 混合使用CPU和GPU元素的多核图像处理
混合使用CPU和GPU元素的多核图像处理

尽管多媒体处理极大地受益于多核处理器可用性的提高,但直到最近,人们仍倾向于从基本同质的 CPU 架构的角度考虑多核。一种典型的方法提供双核、四核和更多数量的内核,这些内核排列在对称多处理器 (SMP) 或缓存一致的非统一内存架构 (ccNUMA) 组中。这些设备有时带有额外的硬件加速来卸载特别困难的任务,例如 H.264 视频处理中使用的上下文自适应可变长度编码 (CAVLC) 或处理器密集型上下文自适应二进制算术编码 (CABAC) 熵编码功能。
许多公司现在在他们的设备中提供集成显卡,主要是为了节省电路板空间和材料成本。拥有集成图形处理单元 (GPU) 的另一个好处是它可以提供另一种途径来攻击具有挑战性的计算任务。例如,AMD 的 R 系列处理器将 Bulldozer CPU 架构与离散级 AMD Radeon GPU 集成以产生加速处理单元 (APU)。
GPU 是一组单指令多数据 (SIMD) 处理元素。请注意阵列和 x86 内核之间的通用内存控制器。这种架构是转向 AMD 异构系统架构 (HSA) 的早期步骤,它通过将集成图形处理元素视为可应用于非图形数据的计算资源池,显着打破了传统的多核方法。它类似于可以使用附加硬件加速器的方式,但具有作为大型可编程设备集群的优势 - 高端多达 384 个内核 - 具有数百 GFLOPS 的计算吞吐量。
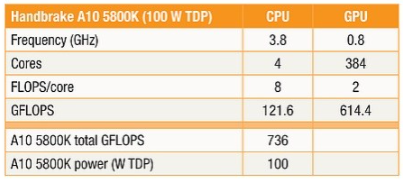
表 1 说明了与 AMD R 系列 APU 具有相同底层架构的 AMD 台式机部件的基本操作参数。基于 Bulldozer 的 CPU 的 121.6 GFLOPS 浮点性能与 GPU 相形见绌,GPU 为可以有效利用资源的应用程序提供 614 GFLOPS。在成像中利用添加的 GPU 处理器的关键是考虑将数据块传输到 GPU、对其进行处理、然后将结果返回到主线程所需的时间。
表 1:运行参数的比较展示了 AMD 台式机部件中 CPU 与 GPU 的性能。
视频转码应用中的性能分析
尽管当前一代 AMD R 系列处理器需要在 GPU 和 CPU 之间进行缓冲区传输,但数据并行应用程序可以实现吞吐量和功率效率的提高,这大大超过了数据传输的成本。
数据并行应用程序的一个示例是 Handbrake,它是一种广泛使用的视频转码实用程序,可在各种操作系统和硬件平台上运行。该实用程序值得注意的是,它具有良好集成的多核支持,因此可作为研究多核策略有效性的合适平台。Handbrake 使用 x264,这是一种功能齐全的 H.264 编码器,用于多种开源和商业产品,可提供足够的多核支持。
在这两个项目中都使用了 OpenCL,以最大限度地利用 APU 中可用的 GPU 计算资源。在 x264 中,与前瞻功能相关的质量优化被完全移植到 GPU 上的 OpenCL。这可用于转码应用程序以提高输出视频质量,通常会消耗高达约 20% 的 CPU 时间。Handbrake 直接使用 x264 作为视频编码器。此外,Handbrake 使用 OpenCL 执行视频缩放和从 RGB 到 YUV 色彩空间的色彩空间转换。AMD 的硬件视频解码器 (UVD) 也被用于 Handbrake 以执行一些视频解码任务。
数据是在 Trinity 100 W A10 台式机上生成的;但是,底层架构与嵌入式产品中使用的架构相同。
为了简化对 APU 复杂电源管理架构的分析,我们评估了顶级热设计功耗 (TDP),而不是分解每个子系统消耗的功耗。表 2 中显示的数据表明,当纯粹在 CPU 中执行处理时,可以实现 14.8 fps 的帧速率,并且在 62 秒内完成处理。在处理过程中涉及 GPU 和 UVD 块将帧速率提高到 18.3 fps,从而减少了处理时间,从而减少了 14 秒或 22% 的功耗。
表 2:对 A10 台式机上的 Handbrake 应用程序的分析显示了单独使用 CPU 与使用 GPU 和 UVD 块进行处理时的性能差异。

表 2 中的浮点运算总数是表 1 中的浮点吞吐量和处理时间的乘积,从中可以得出一个品质因数:每瓦操作数。查看每瓦特的总浮点运算和归一化运算,很明显处理资源被留在了桌面上。仅 CPU 的吞吐量为每瓦 75 次操作,而当添加 GPU 时,它提高到每瓦 353 次操作,理论浮点吞吐量提高了近 5 倍 (4.7)。
22% 是非常重要的节省,但是尽管这一代 APU 在 HSA 方向上取得了重大进展,但从延迟和吞吐量的角度来看,所有内存访问并不统一。当内核访问内存时,它会直接这样做。在典型应用中,此类操作的理论速率为 22 GBps 或 16 到 18 GBps。但是,当在主机内存中创建缓冲区以访问 GPU 数据时,该数据会通过不同的路径,其中有效带宽接近 8 MBps。这意味着内核在本地可以预期的内存带宽与程序员为 GPU 内存设置本地缓冲区时可以预期的内存带宽差距接近 3:1。这是对称的。如果 GPU 需要驻留在 CPU 内存中的数据,那么同样的关系也成立。
未来采用全 HSA 架构的设备将拥有统一的内存模型,无需在 CPU 和 GPU 内存区域之间复制数据。诸如 x264 的前瞻功能等算法,当移入 GPU 的处理域时,从内存带宽的角度来看,将具有近乎同等的地位。
基准测试应用程序中的性能分析
数据并行应用程序的第二个示例是 LuxMark,它是一个面向图形的基准测试包,它使用 OpenCL,并说明了当从等式中移除内存访问时间的差异时可以实现的目标。默认的集成基准测试在 AMD Embedded R-464L APU 上运行,其特性如表 3 所示。
表 3:运行参数比较展示了 AMD 嵌入式 R-464L APU 中的 CPU 与 GPU 性能。
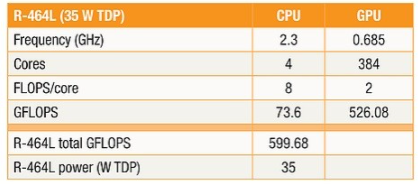
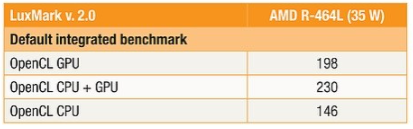
表 4 中的结果清楚地表明,对于此类处理任务,GPU 的性能优于 CPU 25% 以上。使用完整的 HSA 实施,人们会期望看到 CPU 加 GPU 的增加接近 GPU 加 CPU 的总和:344。在实践中,得到的数字是 230,这是一个不平凡的 63% 提升,但不是反映充分利用的资源。这种差距主要是由于 CPU 解析数据的开销以及以前面描述的较低速度在 CPU 和 GPU 之间来回传输数据的开销。这些特性将能够以最小的开销同时利用 CPU 和 GPU,从而使 CPU 和 GPU 的综合性能明显优于单独使用任何一个。
表 4:在 AMD 嵌入式 R-464L APU 上运行 LuxMark 2.0 基准测试的结果表明 GPU 在此处理任务中的表现优于 CPU。
最大化计算资源
新发布的 APU 产品为嵌入式计算产品的设计人员提供了重要的计算资源。利用这些资源需要对底层硬件架构有深入的了解,深入了解目标应用程序中的数据流问题,并熟悉 OpenCL 等最新工具。
作者:Frank Altschuler ,Jonathan Gallmeier
审核编辑:郭婷
-
amd
+关注
关注
25文章
5707浏览量
140399 -
嵌入式
+关注
关注
5209文章
20645浏览量
336925 -
gpu
+关注
关注
28文章
5271浏览量
136060
发布评论请先 登录
什么是GPU?GPU的主要作用和工作原理以及GPU和CPU的区别
恒讯科技分析:GPU是什么和CPU的区别?
gpu和cpu有什么区别?
cpu gpu npu的区别 NPU与GPU哪个好?gpu是什么意思?
CPU和GPU之间的主要区别




评论