 利用BittWare FPGA解决方案构建NVMe Over Fabrics
利用BittWare FPGA解决方案构建NVMe Over Fabrics

BittWare提供FPGA加速解决方案,以实现基本的硬件卸载(压缩、去重复化等),加上特定应用的算法,如使用FPGA进行推理的机器学习应用。这种以与NVMe相匹配的性能水平对存储进行基本和高级加速的组合就是我们所说的计算存储。我们的250系列产品,包括250S+、250-SoC和250-U2,都专注于这个市场。
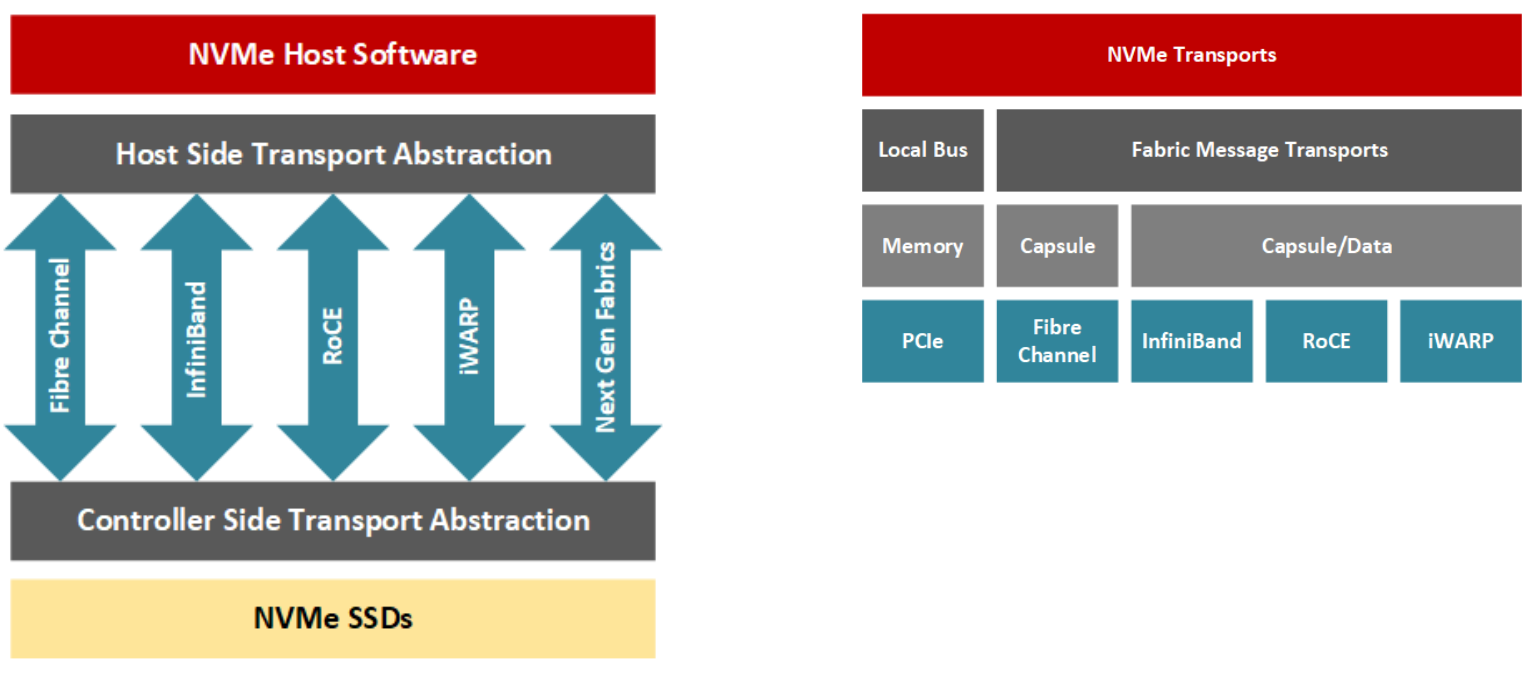
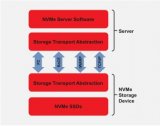
NVMe联盟推出了一个名为NVMe over Fabrics(NVMe-oF)的协议变体,以利用NVMe在现有网络基础设施上的优势。随着数据中心不断扩大内部NVMe存储,远程用户可以使用NVMe-oF以很少的开销访问分类存储(Gibb,2018)。这需要在硬件中实现专门的网络堆栈,以保持NVMe的低延迟和高带宽优势。
我们的解决方案在250-SoC板上使用了FPGA与片上ARM处理器Xilinx Zynq MPSoC。FPGA作为NVMe-oF控制器,在使用片上处理器时,从CPU中卸载,甚至与CPU解耦。我们通过在FGPA逻辑中完全实现NVMe数据平面,包括网络协议栈,提供低延迟和高带宽。ARM内核在设计中是为了使用软件来处理控制平面,其中延迟和带宽问题较少。本应用说明介绍了如何将BittWare 250-SoC配置为JBOF中的NVMe-oF控制器。
什么是NVMe over Fabrics?
NVMe-oF协议使用高速SSD技术,并将其扩展到本地服务器或数据中心之外。
NVMe-oF允许应用开发者访问网络结构上的远程存储节点,如光纤通道、InfiniBand、通过聚合以太网(RoCE)的RDMA(远程直接内存访问)、iWARP和最近的TCP/IP,同时保持较低的延迟(通常对于一个由100个NVMe驱动器组成的集群来说,延迟在10us之间,对于大型集群来说,延迟在100微秒之间)。简而言之,一个NVMe-oF事务涉及一个主机和一个目标;目标是服务器在网络上暴露NVMe块存储设备,供主机服务器访问(Davis,2018)。使用RDMA,主机-目标数据传输可以在没有CPU处理事务的情况下进行,相反,专用的RNIC在资源之间传递数据,对计算资源的影响很小,因为NIC中的部分硬件管理网络堆栈的传输层。
为什么NVMe-oF要用FPGA?
当你决定将NVMe-OF卸载到PCIe卡上时,你基本上有三种选择。
首先,你可以使用ASIC实现,这将是成本最低、延迟最低的选择。然而ASIC不允许你也卸载“计算存储”算法。ASIC一般也只适用于最流行的网络带宽,很少有最高带宽的。
其次,你可以使用核数较多的系统级芯片,这样就可以增加“计算存储”算法。但是,这样做需要并行编程能力。最终的解决方案一般是这里选择中延迟最高的,这直接违背了NVMe的低延迟价值主张。和ASIC一样,这些MPP SOC一般只适用于最流行的网络带宽,而这些带宽很少是最高带宽。
第三,你可以使用FPGA。这种方案可以让你在保持类似ASIC的延迟的同时,增加“计算存储”算法。这种方案还可以实现100甚至400Gb等高带宽网络。虽然它可能是三个选项中最昂贵的,但当你考虑到存储市场所涉及的数量时,成本差异只会变得略高。
自适应存储
通过利用FPGA和SoC等技术,数据中心架构师可以进一步减少数据密集型操作中数据到/从CPU的移动。通过硬件驱动的加速,用户应用表现出更高的性能和更低的响应时间。随着空闲CPU周期数的增加,分配工作负载的进程可以更高效地利用专用硬件和CPU的混合系统架构。FPGA结构、其IO吞吐量和编程灵活性有利于设计与高带宽NVMe存储紧密耦合的可重构硬件。FPGA特别适用于压缩、加密、RAID和擦除代码、数据重复数据删除、键值卸载、数据库查询卸载、视频处理或NVMe虚拟化等。FPGA硬件提供了专用解决方案的性能,但也具有可重新配置的优势,可随着数据中心需求的变化而快速切换用途。
使用Xilinx MPSoC实现NVMe-oF目标
BittWare 250-SoC采用Xilinx UltraScale+ Zynq ZU19EG MPSoC,既可以通过两个QSFP28端口连接到网络结构,也可以通过一个16线主机接口或四个8线OCuLink连接器连接到PCIe结构。这款MPSoC适配器是驱动NVMe-oF目标节点的完美平台,因为它结合了FPGA结构(也称为PL或可编程逻辑)中的数据流计算、网络IO、PCIe连接和板载ARM处理器。请注意,ARM不在数据平面,它处理控制平面的工作。在CPU和存储端点之间放置一个专用的硬件加速器,可以创建一个优化的系统,使计算更接近数据。

硬件
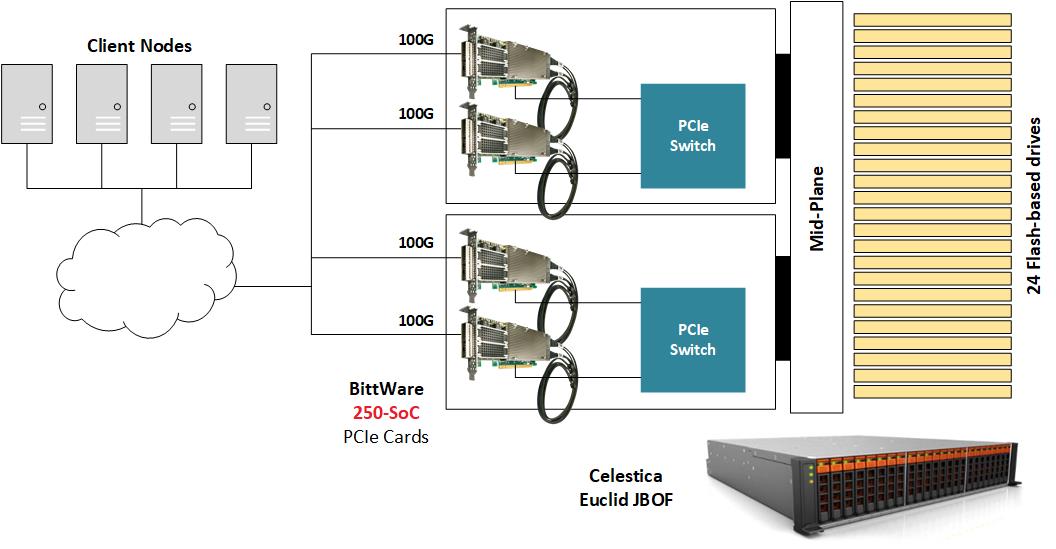
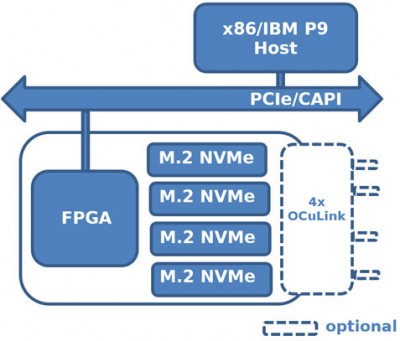
为了演示NVMe-oF,BittWare将250-SoC放置在JBOF(Just-A-Bunch-Of-Flash)机箱内,机箱内填充了多个NVMe U.2驱动器,并将250-SoC板的QSFP28端口暴露在网络中。Celestica Euclid JBOF具有两个带PCIe交换机和PCIe插槽的插入式刀片;每个抽屉作为网络结构和NVMe存储之间的管道。NVMe数据包从QSFP28端口中转到FPGA结构,然后经过PCIe主机接口、JBOF的PCIe交换机,最后到达NVMe驱动器。在本实施例中,没有使用250-SoC OCuLink连接器,但在不同的硬件平台上,它们可以容纳本设计的有线版本,其中PCIe事务将通过电缆运行。
Gateware
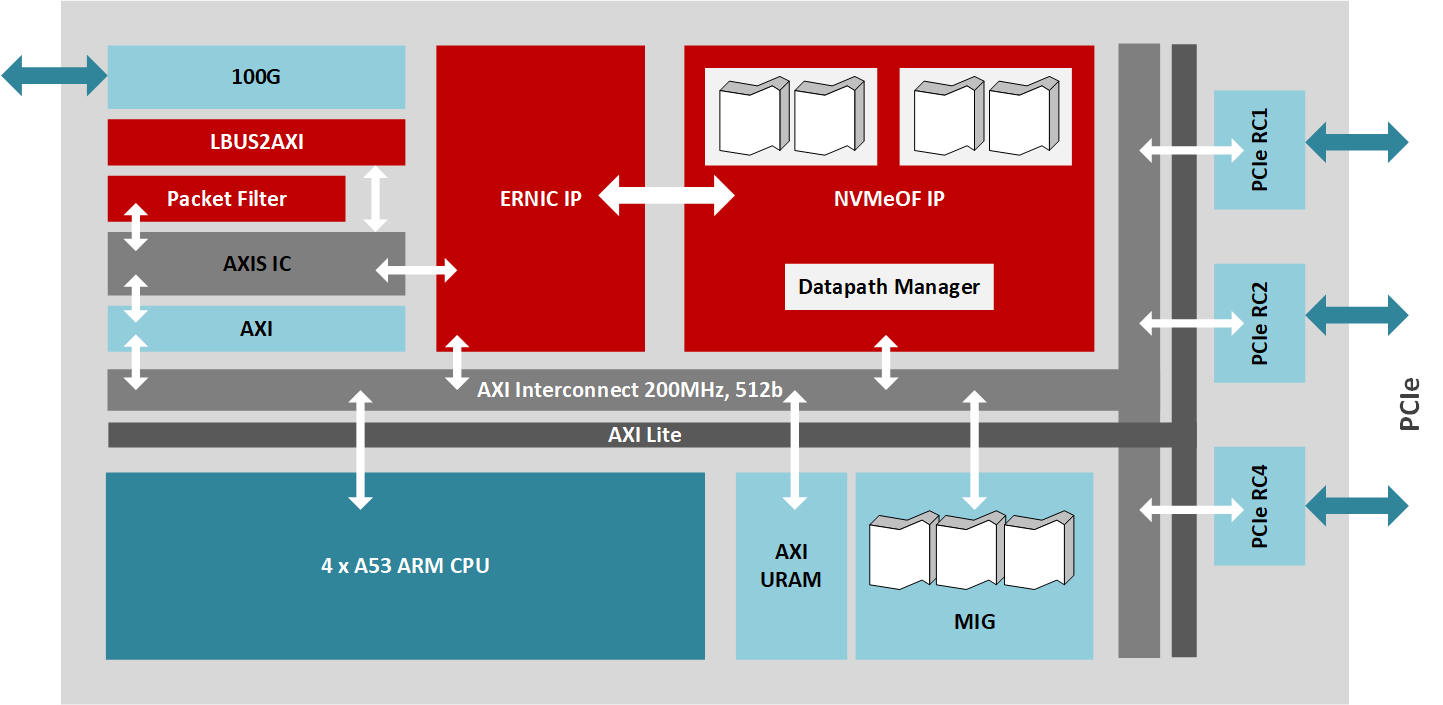
该设计实现了RoCE v2的NVMe-oF目标(符合NVMe 1.2和NVMe-oF 1.0规范),它支持显式拥塞管理。针对MPSoC的IP使用了多个Xilinx IP库块,所有的数据平面都通过运行在200MHz的512位AXI总线互连。Xilinx Embedded RDMA NIC处理100Gb/s的网络流量,而PCIe根复合IP核则管理与16线PCIe 3.0接口的连接,连接到驱动多达24个驱动器的JBOF电路,DMA核则控制AXI总线上的高速数据传输。此外,NVMe-oF目标核通过100Gb/s数据路径管理多达256个队列,而运行在四核A53 ARM处理器上的固件则处理存储节点的高层管理。
最大限度地提高性能
MPSoC PL可以容纳数据路径的最大带宽。因此,为了展示整个系统的最大能力,主机必须产生尽可能接近100Gb/s的网络流量。为了进行基准测试,几台NVMe-oF主机连接到网络交换机,然后交换机可以将最大数据吞吐量馈送到JBOF中运行NVMe-oF目标的250-SoC MPSoC卡。这个参考设计显示出约2.5 MIOPS的随机读取性能和超过1.1M的随机写入性能,同时显示出105 us的应用延迟。

可重构硬件解决方案的优势
基于MPSoC的NVMe-oF解决方案与软件(CPU+外部网卡+SPDK)或RNIC解决方案(CPU+集成网卡)相比,有几个优势。如果说基于MPSoC的解决方案与其他产品相比具有相对较高的成本和功耗,那么从带宽、可配置性和延迟的角度来看,这种技术就会优于竞争对手。同样,对于RNIC解决方案来说,MPSoC NVMe-oF将使网络接口的吞吐量达到饱和。然而,MPSoC硬件实现提供了其他解决方案所不具备的灵活性和适应性水平。因此,这种自适应硬件可以针对特定领域的应用,允许系统架构师将客户定义的功能(RAID或随着规格的发展而出现的新的NVMe功能)与主IP相结合,并增强整体系统的功能集。另一种选择是添加自定义加速器,例如加密或压缩,将两种功能结合在一个盒子里。最后,解决方案提供商可以创建针对特定用途优化的特定应用硬件产品,如视频处理(例如视频编解码器)或人工智能工作负载。通过将存储管理等IT功能与通常由昂贵的计算节点执行的任务相结合,CPU可以从执行高带宽IO传输中解脱出来,并被重新用于更多的计算关键操作。从延迟的角度来看,基于MPSoC的解决方案比CPU驱动的替代方案提供了低和可预测的延迟。
结论
随着NVMe在过去几年的成熟,它为NVMe-oF铺平了道路,现在NVMe-oF为分列式存储环境提供了与NVMe类似的优势(Weaver,2019)。该技术提高了计算和存储节点的利用率,同时提高了数据中心的敏捷性和性能(Waever,2019)。NVMe-oF允许开发人员以新颖的方式瞄准应用,例如,需要在庞大的数据集(几百s PB)上随机读取的AI工作负载将显著受益于这项技术(Hemsoth,2019)。FPGA和MPSoC在NVMe-oF协议之上提供了额外的创新层;这些器件中的可编程逻辑允许设计系统架构,可以处理高带宽数据传输、低延迟,同时还可以保持可配置的优化或特定应用的定制。BittWare提供一系列NVMe加速选项,包括NVMe-oF--请与我们联系,了解更多信息。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
20395浏览量
255746 -
FPGA
+关注
关注
1665文章
22587浏览量
641250 -
控制器
+关注
关注
114文章
17931浏览量
196009
发布评论请先 登录
FPGA加速的NVMe存储解决方案
NVMe协议研究扫盲
NVMe over Fabrics 国产 IP:高性能网络存储解决方案
如何用MRAM和NVMe SSD构建未来的云存储的解决方案
Marvell推出NVMe-oF以太网SSD技术和新一代SSD控制器解决方案
如何选择合适的NVMe-over-Fabrics方案
Solarflare公司正在推广使用基于以太网的NVMe-over-Fabrics
华为端到端NVMe over RoCE增强方案亮相,打造高性能算力的高速公路
NVMe over Fabrics的优势是什么?
基于英特尔®AGILEX™ FPGA和SOC FPGA的BittWare加速“双星”发布
BittWare合作者及创新者的生态系统为基于FPGA解决方案降低创新风险
在ZCU102评估套件上实现NVMe SSD接口的解决方案
Bittware提供开放式FPGA堆栈和支持英特尔®oneAPI的加速卡

存储技术未来演进:NVMe over Fabrics (NVMeoF)




评论