 硅光芯片如何连接到GPU?
硅光芯片如何连接到GPU?

在过去几面,我们一直在谈论硅光子学,以至于我们可能和你们中的许多人一样,对它还没有普及感到沮丧。但好消息是随着电信号的进步,我们可能现在不得不转向光芯片寻找帮助。
由于组件之间的电气互连成本要低得多,这对价格/性能等式的价格分子部分来说是一个福音,尽管硅光子学在该等式的分母性能部分具有优势。随着时间的推移,随着带宽的增加,电信号变得越来越短,而且噪音也越来越大。这一天将不可避免地到来,我们将从电子转向光子作为电磁信号方法,从铜转向光纤玻璃作为信号介质。
这条曲线来自 Nvidia 首席科学家 Bill Dally 在 3 月份的光纤通信会议上发表的演讲,很好地说明了这一点:
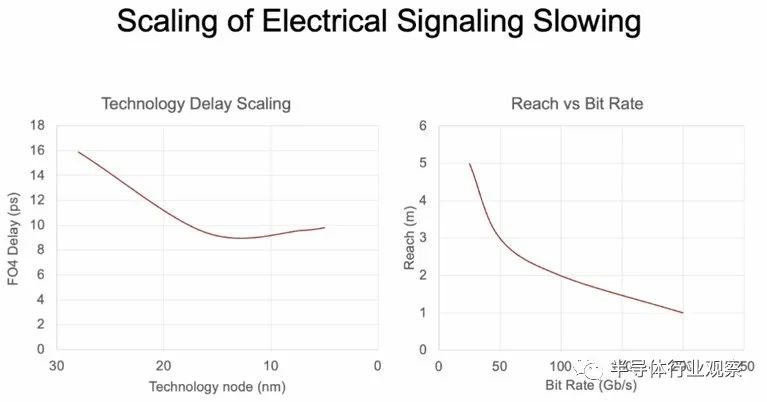
这些曲线没有争议,尽管你可以用材料科学魔法稍微弯曲它们。
几周前,英伟达与 Ayar Labs 签署了研发合作协议,我们坐下来与这家硅光子初创公司的首席执行官 Charlie Wuischpard 进行了交谈,讨论了两人将开展的工作。Nvidia 参与了 Ayar Labs 今年早些时候进行的 C 轮融资,当时它筹集了 1.3 亿美元来开发其带外激光器和硅光子互连。Hewlett Packard Enterprise也在今年 2 月与 Ayar Labs 签署了一项协议。为了弄清楚如何将硅光子学引入 Slingshot 互连,他也是今年 4 月那轮融资的投资者。Ayar Labs 也得到了英特尔的早期支持,尽管英特尔希望将激光器嵌入芯片内部,而不是像 Ayar Labs 那样从芯片外部泵入激光信号。(如果现在有什么是真的,那就是英特尔现在不能做错任何事。所以英特尔用硅光子对冲它的赌注是件好事。)
在 4 月份的融资时,我们与 Wuischpard 详细讨论了硅光子学适合现代系统的地方——以及它尚不适合的地方,最近,我们得到了一些关于 Nvidia 可能专门开发的东西的提示。
我们随后了解到 Dally 在 OFC 2022 上所做的上述演示,该演示非常具体地概述了使用密集波分复用 (DWDM:dense wave division multiplexing) 的共同封装光学器件的目标,以及如何将硅光子学用作交叉连接机架的传输和机架的 GPU 计算引擎。
该演示文稿展示了一个未命名的概念机器,例如Dally 的团队早在 2010 年开发的“Echelon”概念百亿亿次系统,我们在 2012 年就听说了。该机器有特殊的数学引擎——不是 GPU——它们之间具有高基数电气切换和 Cray “Aries” 机器机架之间的光学互连。而且那台 Echelon 机器显然从未商业化,而 Nvidia 取而代之的是 Dally 在 Nvidia Research 研究的 NVSwitch 内存互连,并提早将其投入生产,以制造本质上由fat多端口 InfiniBand 互连的大型iron NUMA GPU 处理器复合体代替pipes。
在最初的基于 NVSwitch 的 DGX 系统中,Nvidia 只能使用“Volta”V100 GPU 加速器在单个图像中扩展到 16 个 GPU,而使用“Ampere”A100 GPU 加速器时,Nvidia 不得不将每个 GPU 的带宽加倍,因此必须将 NVSwitch 的基数减少两倍,因此只能将八个 GPU 组合成一个图像。借助今年早些时候宣布的 NVSwitches 的leaf/spine 网络以及将于今年晚些时候发货的“Hopper”H100 GPU 加速器,Nvidia 可以将 256 个 GPU 组合成一个内存结构,这是一个巨大的改进因素。
但归根结底,作为 DGX H100 SuperPOD 核心的 NVSwitch 结构本质上仍然是一种创建放大 NUMA 机器的方法,而且它绝对受到电缆布线的限制。而且 NVSwitch 的规模,即使是 Hopper 一代,也比不上超大规模生产商为运行最大的 AI 工作负载而捆绑在一起的数万个 GPU。
“我不能谈太多细节,”Wuischpard 笑着告诉The Next Platform。“你知道,我们是一个物理层解决方案,在软件和 GPU、内存和 CPU 之间的编排方面,还有很多东西要超越它。我们不参与任何这些事情。因此,我想你可以将我们视为未来的物理支持。这是一种多阶段的方法。这不仅仅是一个踢轮胎的练习。但我们必须在一些参数范围内证明自己,我们必须达到一些里程碑。”
我们希望这能澄清这一点。
无论如何,现在让我们转向 Dally 在 OFC 2022 上的演讲,该演讲跳到了未来的 GPU 加速系统与硅光子互连的样子。在我们开始讨论之前,让我们看看 GPU 或交换机之间的带宽和功率限制、它们连接的印刷电路板以及它们可能被汇集到的机柜,这为硅光子互连奠定了基础:
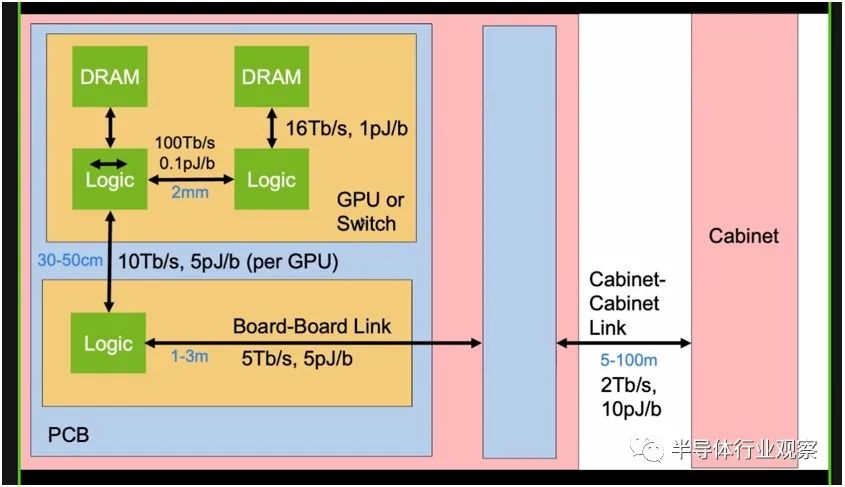
规则很简单,链路越短,带宽就越高,移位所消耗的功耗就越低。下表列出了中介层、印刷电路板、共封装光学器件、电缆和有源光缆的相对功率、成本、密度和每一个,所有这些都是构成现代系统不同层次的电线。
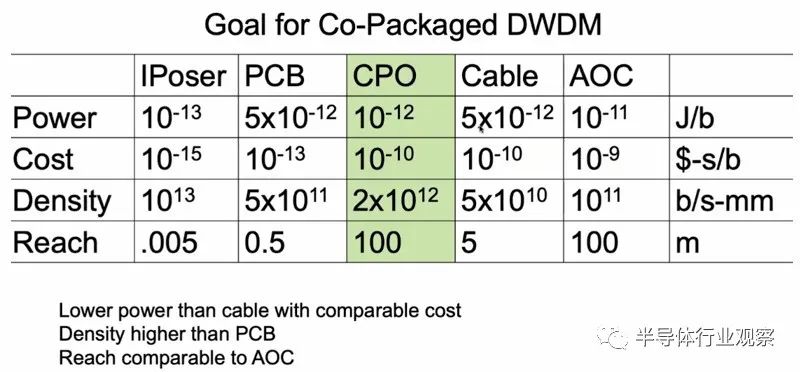
使用 DWDM 的共同封装光学器件的目标是具有比电缆更低的功耗,但成本相似,具有与有源电缆相当的范围,并提供与印刷电路板相当的信号密度。
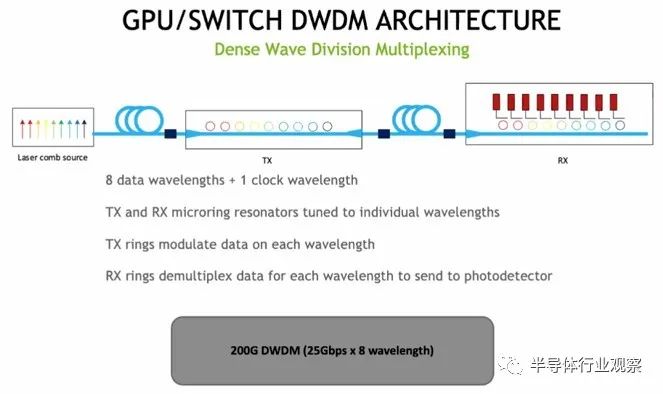
以下是 Dally 对 DWDM 信号的示意图:
下面是 GPU 和 NVSwitch 如何使用光学引擎将电信号转换为光学信号以创建 GPU 的 NVSwitch 网络的框图:
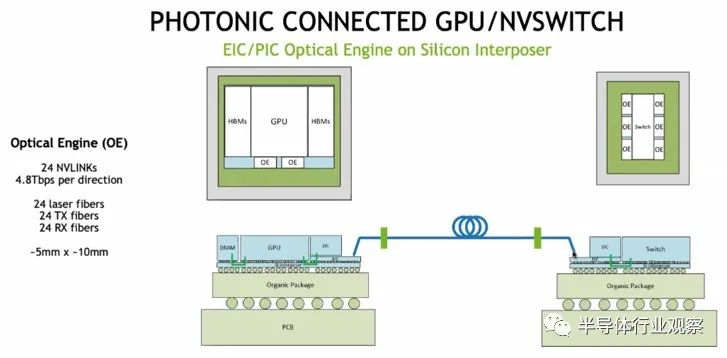
每个光学引擎有 24 根光纤,它们最初将以 200 Gb/秒的信号速率运行,总带宽为 4.8 Tb/秒。每个 GPU 都有一对这样的设备,可以为其提供进出 NVSwitch 结构的双向带宽。因此,具有六个光学引擎的 NVSwitch 的原始速率为 28.8 Tb/秒,去除编码开销后为 25.6 Tb/秒。
以下是 Nvidia 硅光子概念机中设备组件之间各种障碍的能耗如何计算:
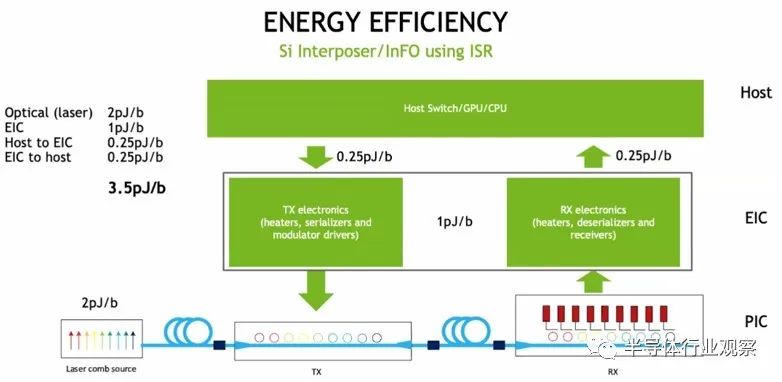
在 GPU 和交换机之间移入和移出数据的每比特 3.5 皮焦耳与 Dally 在上表中设定的目标完全一致。我们怀疑成本仍然必须降低才能使计算引擎可以接受共同封装的光学器件,但是这里正在进行大量工作,每个人都非常积极。
当前 DGX-A100 系统上的嵌入式 NVSwitch 结构上使用的电信号传输范围约为 300 厘米,并以每比特 8 皮焦耳的速度传输数据。目标是硅光子学以一半的能量做到这一点,并将设备之间的距离提高到 100 米。
发生这种情况时,您可以分解架构中的 GPU 和交换机——虽然 Nvidia 的概念机没有显示这一点,但 CPU 也可以具有光学引擎,并且它们也可以分解。
以下是带有共同封装光学器件的 GPU 和交换机的外观:
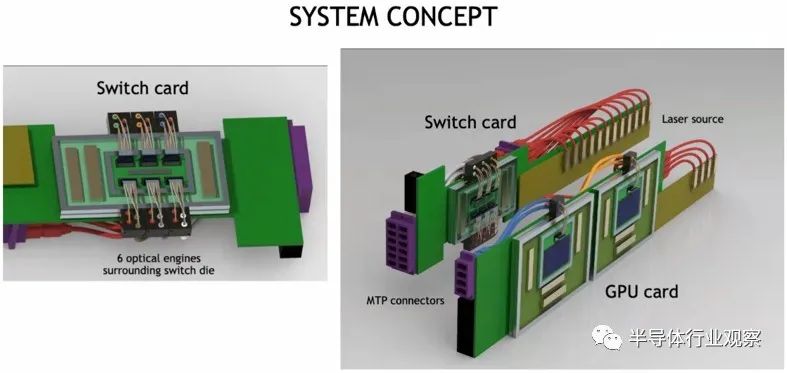
以下是具有 CPO 链接的 GPU 和 NVSwitch 的聚合方式:
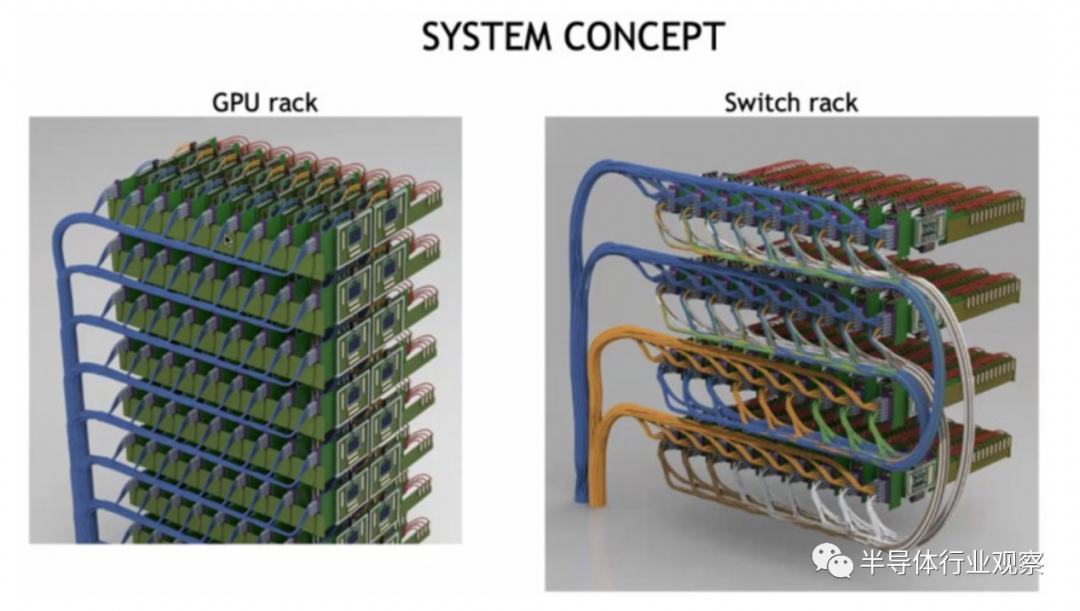
外部激光源占用了大量空间,但这也意味着机架的密度可以大大降低,因为设备之间的连接可以更长。这将使冷却更容易,并且激光器也可以更换。如果所有这些东西都运行得更冷,激光也会更好地工作。密度被高估了,并且在许多情况下,例如 DGX 系统,机器最终会变得非常热,以至于您无论如何只能安装一半的机架,因为功率密度和冷却需求超出了大多数数据中心的处理能力。
您会注意到,上面的 GPU 和开关行是垂直放置的,这有助于冷却。而且它们也没有安装在带有 sockets的巨型印刷电路板上,这将有助于降低整体系统成本,以帮助支付使用光学互连的费用。
审核编辑 :李倩
-
gpu
+关注
关注
28文章
5322浏览量
136213 -
光学
+关注
关注
4文章
896浏览量
38308 -
硅光芯片
+关注
关注
5文章
55浏览量
6609
原文标题:硅光芯片如何连接到GPU?英伟达是这样看的!
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
烧结银膏在硅光技术和EML技术的应用
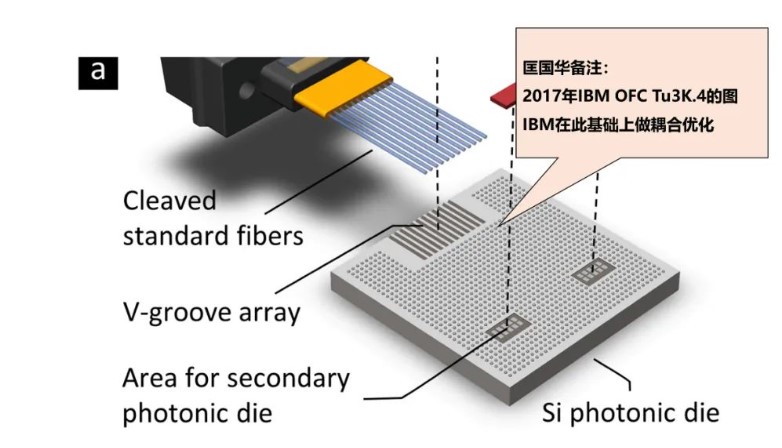
【封装技术】几种常用硅光芯片光纤耦合方案
请问6678的SGMII接口能否不通过外部的PHY芯片直接连接到光模块?
高速数据传输中的高度集成硅光引擎
上海布局硅基光互连芯片研发和生产
Snap:bit:将Whistle芯片连接到Micro:bit

国产厂商抢占硅光芯片的风口

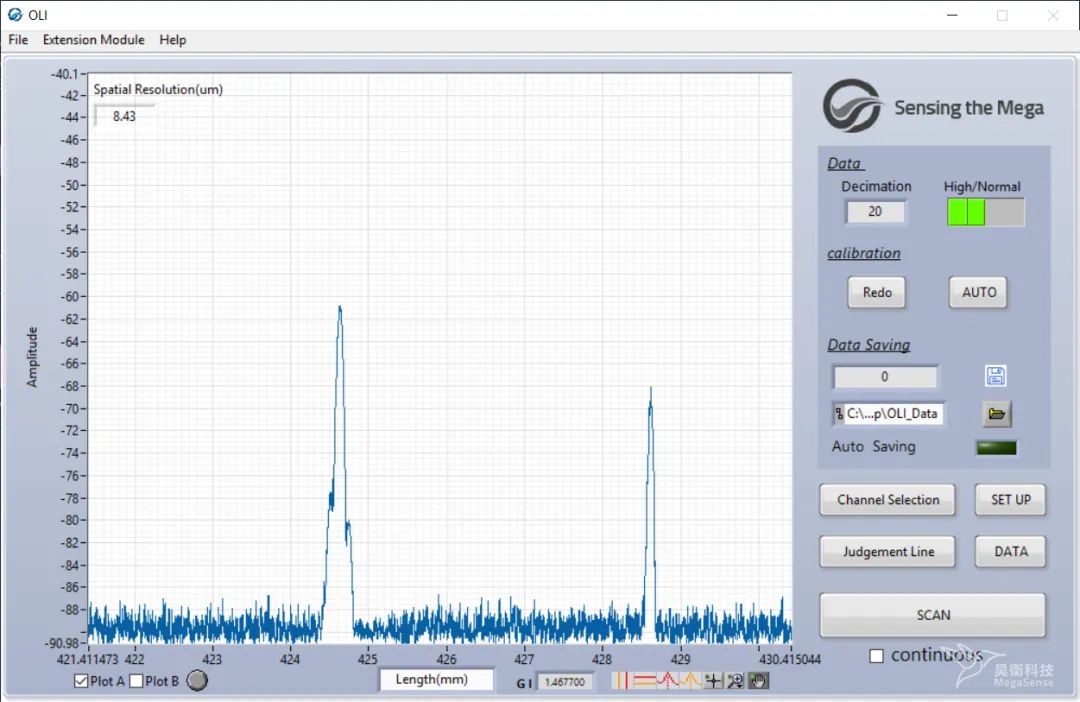
OLI测试硅光芯片内部裂纹




评论