 使用NVIDIA QAT工具包实现TensorRT量化网络的设计
使用NVIDIA QAT工具包实现TensorRT量化网络的设计

出身背景
加速深层神经网络( DNN )推理是实现实时应用(如图像分类、图像分割、自然语言处理等)延迟关键部署的重要步骤。
改进 DNN 推理延迟的需要引发了人们对以较低精度运行这些模型的兴趣,如 FP16 和 INT8 。在 INT8 精度下运行 DNN 可以提供比其浮点对应项更快的推理速度和更低的内存占用。 NVIDIA TensorRT 支持训练后量化( PTQ )和 QAT 技术,将浮点 DNN 模型转换为 INT8 精度。
在这篇文章中,我们讨论了这些技术,介绍了用于 TensorFlow 的 NVIDIA QAT 工具包,并演示了一个端到端工作流,以设计最适合 TensorRT 部署的量化网络。
量化感知训练
QAT 背后的主要思想是通过最小化训练期间的量化误差来模拟低精度行为。为此,可以通过在所需层周围添加量化和去量化( QDQ )节点来修改 DNN 图。这使得量化网络能够将由于模型量化和超参数的微调而导致的 PTQ 精度损失降至最低。
另一方面, PTQ 在模型已经训练之后,使用校准数据集执行模型量化。由于量化没有反映在训练过程中,这可能导致精度下降。图 1 显示了这两个过程。
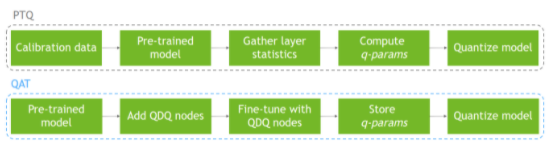
图 1 通过 PTQ 和 QAT 的量化工作流
用于 TensorFlow 的 NVIDIA QAT 工具包
该工具包的目标是使您能够以最适合于 TensorRT 部署的方式轻松量化网络。
目前, TensorFlow 在其开源软件 模型优化工具包 中提供非对称量化。他们的量化方法包括在所需层的输出和权重(如果适用)处插入 QDQ 节点,并提供完整模型或部分层类类型的量化。这是为 TFLite 部署而优化的,而不是 TensorRT 部署。
需要此工具包来获得一个量化模型,该模型非常适合 TensorRT 部署。 TensorRT optimizer 传播 Q 和 DQ 节点,并通过网络上的浮点操作将它们融合在一起,以最大化 INT8 中可以处理的图形比例。这将导致 NVIDIA GPU 上的最佳模型加速。我们的量化方法包括在所需层的输入和权重(如果适用)处插入 QDQ 节点。
我们还执行对称量化( TensorRT 使用),并通过层名称和 基于模式的层量化 的部分量化提供扩展量化支持。
表 1 总结了 TFMOT 和用于 TensorFlow 的 NVIDIA QAT 工具包之间的差异。

图2显示了一个简单模型的前/后示例,用 Netron 可视化。QDQ节点放置在所需层的输入和权重(如适用)中,即卷积(Conv)和完全连接(MatMul)。
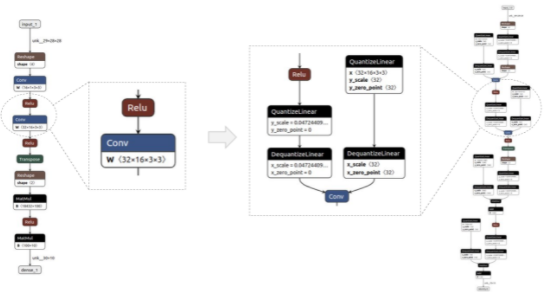
图 2 量化前后的模型示例(分别为基线和 QAT 模型)
TensorRT 中部署 QAT 模型的工作流
图 3 显示了在 TensorRT 中部署 QAT 模型的完整工作流,该模型是通过 QAT 工具包获得的。

图 3 TensorRT 使用 QAT 工具包获得的 QAT 模型的部署工作流
假设预训练的 TensorFlow 2 模型为 SavedModel 格式,也称为基线模型。
使用quantize_model功能对该模型进行量化,该功能使用 QDQ 节点克隆并包装每个所需的层。
微调获得的量化模型,在训练期间模拟量化,并将其保存为SavedModel格式。
将其转换为 ONNX 。
然后, TensorRT 使用 ONNX 图来执行层融合和其他图优化,如 专用 QDQ 优化 ,并生成一个用于更快推理的引擎。
ResNet-50v1 示例
在本例中,我们将向您展示如何使用 TensorFlow 2 工具包量化和微调 QAT 模型,以及如何在 TensorRT 中部署该量化模型。有关更多信息,请参阅完整的 example_resnet50v1.ipynb Jupyter 笔记本。
要求
要跟进,您需要以下资源:
Python 3.8
TensorFlow 2.8
NVIDIA TF-QAT 工具包
TensorRT 8.4
准备数据
对于本例,使用 ImageNet 2012 数据集 进行图像分类(任务 1 ),由于访问协议的条款,需要手动下载。 QAT 模型微调需要此数据集,它还用于评估基线和 QAT 模型。
登录或注册链接网站,下载列车/验证数据。您应该至少有 155 GB 的可用空间。
工作流支持 TFRecord 格式,因此请使用以下说明(从 TensorFlow 说明 ) 转换下载的。将 ImageNet 文件转换为所需格式:
set IMAGENET_HOME=/path/to/imagenet/tar/files in data/imagenet_data_setup.sh 。
将 imagenet_to_gcs.py 下载到$IMAGENET_HOME。
Run 。/data/imagenet_data_setup.sh.
您现在应该可以在$IMAGENET_HOME中看到兼容的数据集。
量化和微调模型
from tensorflow_quantization import quantize_model from tensorflow_quantization.custom_qdq_cases import ResNetV1QDQCase # Create baseline model model = tf.keras.applications.ResNet50(weights="imagenet", classifier_activation="softmax") # Quantize model q_model = quantize_model(model, custom_qdq_cases=[ResNetV1QDQCase()]) # Fine-tune q_model.compile( optimizer="sgd", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=["accuracy"] ) q_model.fit( train_batches, validation_data=val_batches, batch_size=64, steps_per_epoch=500, epochs=2 ) # Save as TF 2 SavedModel q_model.save(“saved_model_qat”)
将 SavedModel 转换为 ONNX
$ python -m tf2onnx.convert --saved-model=--output= --opset 13
部署 TensorRT 发动机
将 ONNX 模型转换为 TensorRT 引擎(还可以获得延迟测量):
$ trtexec --onnx=--int8 --saveEngine= -v
获取验证数据集的准确性结果:
$ python infer_engine.py --engine=--data_dir= -b=
后果
在本节中,我们报告了 ResNet 和 EfficientNet 系列中各种型号的准确性和延迟性能数字:
ResNet-50v1
ResNet-50v2
ResNet-101v1
ResNet-101v2
效率网 -B0
效率网 -B3
所有结果都是在 NVIDIA A100 GPU 上获得的,批次大小为 1 ,使用 TensorRT 8.4 ( EA 用于 ResNet , GA 用于 EfficientNet )。
图 4 显示了基线 FP32 模型与其量化等效模型( PTQ 和 QAT )之间的精度比较。正如您所见,基线模型和 QAT 模型之间的准确性几乎没有损失。有时,由于模型的进一步整体微调,精度甚至更高。由于 QAT 中模型参数的微调, QAT 的精度总体上高于 PTQ 。
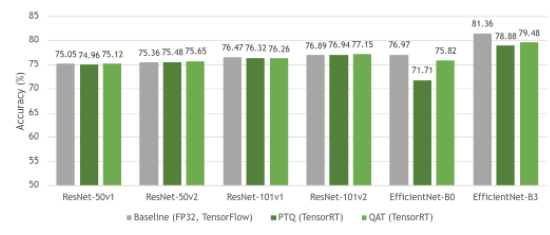
图 4 FP32 (基线)、带 PTQ 的 INT8 和带 QAT 的 INT8 中 ResNet 和 EfficientNet 数据集的准确性
ResNet 作为一种网络结构,一般量化稳定,因此 PTQ 和 QAT 之间的差距很小。然而, EfficientNet 从 QAT 中获益匪浅,与 PTQ 相比,基线模型的准确度损失有所减少。
有关不同模型如何从 QAT 中受益的更多信息,请参见 深度学习推理的整数量化:原理与实证评价 (量化白皮书)中的表 7 。
图 5 显示了 PTQ 和 QAT 具有相似的时间,与各自的基线模型相比,它们引入了高达 19 倍的加速。

图 5 ResNet 和 EfficientNet 系列中各种模型的延迟性能评估
PTQ 有时可能比 QAT 略快,因为它试图量化模型中的所有层,这通常会导致更快的推断,而 QAT 仅量化用 QDQ 节点包裹的层。
有关 TensorRT 如何使用 QDQ 节点的更多信息,请参阅 TensorRT 文档中的 使用 INT8 和 走向 INT8 推理:使用 TensorRT 部署量化感知训练网络的端到端工作流 GTC 会话。
有关各种受支持型号的性能数字的更多信息,请参阅 model zoo 。
结论
在本文中,我们介绍了 TensorFlow 2 的 NVIDIA QAT 工具包 。 我们讨论了在 TensorRT 推理加速环境中使用该工具包的优势。然后,我们演示了如何将该工具包与 ResNet50 结合使用,并对 ResNet 和 EfficientNet 数据集执行准确性和延迟评估。
实验结果表明,与 FP32 模型相比,用 QAT 训练的 INT8 模型的精度相差约 1% ,实现了 19 倍的延迟加速。
关于作者
Gwena Cunha Sergio 在 NVIDIA 担任深度学习软件工程师。在此之前,她是韩国京浦国立大学的一名博士生,致力于研究基于深度学习的方法,用于嘈杂的自然语言处理任务和从多模态数据生成序列。
Sagar Shelke 是 NVIDIA 的深度学习软件工程师,专注于自主驾驶应用程序。他的兴趣包括用于部署和机器学习系统的神经网络优化。萨加尔拥有圣地亚哥州立大学电气和计算机工程硕士学位。
Dheeraj Peri 在 NVIDIA 担任深度学习软件工程师。在此之前,他是纽约罗切斯特理工学院的研究生,致力于基于深度学习的内容检索和手写识别方法。 Dheeraj 的研究兴趣包括信息检索、图像生成和对抗性机器学习。他获得了印度皮拉尼 Birla 理工学院的学士学位。
Josh Park 是 NVIDIA 的汽车解决方案架构师经理。到目前为止,他一直在研究使用 DL 框架的深度学习解决方案,例如在 multi-GPUs /多节点服务器和嵌入式系统上的 TensorFlow 。此外,他一直在评估和改进各种 GPUs + x86 _ 64 / aarch64 的训练和推理性能。他在韩国大学获得理学学士和硕士学位,并在德克萨斯农工大学获得计算机科学博士学位
审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4842浏览量
108184 -
NVIDIA
+关注
关注
14文章
5694浏览量
110118
发布评论请先 登录
eIQ 工具包在 Ubuntu 22.04 中不起作用怎么解决?
破解RDMA网络“黑盒”:轻量化会话追踪工具

MinGW-w64工具集压缩包的下载
NVIDIA Spectrum-X以太网硅光技术助力AI工厂网络创新
NVIDIA TensorRT LLM 1.0推理框架正式上线
NVIDIA AI网络闪耀2025云栖大会
eForce无线通信软件开发工具包兼容WLAN模块WKR612AA1
TensorRT-LLM的大规模专家并行架构设计

DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

量化评估企业软件测试能力的评估工具包

NVIDIA RTX AI加速FLUX.1 Kontext现已开放下载
IQM 宣布 Resonance 量子云平台重大升级,推出全新软件开发工具包
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践




评论