 基于Entity-Linking及基于Retreval的方法
基于Entity-Linking及基于Retreval的方法

NLP预训练模型需要非常大的参数量以及非常多的语料信息,这些都是希望能尽可能多的记住文本中的知识,以此提升下游任务效果。相比而言,直接从数据库、知识图谱、搜索引擎等引入外部知识进行知识增强,是一种更直接、节省资源的方法。知识增强也是NLP未来的重要发展方向,由于在NLU这种需要理解、常识性知识的领域,知识增强更加重要。
ACL 2022的一篇Tutorial:Knowledge-Augmented Methods for Natural Language Understanding,对知识增强在NLU中的方法进行了详细汇总。本文整理了这篇Tutorial中重点介绍知识增强模型的10篇工作,包括基于Entity-Linking的方法以及基于Retreval的方法两大类。
Entity-Linking based methodsERNIE: Enhanced Language Representation with Informative Entities(ACL 2019)
ERNIE利用知识图谱中的实体信息给BERT模型引入外部知识,提升预训练语言模型效果。模型主要包括Text-Encoder和Knowledge-Encoder两个部分。在输入部分,除了原始的文本维度embedding,还会引入实体embedding,实体embedding利用TrasE算法基于知识图谱进行预训练。Text-Encoder和BERT相同,对原始的文本输入进行处理生成文本表示。Knowledge-Encoder将文本和对应位置的entity表示进行融合,得到实体知识增强的表示。Knowledge-Encoder的整个计算过程如下图,首先利用两个独立的multi-head attention生成文本word embedding和entity embedding,再将实体和对应位置的文本进行对齐,输入到融合层,再通过融合层生成新的word embedding和entity embedding,这样循环多层得到最终结果。
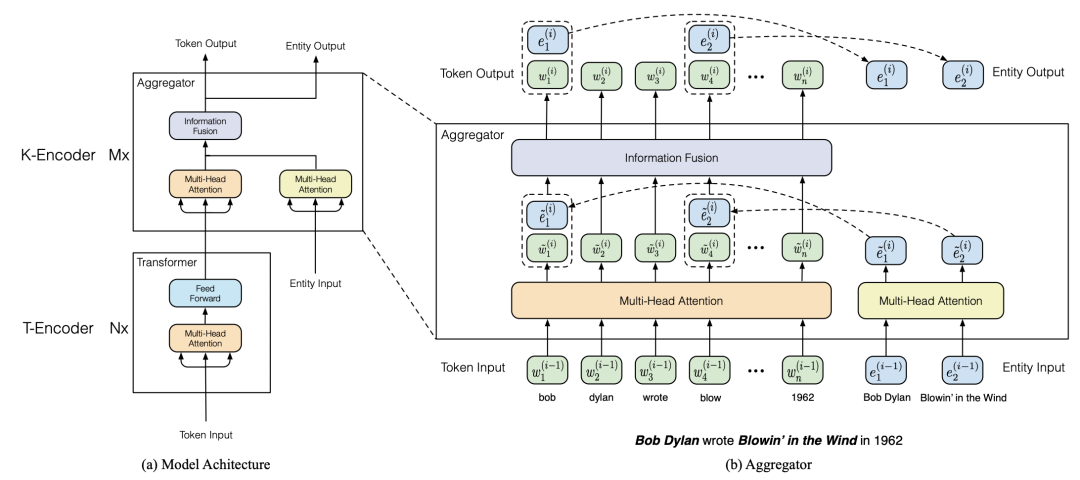
在预训练阶段,ERNIE增加了一个entity denoising的任务:mask掉或者随机打乱某些word和entity之间的对齐关系,让模型去预测。这种预训练任务起到了将实体知识融入到语言模型中的作用。
KEAR: Augmenting Self-Attention with External Attention(IJCAI 2022)
为了让Transformer存储更多的知识来提升下游任务效果,一般都会采用更大的模型尺寸、更多的训练数据。而KEAR提出引入外部知识的方法,这样即使在中等尺寸的Transformer上也能由于这些外部知识增益带来显著效果提升。
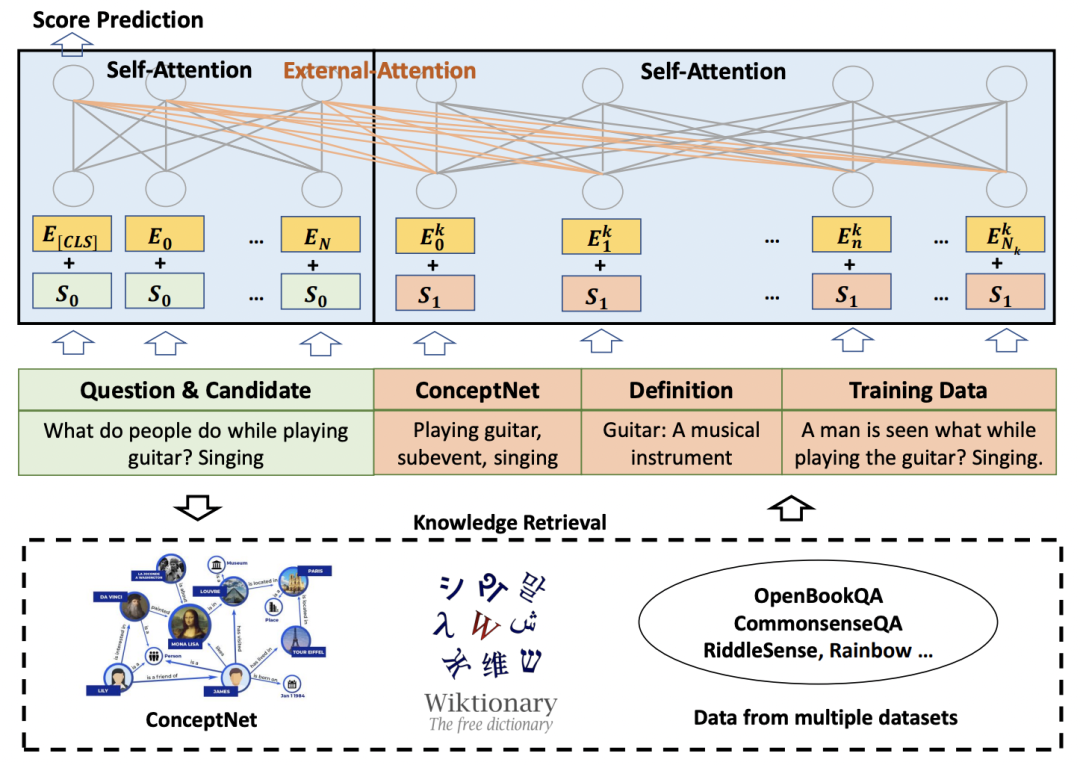
本文主要关注QA任务,给定一个问题和一组答案,从中选择正确答案。模型的结构比较简单,将输入的文本,以及从各种外部知识库中检索到和原始输入相关的知识信息,都以文本的形式拼接到一起,输入到Transformer中。
外部知识主要来源于三个渠道,第一个渠道是知识图谱,从问题和答案中提取entity,然后从ConcepNet中提取包含对应entity的三元组;第二个渠道是从字典中检索相应实体的描述性定义,来弥补模型对于低频词的embedding可能学的不好的情况;第三个渠道是从训练数据中检索和当前输入相关的信息作为补充,缓解模型由于对某些训练数据中的信息记忆不全导致的信息缺失。
Entities as Experts: Sparse Memory Access with Entity Supervision(2020,EaE)
这篇文章在Transformer模型中引入了一个Entity Memory Layer组件,用来从已经训练好的entity embedding memory中引入和输入相关的外部知识。Entity Memory Layer模块可以非常灵活的嵌套在Transformer等序列模型中。
具体做法为,首先要有一个已经训练好的entity embedding存储起来。在Transformer的一层输出结果后,对于输入文本中的每个entity mention,使用这个entity span的起始位置和终止位置的embedding拼接+全连接得到一个虚拟的entity embedding。利用这个虚拟的entity embedding去entity embedding memory中,利用内积检索出最相关的top K个实体的embedding,最后加权融合,得到这个entity对应的实体表示,公式如下。这个表示会和Transformer上层输入融合,作为下一层的输入。
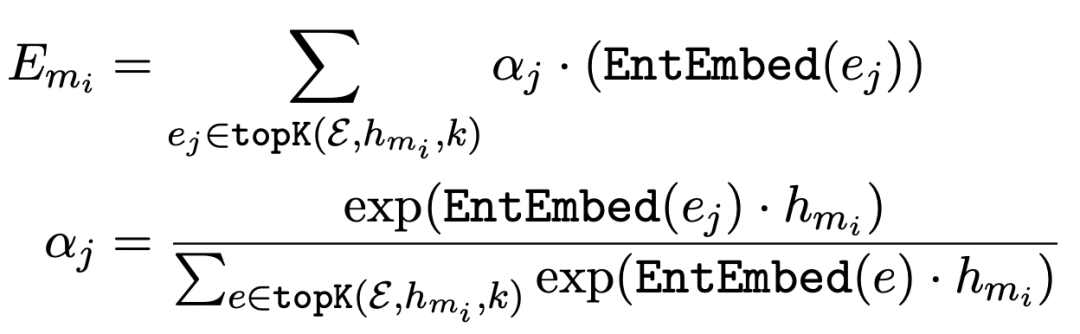
预训练任务除了MLM外,还包括Mention Detection和Entity Linking两个优化任务。其中,Mention Detection用来预测每个实体的start和end,采用BIO classification的方式;而Entity Limking任务主要为了拉近Transformer生成的虚拟entity embedding和其对应的entity embedding memory的距离。
FILM: Adaptable and Interpretable Neural Memory Over Symbolic Knowledge(NAACL 2021)
FILM在上一篇文章中的entity embedding memory基础上,引入了Fact Memory模块,entity embedding layer部分的实现和EaE中相同。
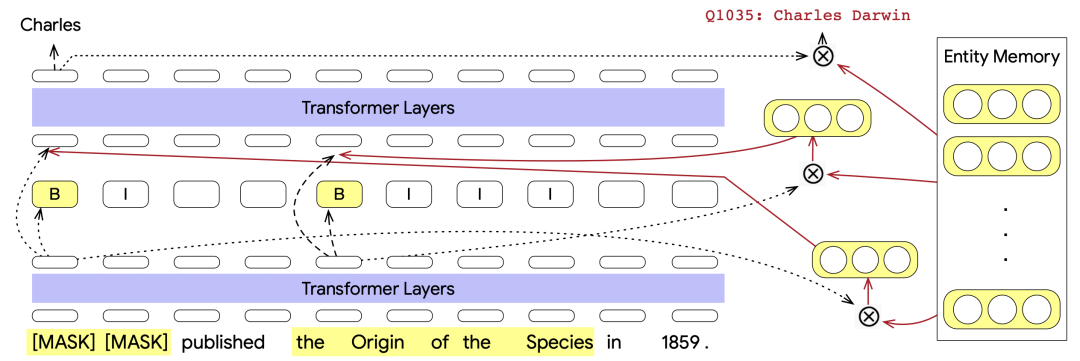
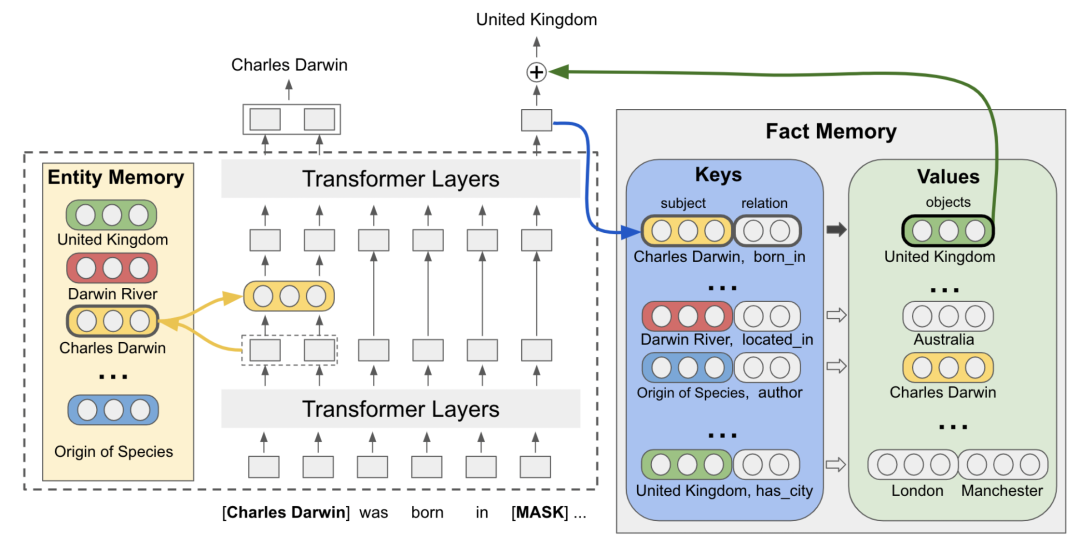
Fact Memory模块和Entity Memory使用的是相同的embedding。Fact Memory模块由Keys和Values两个部分组成,Keys对应的是知识图谱中的subject和relation,而Values是同一个subject和relation下的所有object的集合。使用subject和relation的表示拼接转换得到每个Keys的embedding表示。当需要预测输入文本被mask部分的答案时,使用Transformer在mask位置生成的embedding作为query,在Fact Memory中和各个Keys的embedding做内积,检索相关的object。这些检索出的object信息的embedding会和被mask部分的embedding融合,用于进行答案的预测。
下图是一个例子,被mask部分的embedding包含了句子中的关键信息,利用该embedding在fact memory中可以实现相关信息的检索,对于QA有比较大的帮助。
K-BERT: Enabling Language Representation with Knowledge Graph(2019)
K-BERT首先将输入文本的实体识别出来,然后去知识图谱中搜索和该实体相关的子图,用这个子图插入到输入句子的对应位置,形成一个句子树。比如下面的图中,Tim Cook从知识图谱检索出是苹果CEO,就将对应文本插入到Tim Cook后面的位置。
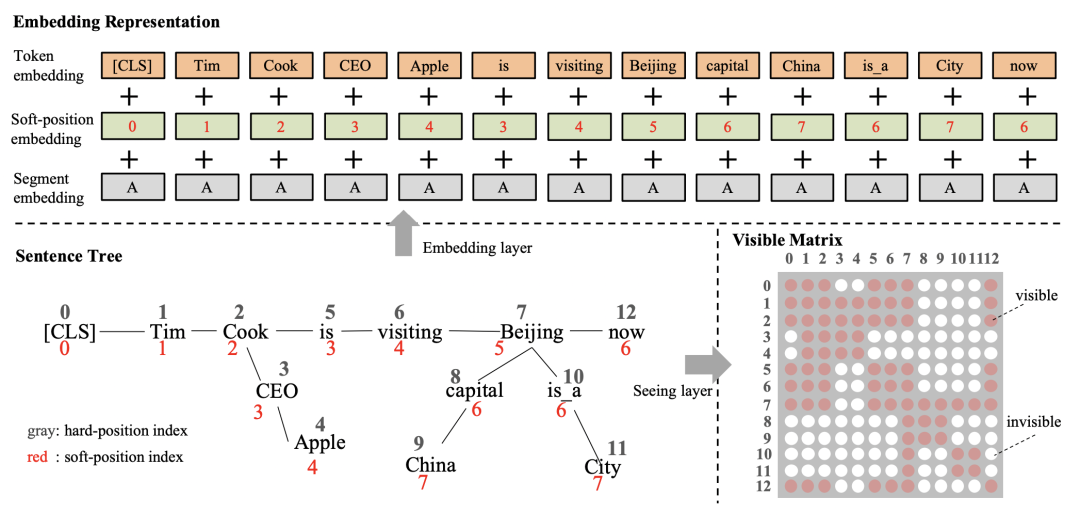
一个核心问题在于,新引入的知识图谱文本会影响原来输入句子的语义。另外,文中采用的是将知识图谱引入的文本直接插入到对应实体后面,其他文本位置对应后移,如何设置position embedding也是个问题。如果直接按照顺序设定position embedding,会让原本距离比较近的单词之间的position embedding变远,也会影响原始语义。为了解决这个问题,插入的知识图谱文本不会影响原来句子各个单词的posistion编号。同时引入了Visible Matrix,让原始输入中和引入的知识信息不相关的文本在计算attention时不可见。通过这种方式,引入的知识信息只会直接影响与其相关的实体的表示生成,不会直接影响原始句子中其他文本的表示生成。引入的知识通过影响对应实体的表示生成,间接影响其他文本的表示生成过程。
2
Retrieval based methodsDense Passage Retrieval for Open-Domain Question Answering(2020)
这篇文章采用的是一种最基础的基于检索的QA解决方法。离线训练一个passage encoder和一个question encoder,目标是让question和包含其答案的passage的表示的内积最大。训练过程中的负样本构造采用了随机采样、BM25和question高相关性但不包含答案的passage、训练样本中包含答案但不包含当前question答案的passage三种方法。在在线使用时,通过计算question和passage表示内积的方式,检索出高相关性的passage解析出问题答案。
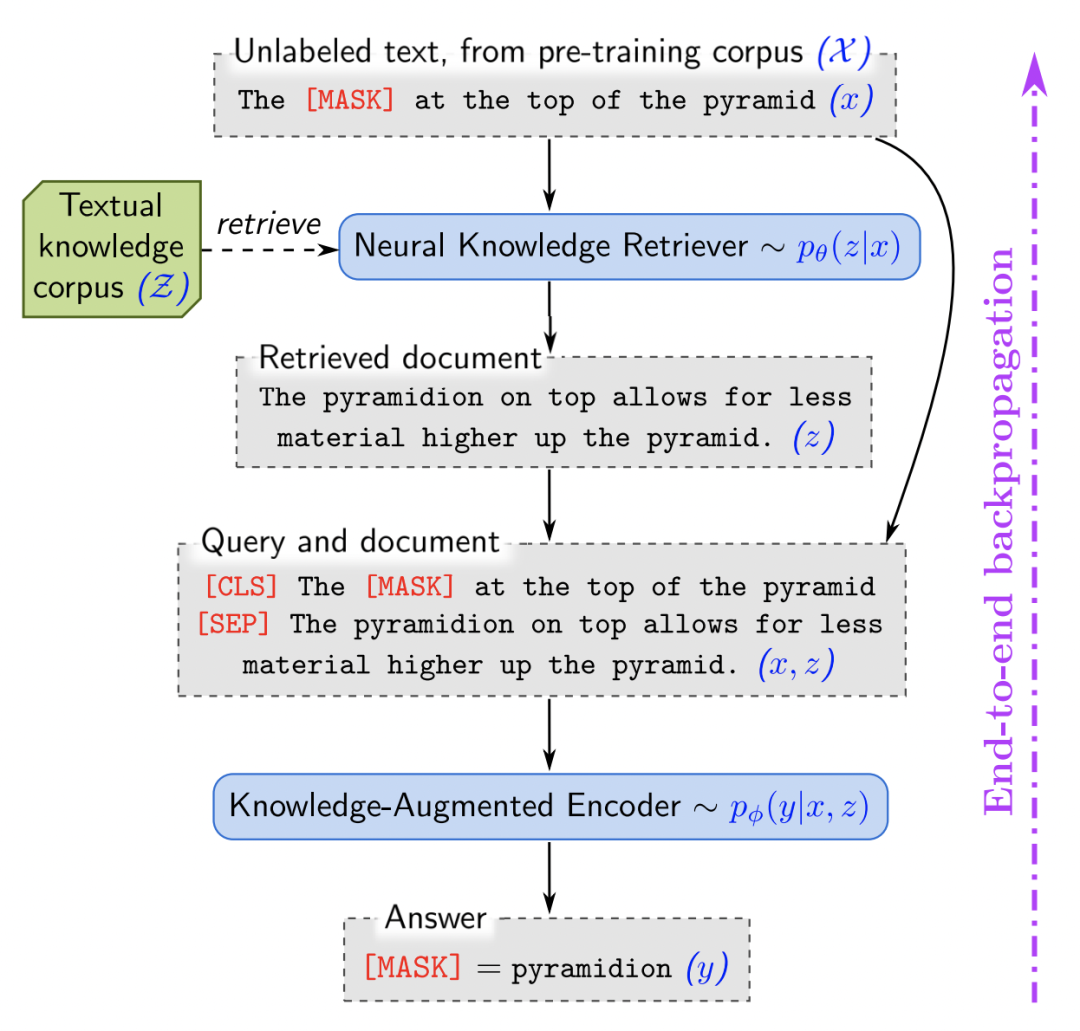
REALM: Retrieval-Augmented Language Model Pre-Training(2020)
REALM在预训练语言模型中引入了外部知识检索模块,让模型在进行预测时,不仅能够根据自身参数保存的信息,也能根据丰富的外部信息给出答案。整个预测过程包括两个部分:检索阶段和预测阶段。检索阶段根据输入句子从外部知识中检索相关的文档;预测阶段根据输入句子以及检索到的信息进行最终结果的预测。
在检索阶段,跟上一篇文章类似,使用预训练的两个BERT的表示计算内积求得输入和各个文档的相关性,并进行高相关文档的检索。检索到的文档和原始输入拼接到一起,输入到BERT模型中进行结果预测。
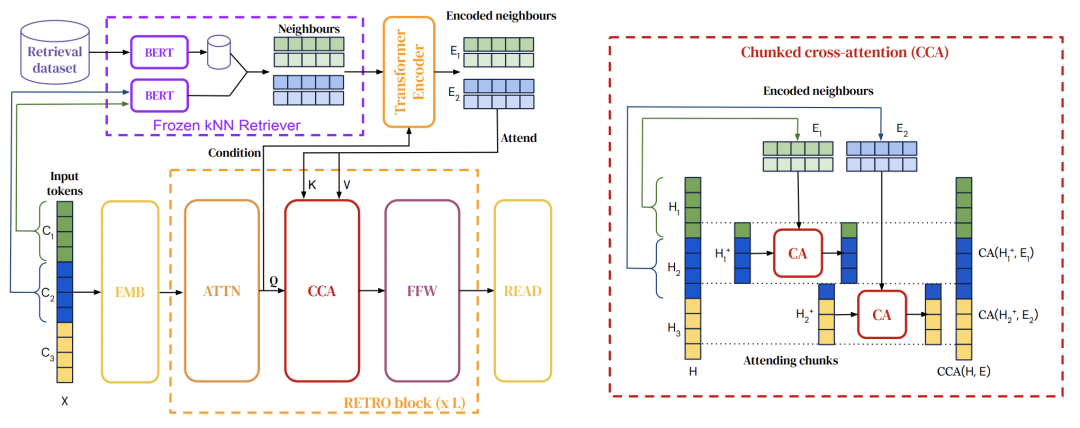
RETRO: Improving language models by retrieving from trillions of tokens(2022)
RETRO相比REALM,采用的是chunks维度的检索。首先构造一个数据库,存储文本chunks以及它们的embedding,embedding是由一个预训练BERT产出的。接下来在训练语言模型时,对于每个输入文本,将其切分成多个chunk,每个chunk利用向量检索从数据库中检索出k个最近邻chunks。这些被检索出来的相关chunks会利用attention和原始输入进行融合,增强原始输入信息。原始输入的每个chunk都和该chunk检索出的chunks以及其邻居检索出的chunks进行attention。
WebGPT: Browser-assisted question-answering with human feedback(2022)
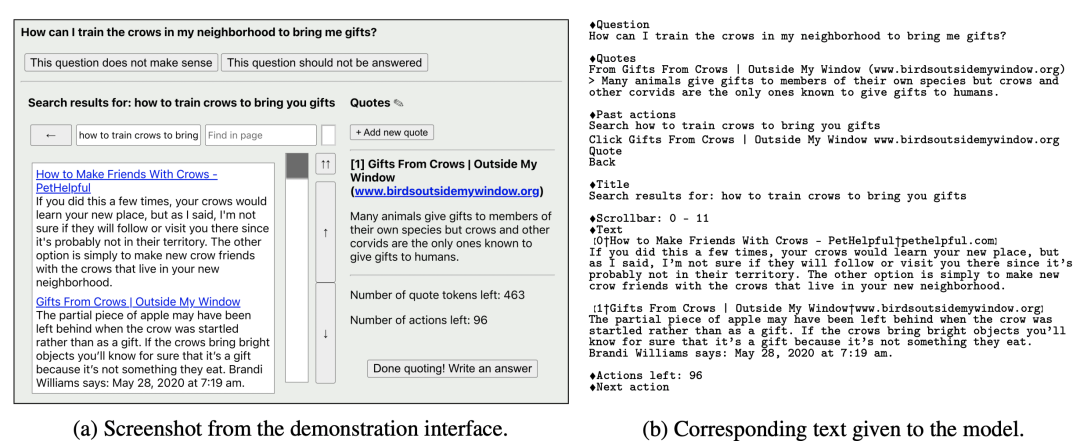
WebGPT实现了利用GPT模型使用搜索引擎检索答案。人们在浏览器中搜索的操作可以表述成例如下面的这些文本。预先定义一些下表中的command,训练GPT模型让它根据已经进行的搜索操作,生成下一个command。这个过程一直执行到某个终止条件位置(例如生成end command、执行次数超过一定长度)。某些command代表着采用这些文档作为reference。在执行完所有command后,根据收集到的reference以及问题,生成最终的答案。比如下图b中就是已经执行的command以及问题等信息,这些信息组成了当前搜索的上下文,以文本形式输入GPT中,让模型生成下一个command。

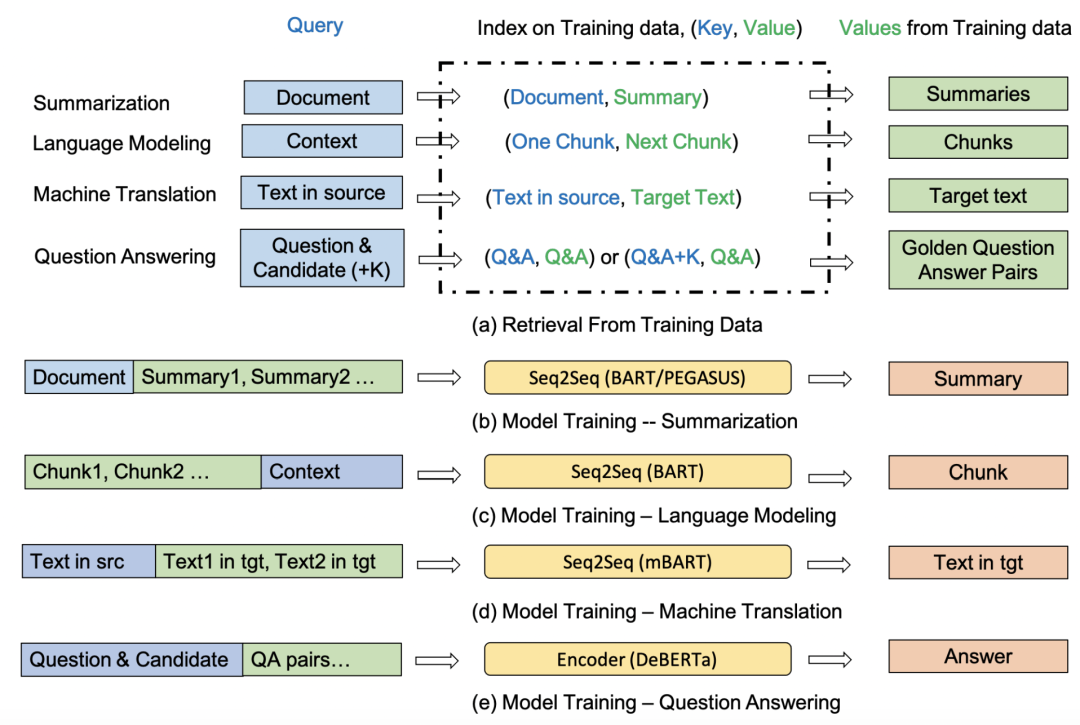
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data(2022)
这篇文章通过检索+拼接的方法扩充原始输入文本的信息,提升多项任务上的效果。整个检索过程在训练数据中进行,将训练数据构造成key-value对。对于输入样本,从训练数据中检索出高相关性的样本,作为知识信息拼接到原始输入中。不同任务会采用不同的检索对象以及拼接方法,如下图。
3
总结知识增强方法是解决自然语言理解的核心方法,重点在于研究从哪获取知识、如何获取知识以及如何融合知识。使用知识增强的方法可以帮助模型更直接获取预测需要用到的外部知识,也能缓解需要越来越大的预训练模型提升下游任务效果的问题。知识增强+预训练语言模型起到互补的作用,知识增强方法可以给模型提供预训练阶段没见过或者忘记的信息,提升预测效果。
原文标题:ACL 2022 Tutorial解析——知识增强自然语言理解
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
模型
+关注
关注
1文章
3818浏览量
52268 -
nlp
+关注
关注
1文章
491浏览量
23345 -
知识图谱
+关注
关注
2文章
132浏览量
8356
原文标题:ACL 2022 Tutorial解析——知识增强自然语言理解
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
开通App Linking服务
不同电缆局放检测方法的应用特点
微电网暂态稳定分析方法有哪些?

按键消抖的方法
利用软件的方法解决EMC问题

使用jQuery的常用方法与返回值分析
studio编译过程中报错:syntax error: unexpected如何解决?
车机DAB功能验证方法论及测试三神器简介



评论