 YOLOX目标检测模型的推理部署
YOLOX目标检测模型的推理部署

YOLOX目标检测模型
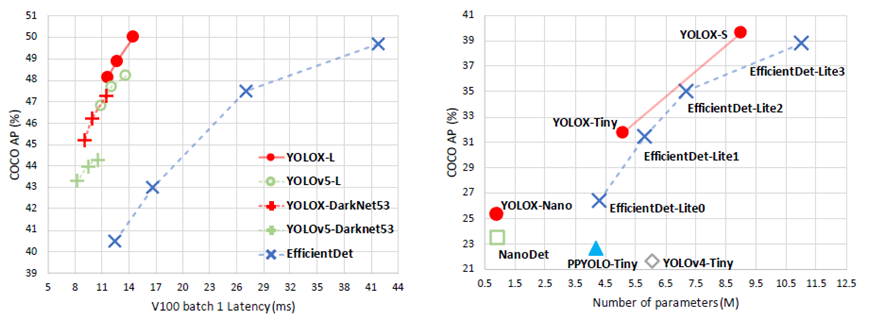
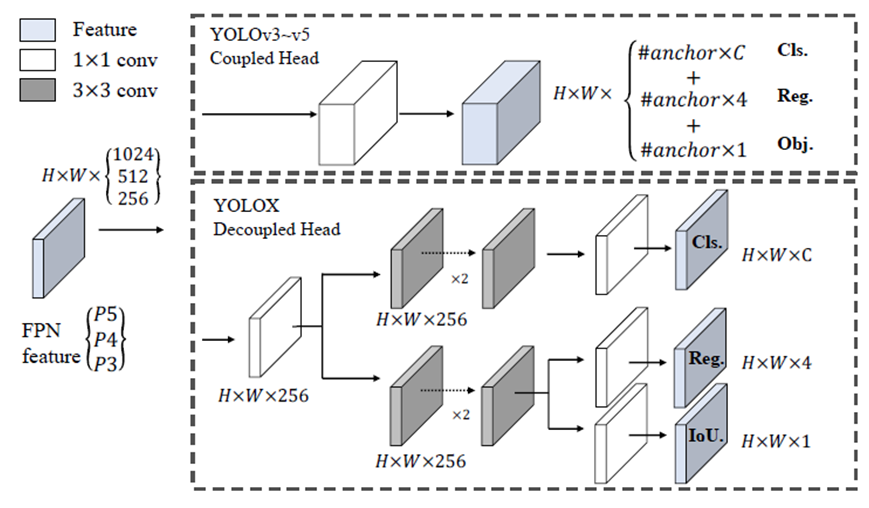
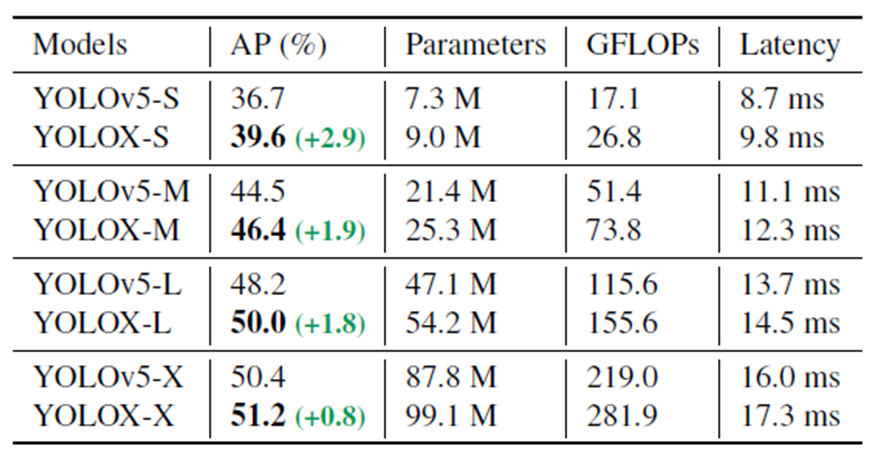
旷视科技开源了内部目标检测模型-YOLOX,性能与速度全面超越YOLOv5早期版本!
https://arxiv.org/pdf/2107.08430.pdfhttps://github.com/Megvii-BaseDetection/YOLOX
ONNX格式模型转与部署
下载YOLOX的ONNX格式模型(github上可以下载)https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo/ONNXRuntimehttps://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.onnx
下载ONNX格式模型,打开之后如图:
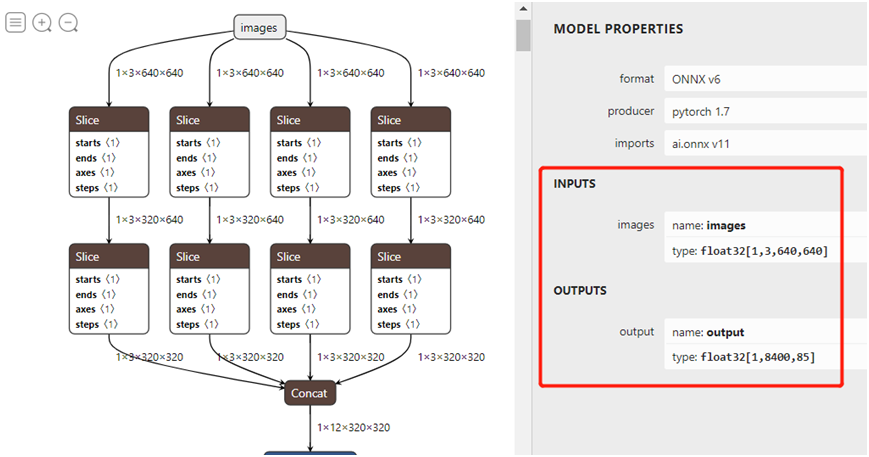
官方说明ONNX格式支持OpenVINO、ONNXRUNTIME、TensorRT三种方式,而且都提供源码,官方提供的源码参考如下:输入格式:1x3x640x640,默认BGR,无需归一化。输出格式:1x8400x85
https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo
本人就是参考上述的代码然后一通猛改,分别封装成三个类,完成了统一接口,公用了后处理部分的代码,基于本人笔记本的硬件资源与软件版本:
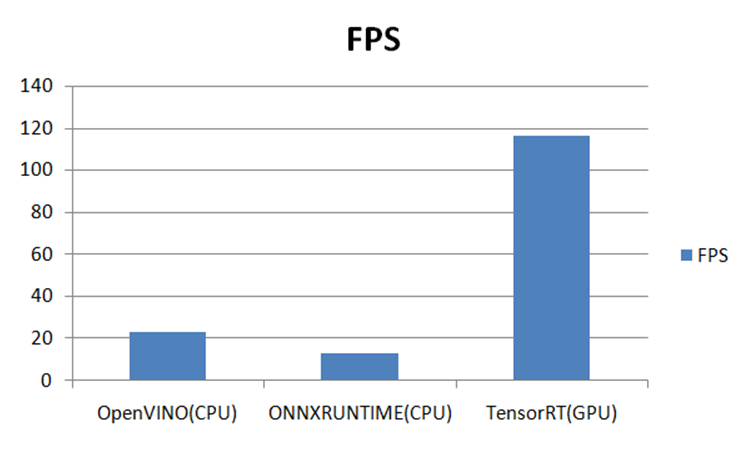
在三个推理平台上测试结果如下:-GPU 3050Ti-CPU i7 11代-OS:Win10 64位-OpenVINO2021.4-ONNXRUNTIME:1.7-CPU-OpenCV4.5.4-Python3.6.5-YOLOX-TensorRT8.4.x

OpenVINO推理

TensorRT推理 - FP32
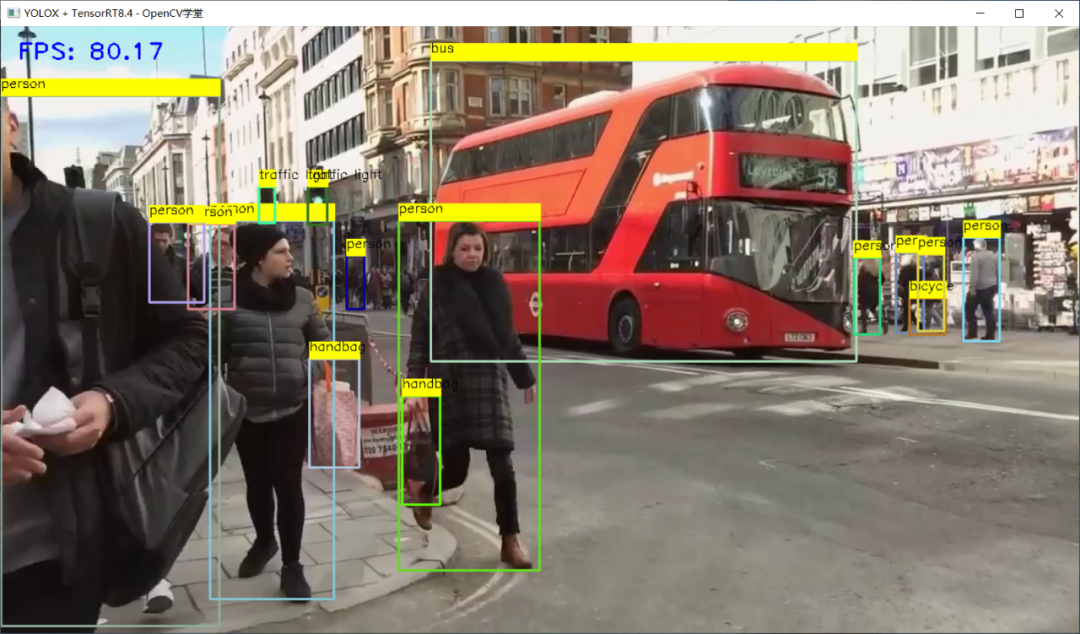
转威FP16
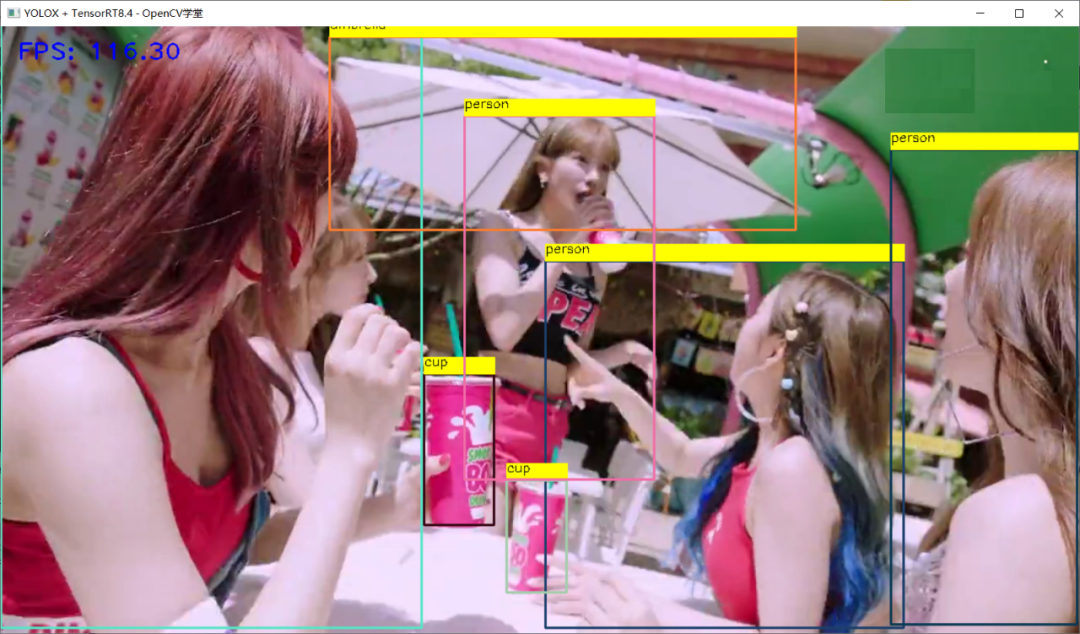
TensorRT推理 - FP16
总结
之前我写过一篇文章比较了YOLOv5最新版本在OpenVINO、ONNXRUNTIME、OpenCV DNN上的速度比较,现在加上本篇比较了YOLOX在TensorRT、OpenVINO、ONNXRUNTIME上推理部署速度比较,得到的结论就是:能不改代码,同时支持CPU跟GPU推理是ONNXRUNTIMEOpenCV DNN毫无意外的速度最慢(CPU/GPU)CPU上速度最快的是OpenVINOGPU上速度最快的是TensorRT
原文标题:YOLOX在OpenVINO、ONNXRUNTIME、TensorRT上面推理部署与速度比较
文章出处:【微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
模型
+关注
关注
1文章
3834浏览量
52289 -
目标检测
+关注
关注
0文章
234浏览量
16550 -
OpenCV
+关注
关注
33文章
652浏览量
45111
原文标题:YOLOX在OpenVINO、ONNXRUNTIME、TensorRT上面推理部署与速度比较
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
【幸狐Omni3576边缘计算套件试用体验】YOLO26 板端部署
训练模型获取等;
YOLO26:目标检测、实例分割、图像分类、姿态估计、旋转框检测等;
准备工作
包括硬件连接、OpenCV 安装、Ultralytics 库
发表于 04-19 22:02
【瑞萨AI挑战赛】手写数字识别模型在RA8P1 Titan Board上的部署
提供了高性能、高易用性的硬件平台,而E2Studio与ruhmi框架的组合,大幅降低了模型端侧部署的门槛,相信在工业检测、智能穿戴、智能家居等领域,该开发板与端侧AI部署方案将拥有广泛
发表于 03-15 20:42
大模型推理服务的弹性部署与GPU调度方案
7B 模型 FP16 推理需要约 14GB 显存,70B 模型需要 140GB+,KV Cache 随并发数线性增长,显存碎片化导致实际利用率不足 60%。
LLM推理模型是如何推理的?
这篇文章《(How)DoReasoningModelsReason?》对当前大型推理模型(LRM)进行了深刻的剖析,超越了表面的性能宣传,直指其技术本质和核心局限。以下是基于原文的详细技术原理、关键

AI端侧部署开发(SC171开发套件V3)2026版
AI端侧部署开发(SC171开发套件V3)2026版
序列
课程名称
视频课程时长
视频课程链接
课件链接
工程源码
1
Fibo AI Stack模型转化指南
27分19秒
https
发表于 01-15 10:31
NVIDIA TensorRT LLM 1.0推理框架正式上线
TensorRT LLM 作为 NVIDIA 为大规模 LLM 推理打造的推理框架,核心目标是突破 NVIDIA 平台上的推理性能瓶颈。为实现这一目
广和通发布端侧目标检测模型FiboDet
为提升端侧设备视觉感知与决策能力,广和通全自研端侧目标检测模型FiboDet应运而生。该模型基于广和通在边缘计算与人工智能领域的深度积累,面向工业、交通、零售等多个行业提供高性能、低功
什么是AI模型的推理能力
NVIDIA 的数据工厂团队为 NVIDIA Cosmos Reason 等 AI 模型奠定了基础,该模型近日在 Hugging Face 的物理推理模型排行榜中位列榜首。
使用aicube进行目标检测识别数字项目的时候,在评估环节卡住了,怎么解决?
使用aicube进行目标检测识别数字项目的时候,前面一切正常
但是在评估环节卡住了,一直显示正在测试,但是完全没有测试结果,
在部署完模型后在k230上运行也没有任何识别结果
期
发表于 08-13 06:45
基于米尔瑞芯微RK3576开发板部署运行TinyMaix:超轻量级推理框架
本文将介绍基于米尔电子MYD-LR3576开发平台部署超轻量级推理框架方案:TinyMaix
摘自优秀创作者-短笛君
TinyMaix 是面向单片机的超轻量级的神经网络推理库,即 TinyML
发表于 07-25 16:35
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
TensorRT-LLM 作为 NVIDIA 专为 LLM 推理部署加速优化的开源库,可帮助开发者快速利用最新 LLM 完成应用原型验证与产品部署。
大模型推理显存和计算量估计方法研究
随着人工智能技术的飞速发展,深度学习大模型在各个领域得到了广泛应用。然而,大模型的推理过程对显存和计算资源的需求较高,给实际应用带来了挑战。为了解决这一问题,本文将探讨大模型
发表于 07-03 19:43
基于LockAI视觉识别模块:C++目标检测
快速部署高性能的目标检测应用。
特点:
高性能:优化了推理速度,在保持高精度的同时实现了快速响应。
灵活性:支持多种预训练模型,可以根据具体
发表于 06-06 14:43
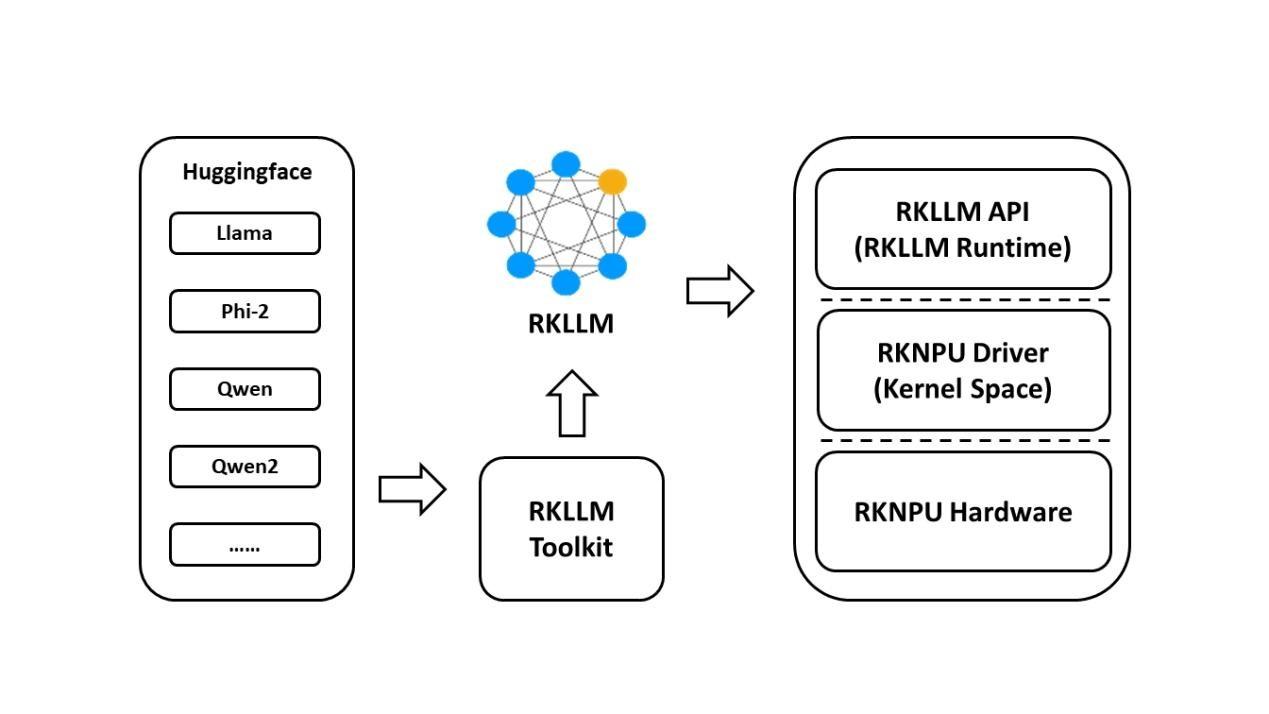
基于RK3576开发板的RKLLM大模型部署教程
Runtime则负责加载转换后的模型,并在Rockchip NPU上进行推理,用户可以通过自定义回调函数实时获取推理结果。
开发流程分为模型转换和板端



评论