 一种单独适配于NER的数据增强方法
一种单独适配于NER的数据增强方法

本文首先介绍传统的数据增强在NER任务中的表现,然后介绍一种单独适配于NER的数据增强方法,这种方法生成的数据更具丰富性、数据质量更高。
0
前言
在NLP中有哪些数据增强技术?这一定是当今NLP面试中的必考题了吧。在《标注样本少怎么办?》(链接:https://zhuanlan.zhihu.com/p/146777068)一文中也详细总结过这个问题。 但是,目前来看:大多数「数据增强」方法通常被用于文本分类、文本匹配等任务中,这类任务有一个共性:是“句子级别”(sentence level)的分类任务,大多数关于「文本增强」的研究也都针对这个任务。 在2020年5月的时候,JayJay突然在想:NER如何进行数据增强?有什么奇思妙想可以用上?于是我陷入沉思中......
NER做数据增强,和别的任务有啥不一样呢?很明显,NER是一个token-level的分类任务,在进行全局结构化预测时,一些增强方式产生的数据噪音可能会让NER模型变得敏感脆弱,导致指标下降、最终奔溃。 在实践中,我们也可以把常用的数据增强方法迁移到NER中,比如,我们通常采用的「同类型实体」随机替换等。但这类方法通常需要获得额外资源(实体词典、平行语料等),如果没有知识库信息,NER又该如何做数据增强呢?有没有一种单独为NER适配的数据增强方法呢? 本文JayJay主要介绍在最近顶会中、对NER进行数据增强的2篇paper:
COLING20:《An Analysis of Simple Data Augmentation for Named Entity Recognition》
EMNLP20:《DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks》
COLING20主要是将传统的数据增强方法应用于NER中、并进行全面分析与对比。 EMNLP20主要是提出了一种适配于NER的数据增强方法——语言模型生成方法:1)这种方式不依赖于外部资源,比如实体词典、平行语料等;2)可同时应用于有监督、半监督场景。 具体效果如何,我们来一探究竟吧~本文的组织结构为:
1
传统的数据增强方法迁移到NER,效果如何?
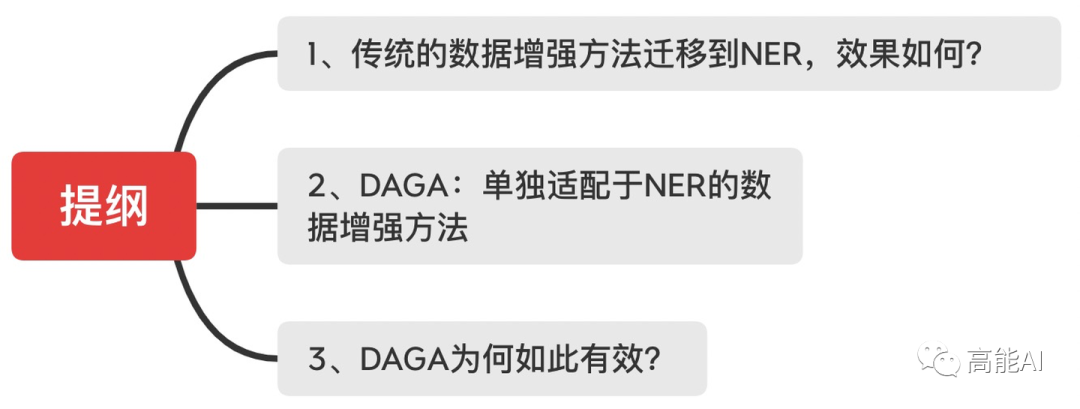
在COLING20的paper中,作者借鉴sentence-level的传统数据增强方法,将其应用于NER中,共有4种方式(如上图所示):
Label-wise token replacement (LwTR):即同标签token替换,对于每一token通过二项分布来选择是否被替换;如果被替换,则从训练集中选择相同的token进行替换。
Synonym replacement (SR):即同义词替换,利用WordNet查询同义词,然后根据二项分布随机替换。如果替换的同义词大于1个token,那就依次延展BIO标签。
Mention replacement (MR):即实体提及替换,与同义词方法类似,利用训练集中的相同实体类型进行替换,如果替换的mention大于1个token,那就依次延展BIO标签,如上图:「headache」替换为「neuropathic pain syndrome」,依次延展BIO标签。
Shuffle within segments (SiS):按照mention来切分句子,然后再对每个切分后的片段进行shuffle。如上图,共分为5个片段: [She did not complain of], [headache], [or], [any other neurological symptoms], [.]. 。也是通过二项分布判断是否被shuffle(mention片段不会被shuffle),如果shuffle,则打乱片段中的token顺序。
论文也设置了不同的资源条件:
Small(S):包含50个训练样本;
Medium (M):包含150个训练样本;
Large (L):包含500个训练样本;
Full (F):包含全量训练集;
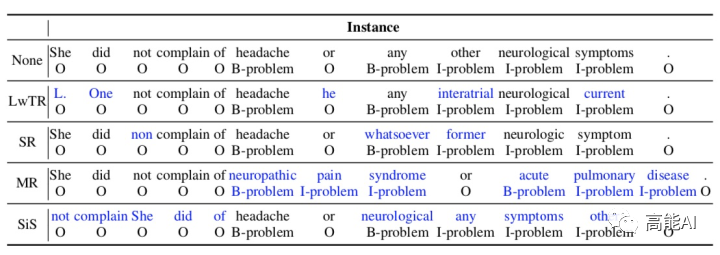
由上图可以看出:
各种数据增强方法都超过不使用任何增强时的baseline效果。
对于RNN网络,实体提及替换优于其他方法;对于Transformer网络,同义词替换最优。
总体上看,所有增强方法一起使用(ALL)会由于单独的增强方法。
低资源条件下,数据增强效果增益更加明显;
充分数据条件下,数据增强可能会带来噪声,甚至导致指标下降;
2
DAGA:单独适配于NER的数据增强方法
EMNLP这篇NER数据增强论文DAGA来自阿里达摩院,其主要是通过语言模型生成来进行增强,其整体思路也非常简单清晰。
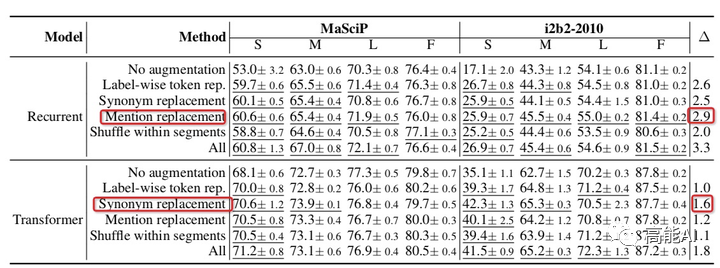
DAGA的核心思路也十分清晰,就是标签线性化:即将原始的「序列标注标签」与「句子token」进行混合,也就是变成「Tag-Word」的形式,如上图所示:将「B-PER」放置在「Jose」之前,将「E-PER」放置在「Valentin」之前;对于标签「O」则不与句子混合。标签线性化后就可以生成一个句子了,基于这个句子就可以进行「语言模型生成」训练啦~是不是超级简单?!
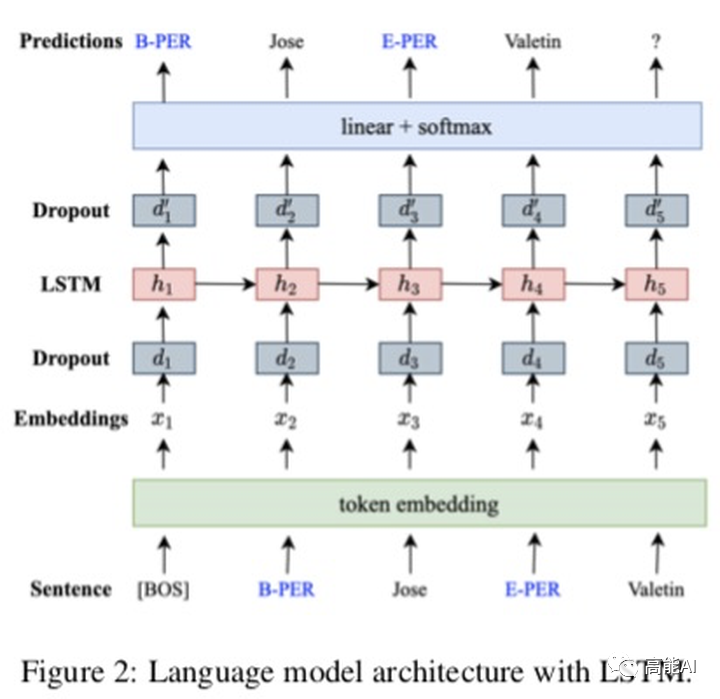
DAGA 网络(如上图)仅仅通过一层LSTM进行自回归的语言模型训练,网络很轻,没有基于BERT做。 DAGA的一大优点就是不需要额外资源,比如同义词替换就需要一个WordNet。但是论文也考虑到了使用外部资源时的情况,比如:1)有大量无标注语料时;2)有外部知识库时;

对于不同的3种资源条件下,具体的训练语料构建如上图所示:
对于标注语料,用[labeled]在句首作为条件标记;
对于无标注语料,用[unlabeled]在句首作为条件标记;
对于知识库,对无标注语料进行词典匹配后(正向最大匹配),用[KB]在句首作为条件标记;
只要输入[BOS]+[labeled]/[unlabeled]/[KB],即可通过上述语言模型、自回归生成新的增强数据啦~ 下面我们分别对上述3种资源条件下的生成方法进行验证:2.1 只使用标注语料进行语言生成共采用4种实验设置:
gold:通过标注语料进行NER训练
gen:即DAGA,1)通过标注语料进行语言模型训练、生成新的数据:2) 过采样标注语料; 3)新数据+过采样标注语料,最后一同训练NER;
rd:1)通过随机删除进行数据增强; 2)过采样标注语料;3)新数据+过采样标注语料,最后一同训练NER;
rd*:同rd,只是不过采样标注语料。
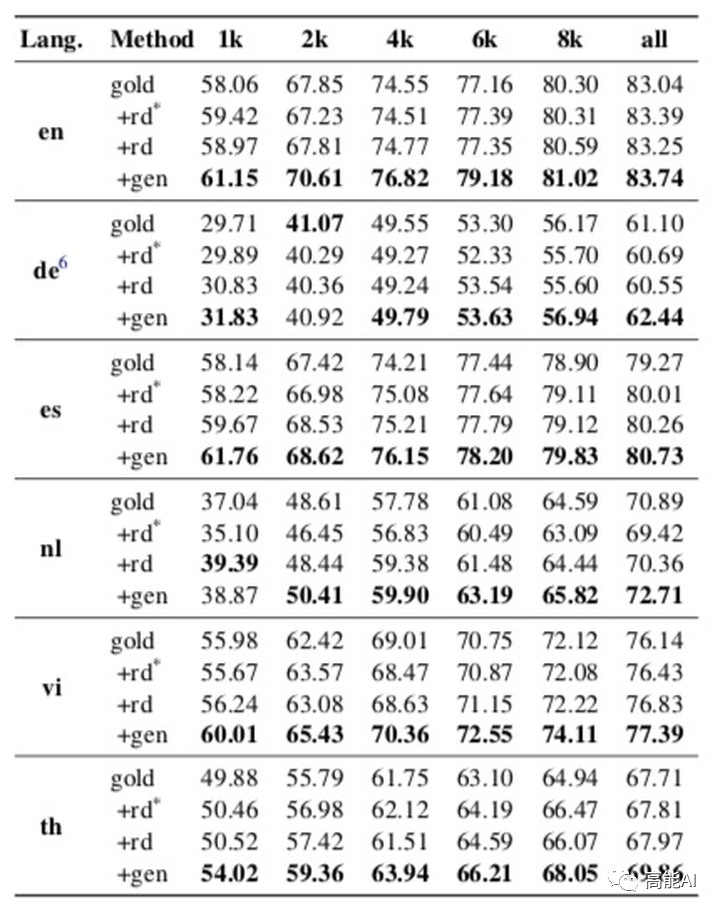
具体结果由上图展示(设置了6种不同语言数据、不同的原始标注数据量进行对比),可以看出:DAGA方式(gen)明显超过其他数据增强方法,特别是在低资源条件下(1k和2k数据量)。2.2 使用无标注语料进行语言生成共采用3种实验设置:
gold:通过标注语料进行NER训练;
wt:即弱监督方法,采用标注语料训练好一个NER模型,然后通过NER模型对无标注语料伪标生成新数据,然后再重新训练一个NER模型;
gen-ud:通过标注和无标注语料共同进行语言模型训练、生成新数据,然后再训练NER模型;
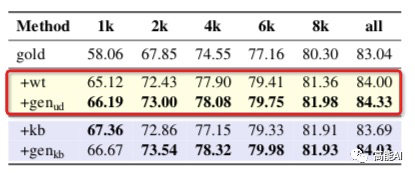
由上图的红框进行对比,可以看出:DAGA方法在所有设置下、均超过了弱监督数据方法。其实弱监督方法生成的数据质量较低、噪声较大,而DAGA可以有效改善这一情况。 可以预见的是:当有大量无标注语料时,DAGA进行的NER数据增强,将有效提升NER指标。2.3 使用无标注语料+知识库进行语言生成同样也是采用3种实验设置:
gold:通过标注语料进行NER训练;
kb:从全量训练集中积累实体词典(实体要在训练集上中至少出现2次),然后用实体词典匹配标注无标注语料、生成新数据,最后再训练NER模型;
gen-kb:与kb类似,将kb生成的新数据训练语言模型,语言模型生成数据后、再训练NER模型;
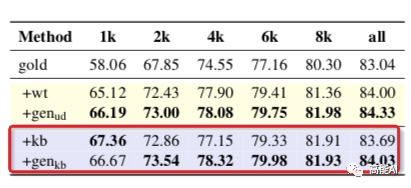
如上图红框所示,总体上DAGA超过了kb方式,低资源条件(1k)下,kb方式还是强于DAGA。
3
DAGA为何如此有效?

DAGA更具多样性:
如上图所示,在原始的训练集中「Sandrine」只会和「Testud」构成一个实体span,而DAGA生成的数据中,「Sandrine」会和更丰富的token构成一个实体。
此外,DAGA会生成更丰富的实体上下文,论文以相同实体mention的1-gram作为评估指标进行了统计。如下图所示,桔色代表DAGA生成的实体上下文,比原始的训练集会有更丰富的上下文。
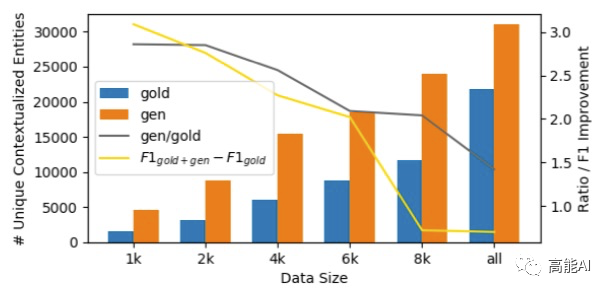
DAGA可以有效利用无标注语料:DAGA通过无标注语料来生成有用的数据,新数据中会出现那些未在标注语料中出现的新实体。
4
总结
本文就「NER如何进行数据增强」进行了介绍:
虽然传统的数据增强方法也可用于NER中,不过,JayJay认为:传统的数据增强方法应用到NER任务时,需要外部资源,且数据增强的丰富性不足、噪音可能较大。
基于语言生成的DAGA方法是NER数据增强的一种新兴方式,再不利用外部资源时会有较好的丰富性、数据质量较好。
责任编辑:xj
原文标题:打开你的脑洞:NER如何进行数据增强 ?
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
数据
+关注
关注
8文章
7378浏览量
95289 -
自然语言处理
+关注
关注
1文章
630浏览量
14789 -
nlp
+关注
关注
1文章
491浏览量
23413
原文标题:打开你的脑洞:NER如何进行数据增强 ?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
硅 N 通道增强型 VDMOSFET-CS10N65F A9R
将 MCUX SDK LIN 堆栈集成到 Zephyr OS 中,是否有一种方法可以自动生成它们从 .ldf 文件?

一种基于电压监控器与内置自检机制的汽车摄像头功能安全设计方法

指令集测试的一种纠错方法
汉思新材料取得一种无析出物单组份环氧胶粘剂及其制备方法的专利

当不同的数据放在同一个Flash页面上时,请问如何在不影响其他数据的情况下更改一些单独的数据?
一种新的无刷直流电机反电动势检测方法
一种永磁同步电机转子位置传感器零位偏差高精度测量方法
一种新的无刷直流电机反电动势检测方法
一种带通滤波器在无位置传感器转子检测中的应用
一种无序超均匀固体器件的网格优化方法

瑞萨MCU方案:瑞萨RZ/G2L Bootloader单独编译方法详解
汉思新材料取得一种PCB板封装胶及其制备方法的专利




评论