 Untether AI引领通用AI推理加速器市场
Untether AI引领通用AI推理加速器市场

凭借其独特的at-memory计算架构,Untether AI希望引领通用AI推理加速器市场。这家初创公司能否取代主导AI训练领域、并将触角伸向AI推理领域的领先CPU和GPU供应商?这些令人印象深刻的展示足以让这家公司成功吗? Untether AI是一家总部位于多伦多的AI芯片初创公司,上周在Hot Chips 2022上发布了其最新的通用AI推理加速器,名为speedAI,基于该公司的“at-memory”计算架构。
SpeedAI旨在解决AI计算工作量的爆炸性增长,以及在广泛的AI推理应用中对更高精度、更低延迟、更灵活和更优能效日益增长的需求。
Untether AI专注于推理应用,正试图模仿Nvidia在AI训练方面的成功。
AI处理分为两个阶段。在训练阶段,开发人员向他们的模型提供一个经过策划的数据集,这样它就可以“学习”它将分析的数据类型所需的一切。然后,在推理阶段,模型可以根据实时数据进行预测,产生可操作的结果。后者正是Untether AI所追求的细分市场。
Untether AI的目标是否过于雄心勃勃?也许。但基于其芯片前所未有的30 TFLOPS/W和2 PFLOPS的性能,Untether AI相信它有机会。该公司声称其最新的推理加速器“为能效和计算密度设定了新的标准”。
Yole Intelligence计算和软件技术和市场分析师Adrien Sanchez称speedAI的30FLOPS/W“令人印象深刻”。他补充说,这击败了Nvidia的A100,并与Nvidia的Hopper设备相媲美。Sanchez说:“诚然,将为训练量身定制的硬件与以推理为重点的硬件进行比较是完全不同的,但这仍然令人印象深刻。”AI推理市场涵盖了从自动驾驶汽车到智能城市/零售、自然语言处理和科学应用等方方面面。
处在十字路口的AI推理
在当今的通用AI处理器市场,Nvidia无疑是训练领域的王者。尽管Nvidia的高功耗解决方案不太适合AI推理应用,但在现实中,许多Nvidia客户最终也会使用Nvidia基于GPU的解决方案来满足他们的推理需求。
然而,AI推理市场正处于十字路口。许多用户很难在AI推理引擎中找到能效和灵活性之间的折中方案。
一方面,有广泛使用的基于CPU和GPU的解决方案。另一方面,许多推理处理器通常专门作为视觉处理器。Untether AI公司产品副总裁Bob Beachler表示,Mobileye和Ambarella等公司“可以在它们的SoC上实现一些AI功能,其中一些已经成功实现了量产。”
在目前碎片化的AI推理市场中,缺少一种能够处理各种应用中AI工作负载的推理引擎。
TechInsights的首席分析Linley Gwennap认为,“考虑到神经网络的多样性和变化”,即使是用于推理,最佳解决方案仍是通用AI处理器。另一种选择是“一种更具体的处理器,例如,只在卷积网络上工作”。
Gwennap说:“GPU更加通用,这就是为什么它如此普遍的原因。”Untether AI(在speedAI)增加了更多的灵活性,以满足AI推理应用的这些更广泛的需求。
可扩展的产品系列
Beachler表示,Untether AI将把speedAI变成一个可扩展的系列。上周发布的SpeedAI 240被是最大的设备,而一些列的缩小版(在不同的功率节点上有更少的memory bank)正在开发中。这些加速器的功率范围从10W到5W甚至是亚瓦,Beachler说,因此“我们的芯片可以成为任何嵌入式SoC的协处理器,这取决于你可能需要多少AI计算。”
SpeedAI 240计划在2023年初出样。按比例缩小的推理加速器计划在明年晚些时候推出。
At-memory计算
Untether AI之所以出名,是因为它自己发明了一种“at-memory”计算架构。
这家初创公司设计了at-memory计算,将其AI推理加速器从CPU和GPU冯·诺伊曼架构固有的低能效中解放出来。这是因为在冯·诺伊曼架构下,数据从DRAM传输到本地缓存,然后进入处理元素的距离要远得多。
Untether AI的at-memory方案在数据驻留的地方处理,专用SRAM使用短而宽的总线。这种memory bank架构允许AI计算所需的效率和带宽,同时支持计算的大规模并行直接连接。
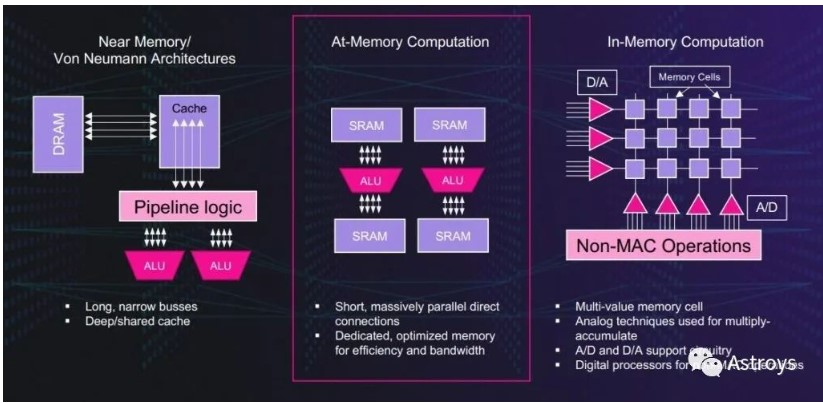
Untether AI使用At-Memory Computation进行AI加速。
这并不是UntetherAI的at-memory计算架构的第一次展示。该公司首先通过其最初的AI推理加速器runAI展示了其方法的优势。runAI于2020年秋季宣布将于本季度投产。
对于新的speedAI架构,Untether AI在能效、准确性和吞吐量方面增加了许多改进。它们包括第二代at-memory计算架构,超过1400个经过优化的RISC-V处理器与定制指令,并采用浮点数据类型FP8,用于增强推理加速。这些指标标志着runAI的原始性能(Integer数据类型为8个TOPS/W)提高到30TFLOPS/W(浮点计算)。
near-memory/冯·诺伊曼架构带来的吞吐量和能效不足等局限性是众所周知的。像Mythics这样的芯片设计公司一直在推广所谓的“in-memory计算”。
然而,at-memory计算是不同的。Beachler:“人们试图用内存单元来做乘积。”他解释说,问题是“你试图使用模拟技术,这导致了模拟效应,意味着你需要在它周围安装很多补偿电路。”他补充说,额外的电路并不能使in-memory计算设备更高效。
相比之下,在Untether AI,“我们将处理元素直接附加到标准SRAM单元上。”SpeedAI是数字化的,采用了TSMC 7nm CMOS技术。Beachler补充道:“我们围绕SRAM做所有的事情,最大限度地降低功耗。我们不做缓存,每个算术逻辑单元都有自己的内存。”
RISC-V处理器
Untether AI第二代at-memory计算架构的独特之处在于使用了RISC-V处理器。
两年半前,当Beachler加入Untether AI时,他曾问团队:“我知道你们为什么不使用Arm,但你们为什么不使用RISC-V处理器呢?”
对于runAI,Untether AI必须设计一个定制的RISC处理器。Beachler说,RISC-V的生态系统“还没有完全形成”。
对于speedAI,团队“添加了一堆扩展指令,我们称之为自定义指令,超过20多个”。Beachler解释道:“这是特定于我们正在进行的计算类型的,包括神经网络计算,以及我们的at-memory计算架构。”
Beachler指出,这种定制化是Untether AI即使在今天的Arm处理器上也无法做到的,因为Arm不开放其指令集。相反,“RISC-V允许这种情况发生。我们能够用我们自己的指令设计自己的定制处理器,但我们仍然使用RISC-V指令集架构。”
MemoryBank
Untether AI的第二代memory bank将使用RISC-V处理器,用于灵活、高效的AI加速。
据Untether AI称,speedAI架构中的每个memory bank都有512个处理元素,直接连接到专用SRAM。这些处理元素支持INT4、FP8、INT8和BF16数据类型,以及用于节能的零检测电路,并支持2:1结构稀疏性。
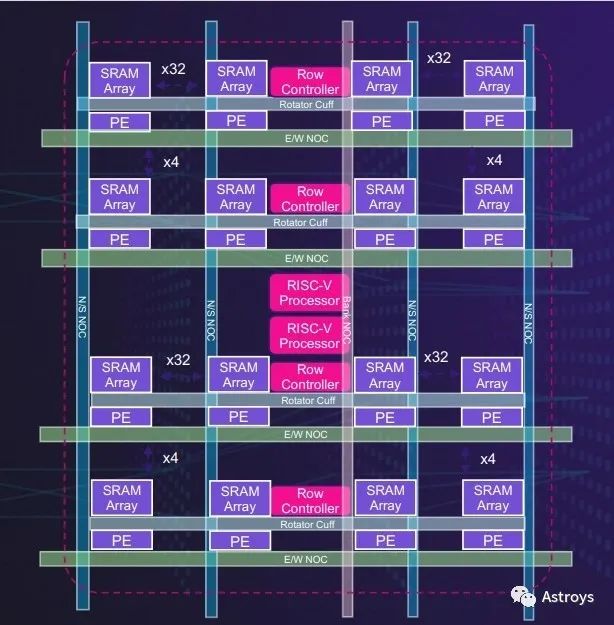
SpeedAI加速器使用双多线程RISC-V来提高memory bank的编程灵活性。
以8行64个处理元素排列,每一行有自己的专用行控制器和硬接线减少功能,以允许编程的灵活性和变压器网络功能的高效计算。
两个RISC-V处理器(每个处理器都有20多条用于推理加速的定制指令)管理各行。该公司表示,这种灵活的memory bank可以适应许多不同的神经网络架构,包括卷积、transformer和推荐网络以及线性代数模型。
精度问题
除了能效,UntetherAI团队还专注于提高其高速AI芯片的AI精度。Beachler说:“AI推理芯片的用户发现,当他们进行量化步骤时,有时会出现不可接受的准确性损失。对于某些应用来说,这没问题,但当AI推理加速器用于推荐引擎和自动驾驶汽车时就不行了。”
Beachler解释说,在AI推荐引擎中,“如果你的准确率仅下降0.1%,就可能会损失5000万至1亿美元的广告收入,因为你向消费者提供了错误的广告或推荐。准确性很重要的另一个领域是自动驾驶汽车,因为车厂在准确性上不会妥协。”
今年早些时候,当Nvidia宣布其Hopper架构时,这家GPU巨头谈到了一种新的8位浮点(FP8)数据类型。与标准的FP16训练相比,FP8格式的吞吐量增加了一倍。
SpeedAI也在使用FP8。经过自己的研究,该团队得出结论,两种不同的FP8格式为AI推理提供了精度、范围和效率的最佳组合。该公司解释说,将4-尾数(FP8p用于精度)和3-尾数(FP8r用于范围)相结合,为跨各种不同网络的推理提供了最佳的精度和吞吐量。”
对于卷积网络,Untether AI声称,使用FP8“与使用BF16数据类型相比,精度损失不到1%的十分之一,吞吐量和能效提高了四倍”。
不是“一刀切”
为什么市场需要一个通用的AI推理加速器?首先,因为AI推理加速应用的出现。
Beachler指出,除了中央计算系统必须处理越来越多感知数据的自动驾驶汽车之外,智能城市还部署着广泛的监控市场。“他们需要聚集数百个摄像头来生成实时可操作的情报。”这同样适用于军事AI应用,例如对抗无人机。“他们试图用不同的传感器扫描天空,以对抗无人机。或者他们会寻找雷达信号,以了解空域内的情况。”其他的AI推理应用包括自然语言处理加速,Untether AI将其加入到speedAI中。
Yole Intelligence的Sanchez表示,通用AI推理的其他应用包括实时分类的智能零售、金融领域的语音到文本、企业数据中心和高性能计算领域的气候建模。
其次,神经网络以及客户在执行AI时使用它们的方式有无数种变化。Beachler说:“我们已经分析了50多个不同的客户神经网络。每个都是不同的。他们可能从基本的开始,但随后他们会做出“适合他们数据集和训练”的偏差。
综上所述,你需要的是具有扩展性和灵活性的AI推理加速器架构。
然而,目前许多AI应用都依赖于现有的通用CPU和GPU。对于服务器中的AI应用,Sanchez说:“我们看到大部分的推理都是由CPU完成的。这是因为对推理任务的需求是零星的。对于客户来说,使用几个Xeon或Epyc内核进行快速推理比使用整个硬件池更方便。”
Untether AI面临的一大挑战是识别需要专用推理硬件的细分市场。Sanchez说:“超扩展性和服务器分离可能会增加推理专用硬件应对挑战的机会。”
软件陷阱
曾在Altera工作过的Beachler(就像Untether AI执行团队的许多成员一样)很清楚软件和工具流的重要性。就像FPGA客户遇到了软件编译问题或拟议硬件架构的利用率很差一样,一些AI芯片客户也遇到了类似的问题,“你不能编程,或者它太难编程。”
Beachler说:“正如我们在Altera学到的,我们确保我们的工具永远是行业中最好的,我们在Untether AI也在努力做同样的事,对软件进行过度投资。”
然而,Untether AI还没有提交给MLPerf对其AI芯片进行基准测试。Beachler说,公司的工程团队被50个客户拉去做50个不同的神经网络,这家初创公司的首要任务是“确保软件能够运行所有这些不同的神经网络”。
他说,这些都是“任何AI初创公司都会遇到的成长的痛苦”。但UntetherAI的首个AI加速器runAI已经投入使用,并为客户运行网络。
与大量现成的特定应用AI推理引擎不同,Untether AI的AI推理加速器被设计为通用设备。然而,这家初创公司似乎被拉向了多个方向,以满足客户的不同需求。Untether AI成功的关键在于它的软件和编程工具,让客户在使用Untether AI的加速器时能够独立地做出自己的偏差和修改。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20339浏览量
255229 -
cpu
+关注
关注
68文章
11332浏览量
225948 -
加速器
+关注
关注
2文章
841浏览量
40259 -
gpu
+关注
关注
28文章
5283浏览量
136093
发布评论请先 登录
黑马-Java+AI新版V16零基础就业班百度云网盘下载+Java+AI全栈开发工程师
边缘 AI 加速的 Arm® Cortex®‑M0+ MCU 如何为电子产品注入更强智能

使用NORDIC AI的好处
d-Matrix与Andes晶心科技合作打造下一代AI推理加速器
边缘计算中的AI加速器类型与应用

亚马逊云科技第三期创业加速器圆满收官 助力初创释放Agentic AI潜力 加速全球化进程
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的科学应用
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
研华科技推出紧凑型边缘AI推理系统AIR-120
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
芯原可扩展的高性能GPGPU-AI计算IP赋能汽车与边缘服务器AI解决方案
八天三次收购!AMD收购AI芯片制造商Untether AI团队,刺激创新




评论