 提高Kubernetes的GPU利用率
提高Kubernetes的GPU利用率

为了实现可扩展的数据中心性能, NVIDIA GPU 已成为必备产品。
NVIDIA GPU 由数千个计算核支持的并行处理能力对于加速不同行业的各种应用至关重要。目前,跨多个行业的计算密集型应用程序使用 GPU :
高性能计算,如航空航天、生物科学研究或天气预报
使用 AI 改进搜索、推荐、语言翻译或交通(如自动驾驶)的消费者应用程序
医疗保健,如增强型医疗成像
财务,如欺诈检测
娱乐,如视觉效果
此范围内的不同应用程序可能有不同的计算要求。训练巨型人工智能模型,其中 GPU 批处理并行处理数百个数据样本,使 GPU 在训练过程中得到充分利用。然而,许多其他应用程序类型可能只需要 GPU 计算的一小部分,从而导致大量计算能力的利用不足。
在这种情况下,为每个工作负载提供适当大小的 GPU 加速是提高利用率和降低部署运营成本的关键,无论是在本地还是在云中。
为了解决 Kubernetes ( K8s )集群中 GPU 利用率的挑战, NVIDIA 提供了多种 GPU 并发和共享机制,以适应广泛的用例。最新添加的是新的 GPU 时间切片 API ,现在在 Kubernetes 中广泛可用,具有 NVIDIA K8s 设备插件 0.12.0 和 NVIDIA GPU 操作符 1.11 。它们共同支持多个 GPU 加速工作负载的时间分割,并在单个 NVIDIA GPU 上运行。
在深入研究这一新功能之前,这里有一些关于您应该考虑共享 GPU 的用例的背景知识,并概述了所有可用的技术。
何时共享 NVIDIA GPU
以下是共享 GPU 资源以提高利用率的一些示例工作负载:
低批量推理服务 ,它只能在 GPU 上处理一个输入样本
高性能计算( HPC )应用 ,例如模拟光子传播,在 CPU (读取和处理输入)和 GPU (执行计算)之间平衡计算。由于 CPU 核心性能的瓶颈,一些 HPC 应用程序可能无法在 GPU 部分实现高吞吐量。
ML 模型探索的交互式开发 使用 Jupyter 笔记本电脑
基于 Spark 的数据分析应用程序 ,其中一些任务或最小的工作单元同时运行,并受益于更好的 GPU 利用率
可视化或脱机渲染应用程序 这可能是突发性的
希望使用任何可用的 GPU 进行测试的 连续集成/连续交付( CICD )管道
在本文中,我们将探讨在 Kubernetes 集群中共享 NVIDIA GPU 访问权限的各种技术,包括如何使用这些技术以及在选择正确方法时需要考虑的权衡。
GPU 并发机制
NVIDIA GPU 硬件结合 CUDA 编程模型,提供了许多不同的并发机制,以提高 GPU 的利用率。这些机制包括从编程模型 API (应用程序需要更改代码以利用并发)到系统软件和硬件分区(包括虚拟化),这对应用程序是透明的(图 1 )。
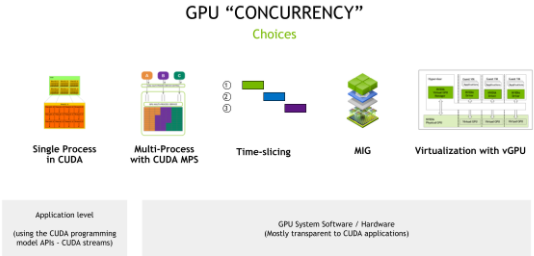
图 1 GPU 并发机制
CUDA 流
CUDA 的异步模型意味着您可以使用 CUDA 流,通过单个 CUDA 上下文(类似于 GPU 端的主机进程)并发执行许多操作。
流是一种软件抽象,它表示一系列命令,这些命令可能是按顺序执行的计算内核、内存拷贝等的组合。在两个不同流中启动的工作可以同时执行,从而实现粗粒度并行。应用程序可以使用 CUDA 流和 优先级 流管理并行性。
CUDA 流最大化了推理服务的 GPU 利用率,例如,通过使用流并行运行多个模型。您可以缩放相同的模型,也可以提供不同的模型。有关更多信息,请参阅 异步并发执行 。
与 streams 的权衡是,这些 API 只能在单个应用程序中使用,因此提供了有限的硬件隔离,因为所有资源都是共享的,并且可以在各种流之间进行错误隔离。
时间分片
在处理多个 CUDA 应用程序时,每个应用程序都可能没有充分利用 GPU 的资源,您可以使用简单的超额订阅策略来利用 GPU 的时间切片调度器。从 Pascal 体系结构开始, compute preemption 支持这一点。这种技术有时被称为暂时 GPU 共享,在不同的 CUDA 应用程序之间切换上下文确实会带来成本,但一些未充分利用的应用程序仍然可以从该策略中受益。
由于 CUDA 11.1 ( R455 +驱动程序), CUDA 应用程序的时间片持续时间可通过nvidia-smi实用程序:
$ nvidia-smi compute-policy --help Compute Policy -- Control and list compute policies. Usage: nvidia-smi compute-policy [options] Options include: [-i | --id]: GPU device ID's. Provide comma separated values for more than one device [-l | --list]: List all compute policies [ | --set-timeslice]: Set timeslice config for a GPU: 0=DEFAULT, 1=SHORT, 2=MEDIUM, 3=LONG [-h | --help]: Display help information
当许多不同的应用程序在 GPU 上进行时间切片时,时间切片的折衷是增加延迟、抖动和潜在的内存不足( OOM )情况。这一机制是我们在本文第二部分重点关注的。
CUDA 多进程服务
您可以进一步使用前面描述的超额预订策略 CUDA MPS 。 当每个进程太小而无法使 GPU 的计算资源饱和时, MPS 允许来自不同进程(通常是 MPI 列)的 CUDA 内核在 GPU 上并发处理。与时间切片不同, MPS 允许来自不同进程的 CUDA 内核在 GPU 上并行执行。
CUDA 的较新版本(自 CUDA 11.4 +以来)增加了更多细粒度资源调配,能够指定 MPS 客户端可分配内存量(CUDA_MPS_PINNED_DEVICE_MEM_LIMIT)和可用计算量(CUDA_MPS_ACTIVE_THREAD_PERCENTAGE)的限制。有关这些调谐旋钮用法的更多信息,请参阅 Volta MPS 执行资源调配 。
与 MPS 的权衡是错误隔离、内存保护和服务质量( QoS )的限制。所有 MPS 客户端仍然共享 GPU 硬件资源。你今天可以通过 Kubernetes (库伯内特斯)访问 CUDA 议员,但 NVIDIA 计划在未来几个月改善对议员的支持。
多实例 GPU ( MIG )
迄今为止讨论的机制要么依赖于使用 CUDA 编程模型 API (如 CUDA 流)对应用程序的更改,要么依赖于 CUDA 系统软件(如时间切片或 MPS )。
使用 MIG ,基于 NVIDIA 安培体系结构的 GPU ,例如 NVIDIA A100 ,可以为 CUDA 应用程序安全划分多达七个独立的 GPU 实例,为多个应用程序提供专用的 GPU 资源。这些包括流式多处理器( SMs )和 GPU 引擎,如复制引擎或解码器,为不同的客户端(如进程、容器或虚拟机( VM ))提供定义的 QoS 和故障隔离。
当对 GPU 进行分区时,可以在单个 MIG 实例中使用之前的 CUDA 流、 CUDA MPS 和时间切片机制。
有关更多信息,请参阅 MIG 用户指南 和 MIG 支持 Kubernetes 。
使用 vGPU 实现虚拟化
NVIDIA vGPU 使具有完全输入输出内存管理单元( IOMMU )保护的虚拟机能够同时直接访问单个物理 GPU 。除了安全性之外, NVIDIA v GPU 还带来了其他好处,如通过实时虚拟机迁移进行虚拟机管理,能够运行混合的 VDI 和计算工作负载,以及与许多行业虚拟机监控程序的集成。
在支持 MIG 的 GPU 上,每个 GPU 分区都作为 VM 的单根 I / O 虚拟化( SR-IOV )虚拟功能公开。所有虚拟机都可以并行运行,而不是分时间运行(在不支持 MIG 的 GPU 上)。
表 1 总结了这些技术,包括何时考虑这些并发机制。

在这种背景下,本文的其余部分将重点介绍使用 Kubernetes 中新的时间切片 API 超额订阅 GPU 。
Kubernetes 中的时间切片支持
NVIDIA GPU 是 推广为 通过 设备插件框架 作为 Kubernetes 中的可调度资源。然而,此框架仅允许将设备(包括 GPU (作为nvidia.com/gpu)作为整数资源进行广告,因此不允许过度订阅。在本节中,我们将讨论一种使用时间切片在 Kubernetes 中超额订阅 GPU 的新方法。
在讨论新的 API 之前,我们将介绍一种新的机制,用于使用配置文件配置 NVIDIA Kubernetes 设备插件。
新配置文件支持
Kubernetes 设备插件提供了许多配置选项,这些选项可以设置为命令行选项或环境变量,例如设置 MIG 策略、设备枚举等。类似地, gpu-feature-discovery ( GFD )使用类似的选项来生成标签来描述 GPU 节点。
随着配置选项变得越来越复杂,您可以使用配置文件将这些选项表示为 Kubernetes 设备插件和 GFD ,然后将其部署为configmap对象,并在启动期间应用于插件和 GFD 吊舱。
配置选项在 YAML 文件中表示。在以下示例中,您将各种选项记录在名为dp-example-config.yaml的文件中,该文件是在/tmp下创建的。
$ cat << EOF > /tmp/dp-example-config.yaml version: v1 flags: migStrategy: "none" failOnInitError: true nvidiaDriverRoot: "/" plugin: passDeviceSpecs: false deviceListStrategy: "envvar" deviceIDStrategy: "uuid" gfd: oneshot: false noTimestamp: false outputFile: /etc/kubernetes/node-feature-discovery/features.d/gfd sleepInterval: 60s EOF
然后,通过指定配置文件的位置并使用gfd.enabled=true选项启动 GFD 来启动 Kubernetes 设备插件:
$ helm install nvdp nvdp/nvidia-device-plugin \ --version=0.12.2 \ --namespace nvidia-device-plugin \ --create-namespace \ --set gfd.enabled=true \ --set-file config.map.config=/tmp/dp-example-config.yaml
动态配置更改
默认情况下,该配置应用于所有节点上的所有 GPU 。 Kubernetes 设备插件允许指定多个配置文件。通过覆盖节点上的标签,可以逐个节点覆盖配置。
Kubernetes 设备插件使用一个 sidecar 容器来检测所需节点配置中的更改,并重新加载设备插件,以便新配置能够生效。在以下示例中,您为设备插件创建了两种配置:一种默认配置应用于所有节点,另一种配置可根据需要应用于 100 个 GPU 节点。
$ helm install nvdp nvdp/nvidia-device-plugin \ --version=0.12.2 \ --namespace nvidia-device-plugin \ --create-namespace \ --set gfd.enabled=true \ --set-file config.map.default=/tmp/dp-example-config-default.yaml \ --set-file config.map.a100-80gb-config=/tmp/dp-example-config-a100.yaml
然后,只要覆盖节点标签, Kubernetes 设备插件就可以对配置进行动态更改,如果需要,可以在每个节点的基础上进行配置:
$ kubectl label node \ --overwrite \ --selector=nvidia.com/gpu.product=A100-SXM4-80GB \ nvidia.com/device-plugin.config=a100-80gb-config
时间切片 API
为了支持 GPU 的时间切片,可以使用以下字段扩展配置文件的定义:
version: v1 sharing: timeSlicing: renameByDefault:failRequestsGreaterThanOne: resources: - name: replicas: ...
也就是说,对于sharing.timeSlicing.resources下的每个命名资源,现在可以为该资源类型指定多个副本。
此外,如果renameByDefault=true,则每个资源都会在名称下播发《reZEDZ_insteadofismpl_E H1-31。
对于向后兼容性,failRequestsGreaterThanOne标志默认为 false 。它控制 POD 是否可以请求多个 GPU 资源。一个以上的 GPU 请求并不意味着 pod 会按比例获得更多的时间片,因为 GPU 调度器当前为 GPU 上运行的所有进程提供相等的时间份额。
failRequestsGreaterThanOne标志配置插件的行为,将一个 GPU 的请求视为访问请求,而不是独占资源请求。
创建新的超额订阅资源时, Kubernetes 设备插件会将这些资源分配给请求的作业。当两个或多个作业落在同一 GPU 上时,这些作业会自动使用 GPU 的时间切片机制。该插件不提供任何其他额外的隔离好处。
GFD 应用的标签
对于 GFD ,应用的标签取决于renameByDefault=true。无论renameByDefault的设置如何,始终应用以下标签:
nvidia.com/.replicas =
但是,当renameByDefault=false时,nvidia.com/《resource-name》.product标签也会添加以下后缀:
nvidia.com/gpu.product =-SHARED
使用这些标签,您可以选择共享或非共享 GPU ,就像您传统上选择一个 GPU 模型而不是另一个模型一样。也就是说,SHARED注释确保可以使用nodeSelector对象将吊舱吸引到在其上共享 GPU 的节点。此外, POD 可以确保它们降落在使用新副本标签将 GPU 划分为所需比例的节点上。
超额认购示例
下面是一个使用时间切片 API 过度订阅 GPU 资源的完整示例。在本例中,您将遍历 Kubernetes 设备插件和 GFD 的其他配置设置,以设置 GPU 超额订阅并使用指定的资源启动工作负载。
考虑以下配置文件:
version: v1 sharing: timeSlicing: resources: - name: nvidia.com/gpu replicas: 5 ...
如果将此配置应用于具有八个 GPU 的节点,则插件现在将向 Kubernetes 播发 40 个nvidia.com/gpu资源,而不是八个。如果设置了renameByDefault: true选项,则将播发 40 个nvidia.com/gpu.shared 资源,而不是 8 个nvidia.com/gpu资源。
您可以在以下示例配置中启用时间切片。在本例中,超额认购 GPU 2 倍:
$ cat << EOF > /tmp/dp-example-config.yaml version: v1 flags: migStrategy: "none" failOnInitError: true nvidiaDriverRoot: "/" plugin: passDeviceSpecs: false deviceListStrategy: "envvar" deviceIDStrategy: "uuid" gfd: oneshot: false noTimestamp: false outputFile: /etc/kubernetes/node-feature-discovery/features.d/gfd sleepInterval: 60s sharing: timeSlicing: resources: - name: nvidia.com/gpu replicas: 2 EOF
设置舵图存储库:
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin \ && helm repo update
现在,通过指定前面创建的配置文件的位置来部署 Kubernetes 设备插件:
$ helm install nvdp nvdp/nvidia-device-plugin \ --version=0.12.2 \ --namespace nvidia-device-plugin \ --create-namespace \ --set gfd.enabled=true \ --set-file config.map.config=/tmp/dp-example-config.yaml
由于节点只有一个物理 GPU ,您现在可以看到设备插件发布了两个可分配的 GPU :
$ kubectl describe node ... Capacity: cpu: 4 ephemeral-storage: 32461564Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 16084408Ki nvidia.com/gpu: 2 pods: 110 Allocatable: cpu: 4 ephemeral-storage: 29916577333 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15982008Ki nvidia.com/gpu: 2 pods: 110
接下来,部署两个应用程序(在本例中为 FP16 CUDA GEMM 工作负载),每个应用程序都请求一个 GPU 。观察到应用程序上下文在 GPU 上切换,因此在 T4 上仅实现大约一半的 FP16 峰值带宽。
$ cat << EOF | kubectl create -f - apiVersion: v1 kind: Pod metadata: name: dcgmproftester-1 spec: restartPolicy: "Never" containers: - name: dcgmproftester11 image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 args: ["--no-dcgm-validation", "-t 1004", "-d 30"] resources: limits: nvidia.com/gpu: 1 securityContext: capabilities: add: ["SYS_ADMIN"] --- apiVersion: v1 kind: Pod metadata: name: dcgmproftester-2 spec: restartPolicy: "Never" containers: - name: dcgmproftester11 image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 args: ["--no-dcgm-validation", "-t 1004", "-d 30"] resources: limits: nvidia.com/gpu: 1 securityContext: capabilities: add: ["SYS_ADMIN"] EOF
现在,您可以看到在单个物理 GPU 上部署和运行的两个容器,如果没有新的时间切片 API ,这在 Kubernetes 是不可能的:
$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default dcgmproftester-1 1/1 Running 0 45s default dcgmproftester-2 1/1 Running 0 45s kube-system calico-kube-controllers-6fcb5c5bcf-cl5h5 1/1 Running 3 32d
您可以在主机上使用nvidia-smi,通过 GPU 上的插件和上下文开关,查看两个容器在相同的物理 GPU 上的调度:
$ nvidia-smi -L GPU 0: Tesla T4 (UUID: GPU-491287c9-bc95-b926-a488-9503064e72a1) $ nvidia-smi ...... +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 466420 C /usr/bin/dcgmproftester11 315MiB | | 0 N/A N/A 466421 C /usr/bin/dcgmproftester11 315MiB | +-----------------------------------------------------------------------------+
总结
开始利用 新的 GPU 超额订阅支持 今天在库伯内特斯。 Kubernetes 设备插件新版本的 Helm 图表使您可以轻松地立即开始使用该功能。
短期路线图包括与 NVIDIA GPU 运算符 这样,您就可以访问该功能,无论是使用 Red Hat 的 OpenShift 、 VMware Tanzu ,还是使用 NVIDIA LaunchPad 上的 NVIDIA 云本机核心 等调配环境。 NVIDIA 还致力于改进 Kubernetes 设备插件中对 CUDA MPS 的支持,以便您可以利用 Kubernetes 中的其他 GPU 并发机制。
关于作者
Kevin Klues 是 NVIDIA 原始云团队的首席软件工程师。自加入 NVIDIA 以来, Kevin 一直参与多项技术的设计和实施,包括 Kubernetes 拓扑管理器、 NVIDIA 的 Kubernetes 设备插件和 MIG 的容器/ Kubernetes 堆栈。
Kyrylo Perelygin 自 2013 年加入 NVIDIA 后,一直致力于 CUDA 的多进程服务和新的合作团队等功能。 Kyrylo 毕业于 EPITECH ,获得学士学位,并获得 CSULB 硕士学位。
Pramod Ramarao 是 NVIDIA 加速计算的产品经理。他领导 CUDA 平台和数据中心软件的产品管理,包括容器技术。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5682浏览量
110102 -
gpu
+关注
关注
28文章
5266浏览量
136040 -
CUDA
+关注
关注
0文章
128浏览量
14545
发布评论请先 登录
基于Arm架构服务器释放更高CPU利用率
K8s部署vLLM推理服务详细步骤
大模型推理服务的弹性部署与GPU调度方案
KubePi:开源Kubernetes可视化管理面板,让集群管理如此简单
GPU 利用率<30%?这款开源智算云平台让算力不浪费 1%
华为发布AI容器技术Flex:ai,算力平均利用率提升30%
从CPU、GPU到NPU,美格智能持续优化异构算力计算效能

设备利用率算不清?智能管理系统自动分析数据,生成可视化报表帮你降本

从 “被动维修” 到 “主动管理”:这套系统让设备利用率提升 30%

海光DCU率先展开文心系列模型的深度技术合作 FLOPs利用率(MFU)达47%
mes工厂管理系统:如何让设备利用率提升50%?
提升AI训练性能:GPU资源优化的12个实战技巧

Kubernetes Helm入门指南
DeepSeek MoE架构下的网络负载如何优化?解锁90%网络利用率的关键策略




评论