 几种常用的NLP数据增强方法
几种常用的NLP数据增强方法

当训练数据量不充分,或者分布单一的情况下,数据增强可以快速扩充语料以避免过拟合的问题。同时,数据增强也可以提升模型的鲁棒性,避免微弱的变化使得模型无法泛化到相似的语境中。
机器学习和深度学习在包括文本分类等自然语言任务达到不错的效果,但他们 需要依赖于大规模的标注数据 ,除了直接使用小样本学习外,显式数据增强格外有效;
数据增强在计算机视觉中得以应用,其可以在数据量很少的情况下提升模型的鲁棒性;而在NLP中,通用的文本类型的数据增强 还没有完全被挖掘出来 ;
本文介绍几种比较简单但常用的NLP数据增强方法,包括显式和隐式两个方面,在实验或比赛中可以提升效果。可使用nlpaug[1]工具快速实现这些技术。
显式数据增强
给定一个输入文本,在尽可能不改变原是文本语义的情况下,微调或修改部分字符或词可以实现快速的增强,主要包括如下几种类型:
同义词替换 (SR) :随机挑选n个 非停用词 ,分别根据其 同义词表 随机替换一个同义词;
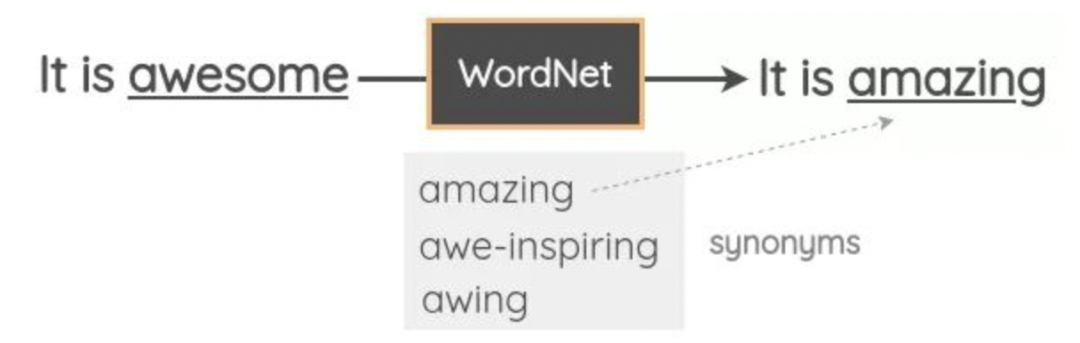
对于分类、回归等任务,可以使用反义词表替换所有原始词性的词,实现负采样,也是一种数据增强方法。但使用同义词或反义词表进行替换时,很难保证文本的语义是否符合预期。
随机插入 (RI) :在句子中随机找到一个 非停用词 ,并随机选择其对应的一个同义词,将该同义词插入句子中的 随机位置 。重复执行 n n n 次;
随机交换 (RS) :在句子中随机挑选两个词,并 交换位置 ,重复执行 n n n 次;
随机删除 (RD) :对每个词,有一定概率 p p p 进行 删除 ;
标点插入 (PI) :随机挑选若干位置,并分别随机插入 标点符号 ;
由于输入的文本长度长短不一,直觉上希望较长的句子 n 较大,因此通过一个参数 α 控制,即 ,对于 RD ,概率 。
本文对标点插入 PI 进行了实现,以中文为例,如下所示:
借助Spacy分词工具,需要安装Spacy,使用Spacy进行分词、分析词性,根据分词和词性选择需要插入的标点。
标点符号可以选择 ,。?!;“ ” 等。
importnumpyasnp importspacy importrandom fromtypingimportDict fromtqdmimporttqdm classDataAugmentation: def__init__(self): self.nlp=spacy.load('zh_core_web_sm') deffit(self,examples:Dict[str,list]): self.examples=examples#{'text':[],'label':[],'id':[]} #简单的数据增强:增加标点符号 text_list=self.examples['text'] label_list=self.examples['label'] id_list=self.examples['id'] aug_text_list,aug_label_list,aug_id_list=[],[],[] pun=[',','。','?','!',';','"'] foreiintqdm(range(len(text_list))): text=text_list[ei] label=label_list[ei] id=label_list[ei] doc=self.nlp(text)#spacy分词 token_list,pos_list=[],[] fortokenindoc: token_list.append(token.text) pos_list.append(token.pos_) iflen(token_list)-1>=1: num=0 state=False whilenum< 5: num += 1 insert_position = random.randint(1, len(token_list) - 1) if token_list[insert_position] in pun or token_list[insert_position - 1] in pun: continue token_list.insert(insert_position, ',') # 随机插入一个标点符号 pos_list.insert(insert_position, 'PUN') # 随机插入一个标点符号 state = True break if state is True: augment_text = ''.join(token_list) # print('origin text: {}'.format(text)) # print('augmen text: {}'.format(augment_text)) aug_text_list.append(augment_text) aug_label_list.append(label) aug_id_list.append(len(id_list) + ei + 1) return {'text': text_list + aug_text_list, 'label': label_list + aug_label_list, 'id': id_list + aug_id_list} if __name__ == '__main__': data_augmentation = DataAugmentation() dataset = {'text': ['今天的天气很好,非常适合去旅游。'], 'label': [1], 'id': [0]} dataset = data_augmentation.fit(dataset) print(dataset)
演示效果:
除了前述的几种方法,也可以采用如下几种新的策略:
单词缩写、全写:例如可以建立一个词表,对所有存在简写的词进行替换,例如 It is可以替换为 It’s,England可替换为UK.等;
错误拼写 (WS) :有时候为了提高鲁棒性,会故意将文本中的单词或字符使用错误拼写的单词或字符进行替换,在不影响语义的条件下 引入少量噪声 。例如 I like this book可以替换为 I like thes book。对于中文,也可以构建confusion set,替换字形或字音相似的词,例如“上海是经济中心”可以替换为“上海时经济中心”。但注意需要保证原始语义。
统计特征 (SF) :通常很多词在大规模语料中具有一定的统计特征,例如TF-IDF、互信息量等。在使用TF-IDF和互信息量时,可选择值较小的进行随机替换。
隐式数据增强
因为直接对原是文本进行数据增强,很难保证维持原始的文本语义,因此可以通过在语义空间上进行隐式数据增强,简单列出几种方法:
词向量替换 :通过word2vec或GloVe预训练的词向量获得相似的词,对于给定某个词,则可以直接随机选择相似的词的词向量进行替换;
词向量的原型向量: 通过word2vec或GloVe预训练的词向量,可以通过对所有相似的词或token的embedding进行平均池化。一般认为语义相似的词在语义空间内会聚集在一起,因此其平均的词向量可以认为是这些相似语义词的 原型向量(prototype embedding) ,原型向量可以作为隐式增强表征;
Dropout: 在对文本使用RNN、CNN或BERT等进行表征后,得到融合上下文信息的embedding,可以采用 随机dropout法 。具体地说,假设一个embedding是 [0.1, 0.4, 0.2, -0.5], 随机dropout旨在随机挑选一个元素替换为0,例如挑选第2个位置的元素替换为0,变为 [0.1, 0.0, 0.2, -0.5]。随机dropout参考了计算机视觉领域内对图像表征后的feature map进行mask的操作(在语义特征上添加噪点)以实现增强;
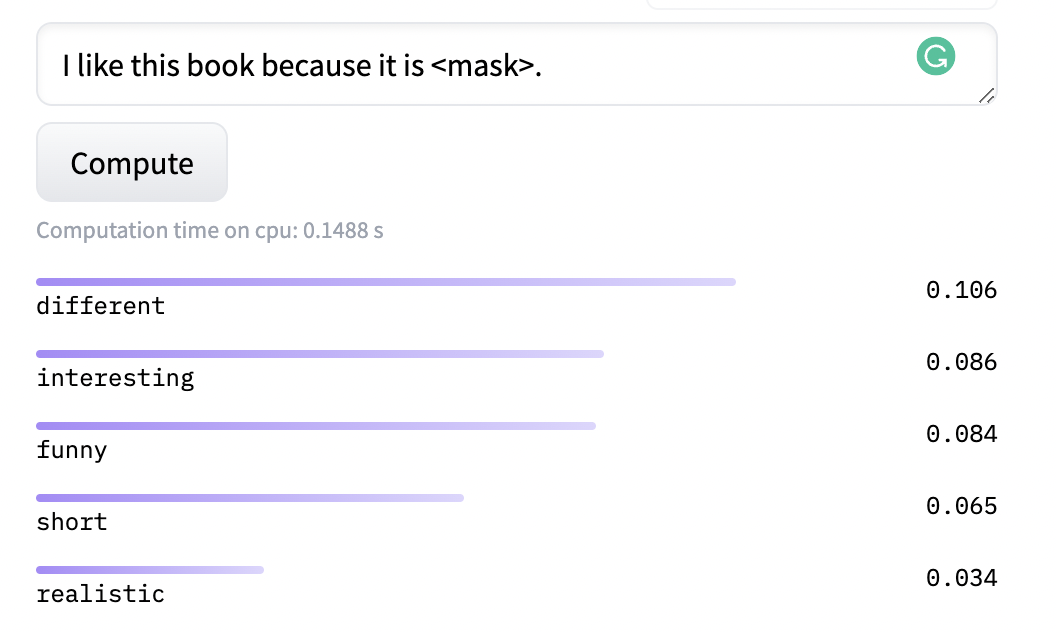
语言模型 Masked Language Modeling(MLM): MLM是BERT等预训练语言模型在大规模语料上自监督训练目标,其旨在随机挖掉一个文本中的token并让模型预测该词。由于大规模训练,使得模型可以预测出许多相似的结果,例如“I like this book because it is funny.”,我们可以让MLM生成与“funny”具有同等语义的词:
机器翻译: 基于机器翻译的方法,将原始文本翻译为另一种语言,并再次进行回译。该方法比较类似计算机视觉中的自编码器。但该方法需要率先在领域数据上进行训练,且依赖于大量的平行语料,较为繁琐;
文本生成: 基于生成的方法可以在不改变原始语义的前提下生成出上述无法显式构造的新文本。但基于生成的方法依然依赖于所属领域的训练数据。
如果需要增强的文本所属一个新的领域(例如医疗、生物),基于翻译和生成的方法则需要先在该领域的相关语料上进行训练,得到较为鲁棒的翻译或生成模型。但数据增强又是为了增强数据量,没有充分又无法训练翻译或生成模型,产生矛盾。因此通常对新的领域或任务上不会首选这两种方法。
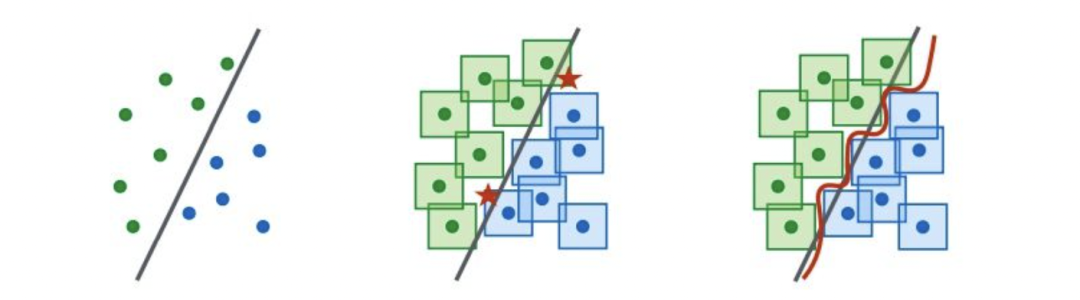
对抗训练: 引入对抗样本实现数据增强,例如下图(左)是少量样本时学习的决策边界,对每个样本在一定范围内进行扰动攻击,使得在直观上无法辨别,但在语义空间内则会影响样本的决策,例如下图(中),五角星则代表对抗样本。因此图(右)引入对抗训练目标以修改决策边界。通常对抗训练目标可以是对增强的样本伪造其标签以增强鲁棒性。
对比学习: 如果样本少,那就尽可能学习这些样本之间的差异。对比学习旨在构建样本对来解决训练困难问题,因为构建了样本对,所以间接地增加了数据量。虽然对比学习最初目标不是为了数据增强,但可以通过添加对比学习loss来隐式地提升鲁棒性;
自监督辅助任务: 如果目标NLP数据量少,那么可以直接引入大规模无监督语料(例如Wikipedia),并在具体任务训练时添加辅助学习目标,通过语义层面上实现增强;
例如在进行文本分类任务上时,除了文本分类损失函数外,还可以添加类似MLM的辅助任务,或者添加额外的多任务信息
知识图谱增强(远程监督法): 远程监督可以快速地启发式构建大规模标注数据,目前在信息抽取任务上使用广泛,其旨在通过一个已有的知识图谱或规则来直接对无监督的语料进行标注,但远程监督方法容易引入大量噪声。
在关系抽取任务中,通过知识库中已有的三元组(例如<乔布斯,创始人,苹果>),来标注一批新的实体对语料。但对于文本“乔布斯吃了一个苹果”而言,远程监督法依然会标注为“创始人”,但显然这是噪声。对于噪声,则可以通过一些规则,或Attention的方法解决。
半监督方法: 半监督法旨在对少量有标签数据上进行训练,然后在无标签数据上进行推理,并获得高置信度的伪标签数据后,再进行训练。因此伪标签数据可以作为数据增强部分语料,但依然容易引入噪声。
对于噪声部分,则可以采用几种策略:(1)提高置信度阈值,(2)多个不同的模型共同预测伪标签,取全部预测正确的作为可信样本;(3)伪标签数据回测评估:如果加入伪标签的数据后效果变差,则需要剔除或更改标签。
-
数据
+关注
关注
8文章
7348浏览量
95008 -
语言模型
+关注
关注
0文章
574浏览量
11341 -
nlp
+关注
关注
1文章
491浏览量
23341
原文标题:NLP中的数据增强方法!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录




评论