 4nm、5nm,那些用上先进工艺的RISC-V处理器
4nm、5nm,那些用上先进工艺的RISC-V处理器

无论是x86、Arm还是新秀RISC-V,大家谈及基于这些架构的处理器时,除了对比性能、功耗以外,不免会说到造就当下处理器差异化的另一大因素,那就是制造工艺。台积电、中芯国际、三星还有英特尔,随着如今几乎所有代工厂都参与到RISC-V的制造中来,我们不妨挑几个用上了先进工艺的RISC-V处理器看看。
台积电5nm+HBM3的RISC-V处理器
去年,SiFive旗下的OpenFive,一个用差异化IP提供定制方案的业务部门宣布正式流片了基于台积电5nm工艺的RISC-V处理器,该处理器集成的IP方案主要面向高性能计算/AI、网络与存储应用。
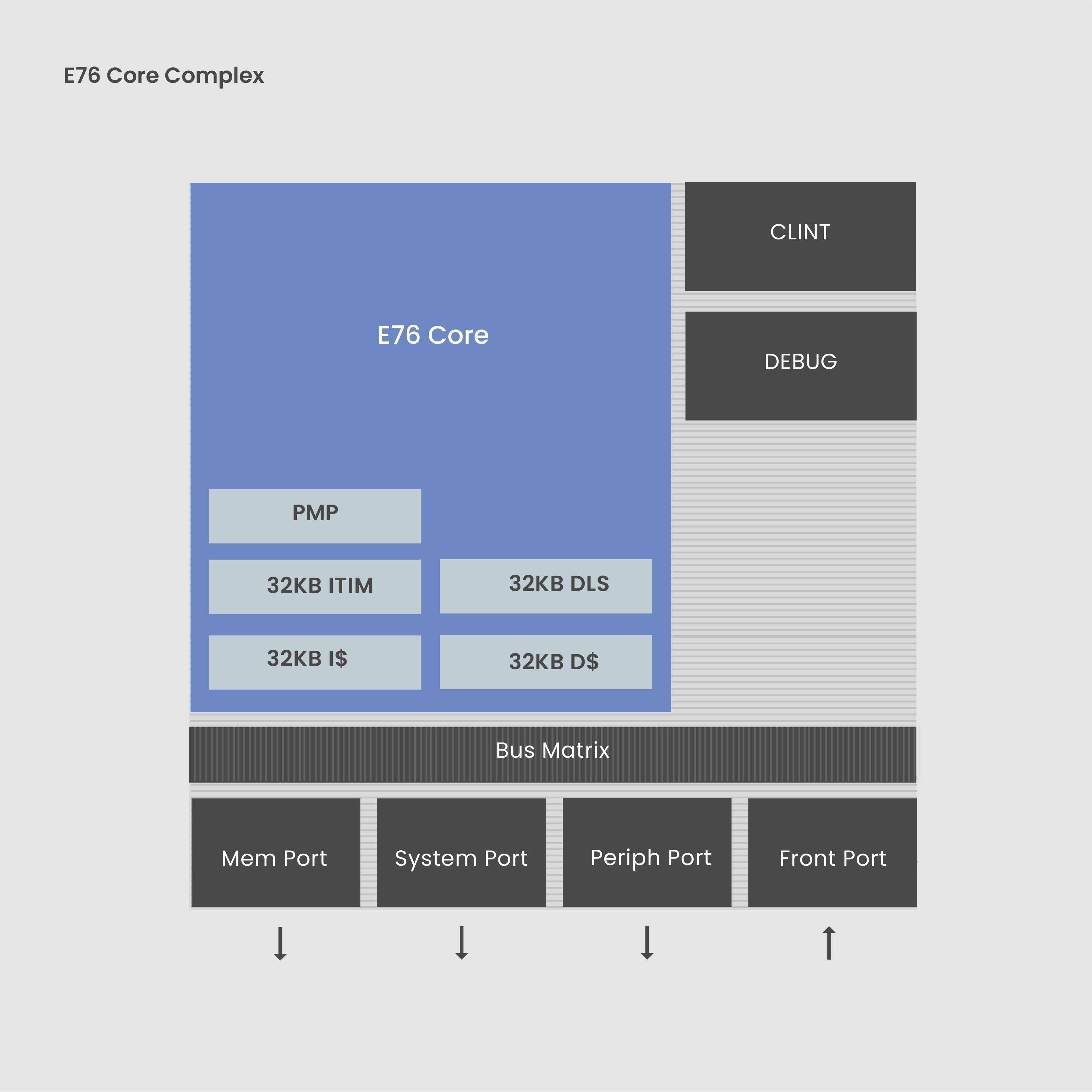
E76核心框图/ SiFive
这款SoC用到了OpenFive的HBM3 IP子系统和D2D I/O,CPU核心则选用了SiFive的E76,8级流水线的32位RISC-V核心。其HBM3接口给到了7.2Gbps的速度,足以满足任何计算密集型应用特定领域加速器的带宽需求。在D2D接口技术的支持下,该SoC可以通过2.5D封装实现更高的性能、更低的功耗与延迟。当然了,更重要的还是E76这个5.69CoreMark/Hz的RISC-V CPU核心。
不难看出,SiFive在高性能计算上有着自己的野心,哪怕目前Alphawave已经收购了SiFive的OpenFive业务部门。从SiFive和英特尔的关系来看,双方未来也会和继续合作,借助英特尔的IFS代工业务,为RISC-V处理器提供更先进的制造工艺,正如下面我们要提到的这款RISC-V处理器一样。
以Intel4打造的近缓存计算RISC-V处理器
在我们已经看到的不少RISC-V处理器中,除了低功耗的以外,也有不少高性能的处理器,尤其是与AI/ML相关的。深度学习激发了一批数据并行的工作负载,而传统的SIMD处理器虽然解决了更多通用算力的问题,但其内存带宽还是无法这类应用的要求,这也是为何GPU和一众加速器在AI/ML上更受欢迎的原因。
在今年的VLSI22上,英特尔的研究工程师们带来了一个新的演示分享,一个全新的8核64位RISC-V处理器,代号Vela。该芯片完全基于Intel4的CMOS工艺打造。在这一先进工艺的助力下,这个频率为1.15GHz的处理器仅仅占用了1.92mm2的面积,同时集成了512kB的共享LLC,每个核心分配了64kB SRAM。最关键的是Vela应用了近缓存计算(CNC)技术,使得该处理器在深度学习负载上展现了极佳的性能。
CNC不仅实现了高带宽的访问,也实现了在大容量片上SRAM中直接进行本地计算。而Vela将虚拟寻址,连贯性和一致性一并扩张到了CNC上,实现了可允许在Linux下的多核操作。与此同时,这个倒转芯片封装设计的处理器与一个FPGA相连,作为一个用于访问DRAM和IO的芯片组。
英特尔在分享中展示了CNC LLC的数据路径、CNC ISA规范以及编程模型,实际工作负载演示则为DNN提供了视觉化输入与输出。与将数据从LLC移动到核心内不同,CNC将成绩累加运算搬到了LLC上,就地处理数据。如此一来避免了片上网络的带宽瓶颈,同时减少全局数据的移动,增加了吞吐量提高了能效。英特尔的研究员也给出了具体提升数据,与标量处理相比,其吞吐量提升了46倍;通过减少数据移动,其整体功耗降低了11%,推理功耗降低至52分之一;在MLPerf的异常检测测试中,Vela将延迟降低了4.25倍,低至40μs。
不少人猜测这会不会是SiFive与英特尔打造的HorseCreek平台,毕竟该平台用到的也是英特尔的7nm工艺(Intel4)。不过在英特尔和SiFive双方去年的声明中,都提到了HorseCreek将使用SiFive的P550核心,一个13级流水线三发射的高性能RISC-V核心。但从其1.15GHz的频率和1.92mm2的面积来看,很可能不是,至少不会是完整的HorseCreek。
结语
其实要说现在RISC-V处理器所用的工艺,还是7nm和之前的成熟工艺居多,毕竟RISC-V现在软硬件生态都还在高速发展中,并没有选择与Arm或x86在通用CPU和手机SoC上硬碰硬。也许RISC-V不像Arm的公版核心一样,有那么清晰的定位,但可以预见RISC-V未来覆盖的市场很快就会与Arm重合,所用工艺的差距也将缩小,届时观察各大半导体厂商的选择才更有趣。
台积电5nm+HBM3的RISC-V处理器
去年,SiFive旗下的OpenFive,一个用差异化IP提供定制方案的业务部门宣布正式流片了基于台积电5nm工艺的RISC-V处理器,该处理器集成的IP方案主要面向高性能计算/AI、网络与存储应用。
E76核心框图/ SiFive
这款SoC用到了OpenFive的HBM3 IP子系统和D2D I/O,CPU核心则选用了SiFive的E76,8级流水线的32位RISC-V核心。其HBM3接口给到了7.2Gbps的速度,足以满足任何计算密集型应用特定领域加速器的带宽需求。在D2D接口技术的支持下,该SoC可以通过2.5D封装实现更高的性能、更低的功耗与延迟。当然了,更重要的还是E76这个5.69CoreMark/Hz的RISC-V CPU核心。
不难看出,SiFive在高性能计算上有着自己的野心,哪怕目前Alphawave已经收购了SiFive的OpenFive业务部门。从SiFive和英特尔的关系来看,双方未来也会和继续合作,借助英特尔的IFS代工业务,为RISC-V处理器提供更先进的制造工艺,正如下面我们要提到的这款RISC-V处理器一样。
以Intel4打造的近缓存计算RISC-V处理器
在我们已经看到的不少RISC-V处理器中,除了低功耗的以外,也有不少高性能的处理器,尤其是与AI/ML相关的。深度学习激发了一批数据并行的工作负载,而传统的SIMD处理器虽然解决了更多通用算力的问题,但其内存带宽还是无法这类应用的要求,这也是为何GPU和一众加速器在AI/ML上更受欢迎的原因。

在今年的VLSI22上,英特尔的研究工程师们带来了一个新的演示分享,一个全新的8核64位RISC-V处理器,代号Vela。该芯片完全基于Intel4的CMOS工艺打造。在这一先进工艺的助力下,这个频率为1.15GHz的处理器仅仅占用了1.92mm2的面积,同时集成了512kB的共享LLC,每个核心分配了64kB SRAM。最关键的是Vela应用了近缓存计算(CNC)技术,使得该处理器在深度学习负载上展现了极佳的性能。
CNC不仅实现了高带宽的访问,也实现了在大容量片上SRAM中直接进行本地计算。而Vela将虚拟寻址,连贯性和一致性一并扩张到了CNC上,实现了可允许在Linux下的多核操作。与此同时,这个倒转芯片封装设计的处理器与一个FPGA相连,作为一个用于访问DRAM和IO的芯片组。
英特尔在分享中展示了CNC LLC的数据路径、CNC ISA规范以及编程模型,实际工作负载演示则为DNN提供了视觉化输入与输出。与将数据从LLC移动到核心内不同,CNC将成绩累加运算搬到了LLC上,就地处理数据。如此一来避免了片上网络的带宽瓶颈,同时减少全局数据的移动,增加了吞吐量提高了能效。英特尔的研究员也给出了具体提升数据,与标量处理相比,其吞吐量提升了46倍;通过减少数据移动,其整体功耗降低了11%,推理功耗降低至52分之一;在MLPerf的异常检测测试中,Vela将延迟降低了4.25倍,低至40μs。
不少人猜测这会不会是SiFive与英特尔打造的HorseCreek平台,毕竟该平台用到的也是英特尔的7nm工艺(Intel4)。不过在英特尔和SiFive双方去年的声明中,都提到了HorseCreek将使用SiFive的P550核心,一个13级流水线三发射的高性能RISC-V核心。但从其1.15GHz的频率和1.92mm2的面积来看,很可能不是,至少不会是完整的HorseCreek。
结语
其实要说现在RISC-V处理器所用的工艺,还是7nm和之前的成熟工艺居多,毕竟RISC-V现在软硬件生态都还在高速发展中,并没有选择与Arm或x86在通用CPU和手机SoC上硬碰硬。也许RISC-V不像Arm的公版核心一样,有那么清晰的定位,但可以预见RISC-V未来覆盖的市场很快就会与Arm重合,所用工艺的差距也将缩小,届时观察各大半导体厂商的选择才更有趣。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
英特尔
+关注
关注
61文章
10324浏览量
181098 -
台积电
+关注
关注
44文章
5812浏览量
177058 -
RISC-V
+关注
关注
49文章
2952浏览量
53559
发布评论请先 登录
相关推荐
热点推荐
新思科技ImperasDV解决方案让RISC-V处理器验证效率翻倍
由于 RISC-V 是一个开放性的 ISA,它允许任何开发者自由设计和扩展定制处理器。基于 RISC-V 的处理器必须保持与不断增长的支持工具和软件生态系统的兼容性。
新思科技ARC-V处理器驱动RISC-V市场无限机遇
从 2010 年美国加州大学伯克利分校的教授与他的研究生团队耗时三个月完成 RISC-V 指令集的开发工作,到 2015 年,RISC-V 在学术界声名鹊起,再到 2025 年成为主流架构之一

Banana Pi BPI-CM6 计算模块将 8 核 RISC-V 处理器带入 CM4 外形尺寸
配备了一颗 8 核 SpacemiT K1 RISC-V 处理器,主频约为 1.6 GHz,以及 8 GB LPDDR4 内存(最大容量可达 16 GB)。此外,它还配备了多种板载 eMMC 存储方案
发表于 12-20 09:01
直播预约 |开源芯片系列讲座第30期:“一生一芯”计划——从零开始设计自己的RISC-V处理器芯片
鹭岛论坛开源芯片系列讲座第30期「“一生一芯”计划从零开始设计自己的RISC-V处理器芯片」11月17日(周三)20:00精彩开播期待与您云相聚,共襄学术盛宴!|直播信息报告题目“一生一芯”计划

为什么RISC-V是嵌入式应用的最佳选择
最近RISC-V基金会在社交媒体上发文,文章说物联网和嵌入式系统正在迅速发展,需要更高的计算性能、更低的功耗和人工智能。RISC-V是为未来而建的,包括超高效的MCU到高性能应用处理器,RIS
基于E203 RISC-V的音频信号处理系统 -协处理器的乘累加过程
协处理器简介
RISC-V具有很高的可扩展性,既预留出了指令编码空间,也提供了预定义的Custom指令;RISC-V的标准指令集仅使用了少部分指令编码空间,更多的指令编码空间被预留给用户进行扩展
发表于 10-28 06:18
明晚开播 |开源芯片系列讲座第28期:高性能RISC-V微处理器芯片
鹭岛论坛开源芯片系列讲座第28期「高性能RISC-V微处理器芯片」明晚(30日)20:00精彩开播期待与您云相聚,共襄学术盛宴!|直播信息报告题目高性能RISC-V微处理器芯片报告简介
睿思芯科携灵羽处理器亮相2025 RISC-V中国峰会
第五届RISC-V中国峰会于16日在上海张江开幕,会上睿思芯科展示了中国首款全自研高性能RISC-V服务器处理器——灵羽处理器,凭借全栈自主
知合计算:RISC-V架构创新,阿基米德系列剑指高性能计算
在2025 RISC-V中国峰会上,知合计算处理器设计总监刘畅就高性能RISC-V处理器架构探索与实践进行了精彩分享。 在以X86和ARM为代表的处

直播预约 |开源芯片系列讲座第28期:高性能RISC-V微处理器芯片
鹭岛论坛开源芯片系列讲座第28期「高性能RISC-V微处理器芯片」7月30日(周三)20:00精彩开播期待与您云相聚,共襄学术盛宴!|直播信息报告题目高性能RISC-V微处理器芯片报告
沁恒微电子:从互连互通应用推动RISC-V落地发展
沁恒微电子邀您共襄盛举沁恒微电子专注于连接技术和微处理器内核研究,基于多层次青稞RISC-V微处理器、多类型物理层收发器构建USB/蓝牙/以太网接口芯片和青稞
RISC-V和ARM有何区别?
在微处理器架构领域,ARM与RISC-V是两个备受关注的体系。ZLG致远电子在推出ARM核心版后,又推出了基于RISC-V的MR6450核心版,这引发了人们对这两种架构差异的深入探讨。ARM

HPM5E31IGN单核 32 位 RISC-V 处理器
HPM5E31IGN单核 32 位 RISC-V 处理器在当今嵌入式系统领域,RISC-V架构正以开源、灵活和高性价比的优势快速崛起。HPM5
发表于 05-29 09:23
HXS320F28027数字信号处理器(32位RISC-V DSP)
HXS320F28027数字信号处理器(32位RISC-V DSP)HXS320F28027是中科昊芯(Haawking)基于自主研发的H28x内核推出的32位定点RISC-V DSP架构数字信号
发表于 05-21 10:21
Condor使用Cadence托管云服务开发高性能RISC-V微处理器
Condor 是一家美国初创企业,致力于开发高性能 RISC-V 微处理器。公司的目标是通过创新技术彻底革新整个行业,打破高性能计算的极限。



评论