化引擎做的好不好。CH 的列存占据了巨大的存储优势,但竟然被 ORA 用行式存储赶上,这说明 CH 的算法优化能力远不如 ORA。TPC-H 的 Q8 是更复杂一些的计算,子查询中有多表连接,CH 跑了 2000 多秒还没有出结果,应该是卡死了,ORA 跑了 192 秒。Q9 在 Q8 的子查询中增加了 like,CH 直接报内存不足的错误了,ORA 跑了 234 秒。其它还有些复杂运算是 CH 跑不出来的,就没法做个总体比较了。CH 和 ORA 都基于 SQL 语言,但是 ORA 能优化出来的语句,CH 却跑不出来,更证明 CH 的优化引擎能力比较差。坊间传说,CH 只擅长做单表遍历运算,有关联运算时甚至跑不过 MySQL,看来并非虚妄胡说。想用 CH 的同学要掂量一下了,这种场景到底能有多大的适应面?esProc SPL 登场
开源 esProc SPL 也是以高性能作为宣传点,那么我们再来比较一下。仍然是跑 TPC-H 来看 :Q2、Q3、Q7 这些较复杂的运算,SPL 比 CH 和 ORA 跑的都快。CH 跑不出结果的 Q8、Q9,SPL 分别跑了 37 秒和 68 秒,也比 ORA 快。原因在于 SPL 可以采用更优的算法,其计算复杂度低于被 ORA 优化过的 SQL,更远低于 CH 执行的 SQL,再加上列存,最终是用 Java 开发的 SPL 跑赢了 C++ 实现的 CH 和 ORA。大概可以得到结论,esProc SPL 无论做简单计算,还是复杂计算性能都非常好。不过,Q1 这种简单运算,CH 比 SPL 还是略胜了一筹。似乎可以进一步证明前面的结论,即 CH 特别擅长简单遍历运算。且慢,SPL 还有秘密武器。SPL 的企业版中提供了列式游标机制,我们再来对比测试一下:在 8 亿条数据量下,做最简单的分组汇总计算,对比 SPL(使用列式游标)和 CH 的性能。(采用的机器配置比前面做 TPC-H 测试时略低,因此测出的结果不同,不过这里主要看相对值。)简单分组汇总对应 CH 的 SQL 语句是:SQL1:
这个测试的结果是下图这样:SELECT mod(id, 100) AS Aid, max(amount) AS AmaxFROM test.tGROUP BY mod(id, 100)
SPL 使用列式游标机制之后,简单遍历分组计算的性能也和 CH 一样了。如果在 TPC-H 的 Q1 测试中也使用列式游标,SPL 也会达到和 CH 同样的性能。测试过程中发现,8 亿条数据存成文本格式占用磁盘 15G,在 CH 中占用 5.4G,SPL 占用 8G。说明 CH 和 SPL 都采用了压缩存储,CH 的压缩比更高些,也进一步证明 CH 的存储引擎做得确实不错。不过,SPL 也可以达到和 CH 同样的性能,这说明 SPL 存储引擎和算法优化做得都比较好,高性能计算能力更加均衡。当前版本的 SPL 是用 Java 写的,Java 读数后生成用于计算的对象的速度很慢,而用 C++ 开发的 CH 则没有这个问题。对于复杂的运算,读数时间占比不高,Java 生成对象慢造成的拖累还不明显;而对于简单的遍历运算,读数时间占比很高,所以前面测试中 SPL 就会比 CH 更慢。列式游标优化了读数方案,不再生成一个个小对象,使对象生成次数大幅降低,这时候就能把差距拉回来了。单纯从存储本身看,SPL 和 CH 相比并没有明显的优劣之分。接下来再看常规 TopN 的对比测试,CH 的 SQL 是:SQL2:
SELECT * FROM test.t ORDER BY amount DESC LIMIT 100
对比测试结果是这样的:单看 CH 的 SQL2,常规 TopN 的计算方法是全排序后取出前 N 条数据。数据量很大时,如果真地做全排序,性能会非常差。SQL2 的测试结果说明,CH 应该和 SPL 一样做了优化,没有全排序,所以两者性能都很快,SPL 稍快一些。也就是说,无论简单运算还是复杂运算,esProc SPL 都能更胜一筹。进一步的差距
差距还不止于此。正如前面所说,CH 和 ORA 使用 SQL 语言,都是基于关系模型的,所以都面临 SQL 优化的问题。TPC-H 测试证明,ORA 能优化的一些场景 CH 却优化不了,甚至跑不出结果。那么,如果面对一些 ORA 也不会优化的计算,CH 就更不会优化了。比如说我们将 SQL1 的简单分组汇总,改为两种分组汇总结果再连接,CH 的 SQL 写出来大致是这样:SQL3:SELECT *FROM (SELECT mod(id, 100) AS Aid, max(amount) AS AmaxFROM test.tGROUP BY mod(id, 100)) AJOIN(SELECTfloor(id/200000)ASBid,min(amount)ASBminFROMtest.tGROUPBYfloor(id/200000))BONA.Aid=B.Bid
这种情况下,对比测试的结果是 CH 的计算时间翻倍,SPL 则不变:
这是因为 SPL 不仅使用了列式游标,还使用了遍历复用机制,能在一次遍历过程中计算出多种分组结果,可以减少很多硬盘访问量。CH 使用的 SQL 无法写出这样的运算,只能靠 CH 自身的优化能力了。而 CH 算法优化能力又很差,其优化引擎在这个测试中没有起作用,只能遍历两次,所以性能下降了一倍。SPL 实现遍历复用的代码很简单,大致是这样:| A | B | |
| 1 | =file("topn.ctx").open().cursor@mv(id,amount) | |
| 2 | cursor A1 | =A2.groups(id%100:Aid;max(amount):Amax) |
| 3 | cursor | =A3.groups(id200000:Bid;min(amount):Bmin) |
| 4 | =A2.join@i(Aid,A3:Bid,Bid,Bmin) | |
再将 SQL2 常规 TopN 计算,调整为分组后求组内 TopN。对应 SQL 是:
SQL4:SELECTgid,groupArray(100)(amount)ASamountFROM(SELECTmod(id, 10) AS gid,amountFROMtest.topnORDERBYgid ASC,amount DESC)ASaGROUPBYgid
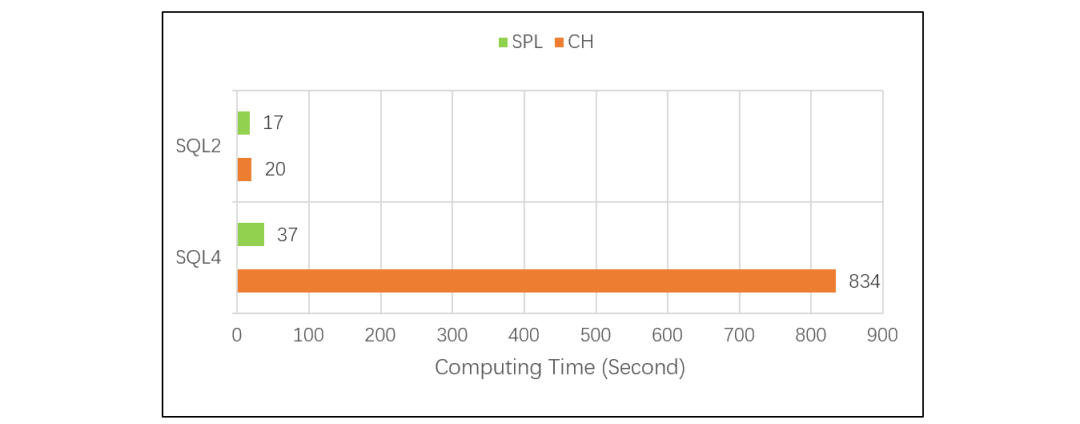
这个分组 TopN 测试的对比结果是下面这样的:
CH 做分组 TopN 计算比常规 TopN 慢了 42 倍,说明 CH 在这种情况下很可能做了排序动作。也就是说,情况复杂化之后,CH 的优化引擎又不起作用了。与 SQL 不同,SPL 把 TopN 看成是一种聚合运算,和 sum、count 这类运算的计算逻辑是一样的,都只需要对原数据遍历一次。这样,分组求组内 TopN 就和分组求和、计数一样了,可以避免排序计算。因此,SPL 计算分组 TopN 比 CH 快了 22 倍。而且,SPL 计算分组 TopN 的代码也不复杂:| A | |
| 1 | =file("topn.ctx").open().cursor@mv(id,amount) |
| 2 | =A1.groups(id%10:gid;top(10;-amount)).news(#2;gid,~.amount) |
不只是跑得快
再来看看电商系统中常见的漏斗运算。SPL 的代码依然很简洁:| A | B | |
| 1 | =["etype1","etype2","etype3"] | =file("event.ctx").open() |
| 2 |
=B1.cursor(id,etime,etype;etime>=date("2021-01-10") && etime |
|
| 3 | =A2.group(id).(~.sort(etime)) | =A3.new(~.select@1(etype==A1(1)):first,~:all).select(first) |
| 4 |
=B3.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime |
|
| 5 | =A4.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3) | |
CH 的 SQL 无法实现这样的计算,我们以 ORA 为例看看三步漏斗的 SQL 写法:
ORA 的 SQL 写出来要三十多行,理解起来有相当的难度。而且这段代码和漏斗的步骤数量相关,每增加一步数就要再增加一段子查询。相比之下,SPL 就简单得多,处理任意步骤数都是这段代码。这种复杂的 SQL,写出来都很费劲,性能优化更无从谈起。而 CH 的 SQL 还远不如 ORA,基本上写不出这么复杂的逻辑,只能在外部写 C++ 代码实现。也就是说,这种情况下只能利用 CH 的存储引擎。虽然用 C++ 在外部计算有可能获得很好的性能,但开发成本非常高。类似的例子还有很多,CH 都无法直接实现。with e1 as (select gid,1 as step1,min(etime) as t1from Twhere etime>= to_date('2021-01-10', 'yyyy-MM-dd') and etime<to_date('2021-01-25', 'yyyy-MM-dd')and eventtype='eventtype1' and …group by 1),with e2 as (select gid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2from T as e2inner join e1 on e2.gid = e1.gidwhere e2.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e2.etime<to_date('2021-01-25', 'yyyy-MM-dd')and e2.etime > t1and e2.etime < t1 + 7and eventtype='eventtype2' and …group by 1),with e3 as (select gid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3from T as e3inner join e2 on e3.gid = e2.gidwhere e3.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e3.etime<to_date('2021-01-25', 'yyyy-MM-dd')and e3.etime > t2and e3.etime < t1 + 7and eventtype='eventtype3' and …group by 1)selectsum(step1) as step1,sum(step2) as step2,sum(step3) as step3frome1left join e2 on e1.gid = e2.gidleft join e3 on e2.gid = e3.gid
总结一下:CH 计算某些简单场景(比如单表遍历)确实很快,和 SPL 的性能差不多。但是,高性能计算不能只看简单情况快不快,还要权衡各种场景。对于复杂运算而言,SPL 不仅性能远超 CH,代码编写也简单很多。SPL 能覆盖高性能数据计算的全场景,可以说是完胜 CH。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
SQL
+关注
关注
1文章
809浏览量
47027 -
数据库
+关注
关注
7文章
4092浏览量
68684 -
开源
+关注
关注
3文章
4426浏览量
46588
原文标题:ClickHouse 挺快,esProc SPL 更快
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
Linux下AWTK与Qt的性能对比
为了比较直观的看到AWTK的基本性能,我们对产品开发者比较关心GUI的一些参数做了测试,如界面刷新帧数、启动时间等。让我们从参数上直观了解Linux下AWTK与Qt的性能对比。
发表于 10-29 08:26
谈谈ST的单片机分类及性能对比
,转载请注明.文章目录前言一、ST的单片机分类二、ST性能对比总结前言最近,由于新项目即将开始,我在选型的时候,突然想到早些年的一个面试。当时面试的时候,我说了两个项目。两个用到了不同的MCU
发表于 12-09 06:10
arduino和stm32性能对比究竟谁更厉害?
一些DIY和各种小项目?arduino和stm32性能对比究竟谁更厉害呢?我们一起来讨论一下。比较两者之前首先我们来了解下arduino和stm32的特点:Arduino:Arduino UNO-DFRobot商城1. Arduino更倾向于创意,它弱化了具体的硬件的操作,它的函数...
发表于 01-24 07:14

ClickHouse和Elasticsearch压测对比
ClickHouse 是一个真正的列式数据库管理系统(MS)。在 ClickHouse 中,数据始终是列存储的,包括向量(对或列块)的执行过程。只要有可能,操作都是基于向量进行分派的,而不是实现的价值,这被称为«它有查询实际的数据处理»。



评论