 在ZTR无配置大规模中实现的缩放零接触RoCE技术
在ZTR无配置大规模中实现的缩放零接触RoCE技术

NVIDIA Zero Touch RoCE ( ZTR )使数据中心能够无缝部署 聚合以太网上的 RDMA ( RoCE ) ,而无需任何特殊交换机配置。直到最近, ZTR 还仅适用于中小型数据中心。同时,大规模部署传统上依赖于显式拥塞通知( ECN )来启用 RoCE 网络传输,这需要交换机配置。
新的 NVIDIA 拥塞控制算法往返时间拥塞控制( RTTCC ) – 允许 ZTR 在不影响性能的情况下扩展到数千台服务器。通过使用 ZTR 和 RTTCC ,数据中心运营商可以在无需任何交换机配置的情况下,享受部署和操作的便利性,以及大规模远程直接内存访问( RDMA )的卓越性能。
这篇文章描述了以前在大规模和小型 RoCE 部署中推荐的 RoCE 拥塞控制。然后介绍了一种新的拥塞控制算法,该算法允许 ZTR 的无配置大规模实现,其性能类似于支持 ECN 的 RoCE 。
具有数据中心量化拥塞通知的 RoCE 部署
在典型的基于 TCP 的环境中,分布式内存请求需要许多步骤和 CPU 周期,这会对应用程序性能产生负面影响。 RDMA 消除了服务器之间内存数据传输的所有 CPU 参与,大大加快了对存储数据的访问和应用程序性能。
RoCE 在以太网环境中提供 RDMA ,这是数据中心的主要网络结构。以太网需要高级拥塞控制机制来支持 RDMA 网络传输。数据中心量化拥塞通知( DCQCN )是一种拥塞控制算法,能够响应拥塞通知并动态调整流量传输速率。
DCQCN 的实现需要启用显式拥塞通知( ECN ),这需要配置网络交换机。 ECN 将交换机配置为设置拥塞经历( CE )位,以指示即将发生的拥塞。
具有无功拥塞控制的零接触 RoCE
NVIDIA 开发的 ZTR 技术允许 RoCE 部署,无需配置交换机基础设施。 ZTR 根据 InfiniBand Trade Association ( IBTA ) RDMA 标准构建,完全符合 RoCE specifications ,支持 RoCE 的无缝部署。 ZTR 还拥有与传统交换机启用的 RoCE 相当的性能,并且明显优于传统的基于 TCP 的内存访问。此外,通过 ZTR , RoCE 网络传输服务在普通 TCP / IP 环境中与非 RoCE 通信并行运行。
正如 NVIDIA 零接触 RoCE 技术为 Microsoft Azure Stack HCI 实现了云经济 文章中所指出的,微软已经为其 Azure Stack HCI 平台验证了 ZTR ,该平台通常可扩展到几十个节点。在这样的环境中, ZTR 依赖于隐式丢包通知,这对于小规模部署来说已经足够了。通过添加新的基于往返计时器( RTT )的拥塞控制算法, ZTR 变得更加健壮和可扩展,而无需依赖丢包来通知服务器网络拥塞。
引入往返时间拥塞控制
新的 NVIDIA 拥塞控制算法 RTTCC 主动监控网络 RTT ,以便在丢弃数据包之前主动检测并适应拥塞的发生。 RTTCC 使用基于硬件的反馈环路实现动态拥塞控制,与基于软件的拥塞控制算法相比,该反馈环路提供了显著优越的性能。 RTTCC 还支持更快的传输速率,可以在更大范围内部署 ZTR 。带有 RTTCC 的 ZTR 现在作为测试版功能提供, GA 计划在 2022 年下半年推出。
ZTR-RTTCC 的工作原理
ZTR-RTTCC 通过基于硬件 RTT 的拥塞控制算法扩展了 RoCE 网络中的 DCQCN 。
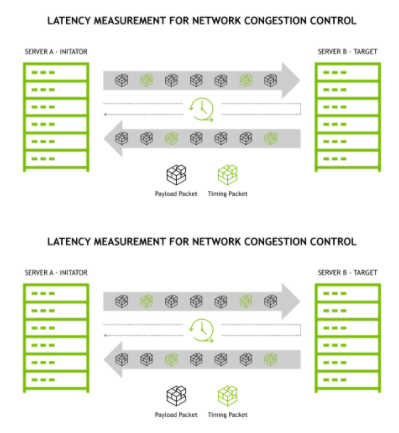
图 1 服务器之间的往返计时
定时数据包(上图中的绿色网络数据包)定期从启动器发送到目标。立即返回定时数据包,从而能够测量往返延迟。 RTTCC 测量数据包发送和启动器接收数据包之间的时间间隔。差异(接收时间–发送时间)衡量往返延迟,这表明路径拥塞。未压缩流继续传输数据包,以最佳利用可用网络路径带宽。延迟增加的流意味着路径拥塞, RTTCC 会对流量进行节流,以避免缓冲区溢出和数据包丢失。
随着拥塞的减少或增加,网络流量可以实时地向上或向下调整。主动监控和应对拥塞的能力对于使 ZTR 能够主动管理拥塞至关重要。这种主动速率控制还可以减少数据包的重新传输,提高 RoCE 性能。使用 ZTR-RTTCC ,数据中心节点不会等待数据包丢失的通知;相反,它们主动识别拥塞 prior to 数据包丢失并作出相应反应,通知启动器调整传输速率。
如前所述, ZTR 的一个关键优势是能够提供 RoCE 功能,同时在普通 TCP / IP 流量中与非 RoCE 通信同时运行。 ZTR 提供 RoCE 网络功能的无缝部署。通过添加 RTTCC 主动监控拥塞, ZTR 提供数据中心范围内的操作,无需交换机配置。请继续阅读,看看它的性能如何。
具有 RTTCC 性能的 ZTR
如图 2 所示,当通过网络结构配置 ECN 和 PFC 时,带有 RTTCC 的 ZTR 提供了与 RoCE 相当的应用程序性能。这些测试是在最坏的多对一( in-cast )情况下进行的,以模拟拥挤条件下的吞吐量。
结果表明,具有 RTTCC 的 ZTR 不仅可以扩展到数千个节点,而且其性能与目前可用的最快 RoCE 解决方案相当。
在小规模( 256 个连接及以下)下,具有 RTTCC 的 ZTR 在启用 ECN 拥塞控制(传统 RoCE )的 RoCE 的 99% 范围内执行。
通过 16000 多个连接,具有 RTTCC 吞吐量的 ZTR 是传统 RoCE 吞吐量的 98% 。
带有 RTTCC 的 ZTR 在不需要任何开关配置的情况下,提供了与传统 RoCE 几乎相同的性能。
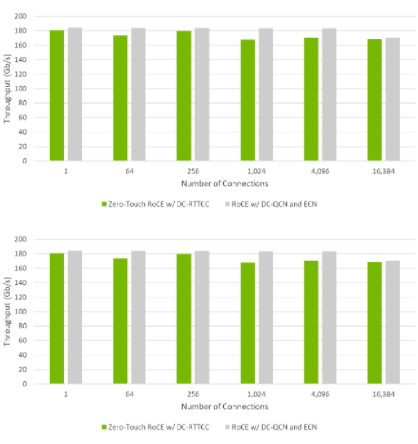
图 2 连接不断增加的应用程序带宽
配置 ZTR
要使用新的 RTTCC 算法配置 ZTR , 下载 并为 NVIDIA 网络接口卡安装最新固件和工具,请执行以下步骤。
配置 ZTR
要使用新的 RTTCC 算法配置 ZTR , 下载 并为 NVIDIA 网络接口卡安装最新固件和工具,请执行以下步骤。
使用mlxconfig(持续配置)启用可编程拥塞控制:
mlxconfig -d /dev/mst/mt4125_pciconf0 -y s ROCE_CC_LEGACY_DCQCN=0
使用mlxfwreset重置设备或重新启动主机:
mlxfwreset -d /dev/mst/mt4125_pciconf0 -l 3 -y r
完成这些步骤后,当 RDMA-CM 用于增强连接建立( ECE , MLNX _ OFED 版本 5.1 支持)时,将使用 ZTR-RTTCC 。
如果出现错误,无论 RDMA-CM 同步状态如何,都可以强制使用 ZTR-RTTCC :
mlxreg -d /dev/mst/mt4125_pciconf0 --reg_id 0x506e --reg_len 0x40 --set "0x0.0:8=2,0x4.0:4=15" -y
总结
NVIDIA RTTCC 是 ZTR 的新拥塞控制算法,在数据中心范围内提供卓越的 RoCE 性能,无需对交换机基础设施进行任何特殊配置。此增强功能使数据中心能够在现有和新的数据中心基础架构中无缝实现 RoCE ,并从即时的应用程序性能改进中获益。
关于作者
Aviv Barnea 是 NVIDIA 网络软件工程的高级主管。他监督网络适配器 RDMA 软件和拥塞控制机制的开发,实现高速、低延迟的数据中心连接。 Aviv 是 RDMA 和 RoCE 通信协议方面的专家,拥有该领域的多项专利,在推动 RDMA / RoCE 在业界的发展方面发挥了重要作用,在客户和合作伙伴大规模部署加速网络解决方案时与他们密切合作,并实现了无与伦比的性能和易用性。 Aviv 拥有特拉维夫大学工商管理硕士学位和理工学院物理与电气工程学士学位。
Itay Ozery 是 NVIDIA 网络产品营销总监。他为 Mellanox 的云网络解决方案推动战略性产品营销和产品管理计划。 Itay 在网络安全领域领导了大规模的业务和项目,并与数据中心和电信服务提供商在 IT 系统和网络工程领域担任过多个职位。
审核编辑:郭婷
-
接口
+关注
关注
33文章
9601浏览量
157628 -
NVIDIA
+关注
关注
14文章
5694浏览量
110119
发布评论请先 登录
HPM知识库 | BLDC 无传感器过零控制技术指南

RDMA设计37:RoCE v2 子系统模型设计
RDMA设计28:RoCE v2 发送及接收模块设计
RDMA设计19:RoCE v2 发送及接收模块设计
如何实现高效的RoCE网卡状态采集与监控?
如何实现 RoCE 配置的自动同步(基础篇) - DCBX协议

天合储能联合发布大规模储能技术应用及产业发展白皮书
TensorRT-LLM的大规模专家并行架构设计

Wolfspeed碳化硅技术实现大规模商用
大规模专家并行模型在TensorRT-LLM的设计

使用Ansible实现大规模集群自动化部署
复杂装备研发设计中利用数据实现大规模个性化定制
从哈希极化到零拥塞:主动路径规划在RoCE网络中的负载均衡实践

RDMA简介1之RDMA开发必要性
算力革命:RoCE实测推理时延比InfiniBand低30%的底层逻辑



评论