 高效框架互操作性第1部分:内存布局和内存池
高效框架互操作性第1部分:内存布局和内存池

介绍
高效的管道设计对数据科学家至关重要。在编写复杂的端到端工作流时,您可以从各种构建块中进行选择,每种构建块都专门用于特定任务。不幸的是,在数据格式之间重复转换容易出错,而且会降低性能。让我们改变这一点!
在本系列文章中,我们将讨论高效框架互操作性的不同方面:
我们从这篇文章开始讨论不同内存布局的优缺点,以及异步内存分配的内存池,以实现零拷贝功能。
在第二篇文章中,我们重点介绍了数据加载/传输过程中出现的瓶颈,以及如何使用远程直接内存访问( RDMA )技术缓解这些瓶颈。
在第三篇文章中,我们深入讨论了端到端管道的实现,展示了所讨论的跨数据科学框架的最佳数据传输技术。
零拷贝功能是跨 GPU – 加速数据科学框架 TensorFlow 、 PyTorch 、 MXNet 、 cuDF 、 CuPy 、 Numba 和 JAX 高效拷贝数据的关键技术(见图 2 )。在下文中,我们将向您展示如何以系统的方式实现这一目标。如果您只是在这里查找有关如何将数据从一个框架传输到另一个框架的命令,那么 MIG ht 需要了解一下 换算表 。
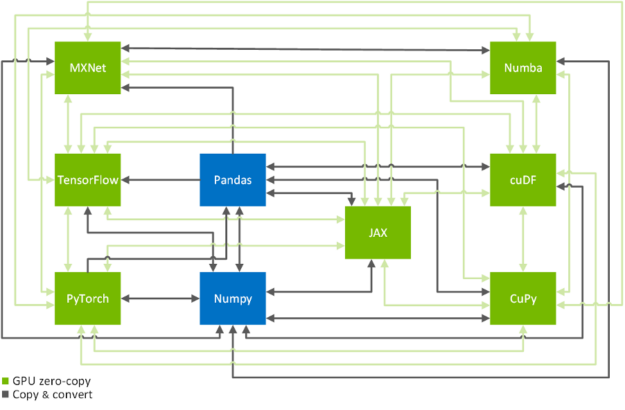
图 2 数据科学和机器学习框架之间的转换路径。
内存布局、数据格式和内存池
内存布局
在开始讨论如何高效地复制数据之前,让我们先讨论一下如何存储表格数据。实际上,所有数据格式都继承自计算机科学家已知的两种主要内存布局之一(见图 3 ):
结构数组( AO ):潜在不同类型的一个或多个数据点 x 、 y , z … 的序列表示为 structure S 。这些数据点的几个实例被分配为新数据类型 S 的数组 s 。然后通过结构实例 s[k]。 的成员 s [k] x , s [k] y , s [k 。 z 。。。 访问第 k- 个实例的原始点列表 x 、 y , z …
数组结构( SoA ):数据点 x 、 y , z … 的多个实例存储在单独的数组 s _ x , s _ y , s _ z … 中 k- 第个实例的原始点 x 、 y , z … 然后被 s _ x [k], s _ y [k], s _ z [k] 访问。最后,这些数组可以解释为一个(仅仅是虚拟存在的)结构的单个实例,因此命名为 SoA 。

图 3 : AoS (左)和 SoA (右)内存布局的比较。白色箭头表示线性内存中的读取顺序。注意, AoS 和 SoA 通过换位是同构的。
虽然从编程和抽象的角度来看, AoS 布局看起来比 SoA 更结构化(双关语),但就可实现的性能而言,它往往不太适合大规模并行算法。这可以解释为当一致地访问结构成员的子集时(例如,在沿一个坐标轴减少值的过程中),缓存线的利用效率较低。您甚至可以在文献中发现,与 AOS 内存布局中的普通处理相比,动态 AoS-to-SoA 转换可以显著提高性能。
在复制数据的坐标切片时, SoA 内存布局显示出进一步的优势。假设您希望一次传输所有 x 坐标,那么就可以访问相应的数组,而无需在 AoS 布局中对成员进行耗时的切片。更好的是,在传输数据时,只需在内存中公开数组地址而不复制单个字节,就可以避免分配辅助内存。 阿帕奇箭头 构建在这种方法的基础上:出于讨论的原因,将不同数据类型的数据存储在不同的数组中(见图 4 )。请注意,主流数据科学框架将 SoA 布局中的数组项视为存储在列而不是行中,如图 3 所示。然而,这只是一种惯例,因为我们都知道,几乎所有内存都是线性排序的。
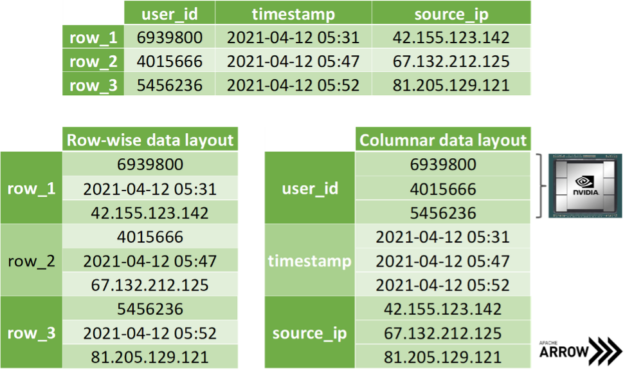
图 4 :顶部显示的同一个表的行( AoS ,左)和列( SoA ,右)内存布局的比较。 SoA 非常适合在 GPU 上进行大规模并行处理。
数据格式和零拷贝机制
近年来,为了满足不同的需求,开发了不同的图书馆。与此同时,数据科学管道变得越来越复杂,需要使用多个库来完成各种各样的任务。不幸的是,在设计这些库时,框架之间的互操作性并不是最优先考虑的。因此,缺乏适合数据科学任务的标准化数据格式。当时有些人担心数据标准,比如 pandas 项目的创建者 麦金尼 。 2011 年,他发表了 本帖 ,介绍了 Python 中丰富科学数据结构的未来路线图。
由于每个库都实现了其自定义的内存中数据布局和文件格式,因此当这些库需要协作时,必须执行昂贵的复制和转换操作。总执行时间的很大一部分被投入到无意义的复制和转换操作中是很常见的。
2016 年 10 月, Apache 基金会发布了 Arrow ,这是一种独立于语言的柱状数据格式规范,旨在有效地处理 CPU S 和 GPU S 上的平坦和分层数据。从那时起,许多不同的框架都采用了它,促进了它们之间的零拷贝数据交换。 Apache Arrow 柱状数据格式的其他 主要特征 包括:
O ( 1 )(恒定时间)随机存取
SIMD 和矢量化友好
顺序访问(扫描)的数据邻接
无需“指针旋转”即可重新定位,允许在共享内存中进行真正的零拷贝访问
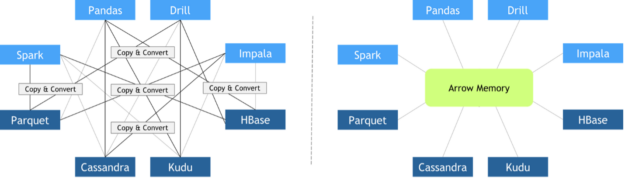
图 5 :传统框架互操作性与使用 ApacheArrow 的零拷贝方法的比较,其中所有框架都同意相同的内存布局。
零拷贝机制避免了不必要的数据传输,大大缩短了应用程序的执行时间。数据科学框架增加了对以下一种或多种数据格式的支持: DLPack 、 CUDA 阵列接口 和 NumPy 阵列接口 。
DLPack 是一种开放式内存张量结构,用于在框架之间共享张量。 CUDA 数组接口和 NumPy 数组接口是交换 GPU 和 CPU 类数组对象的事实标准。
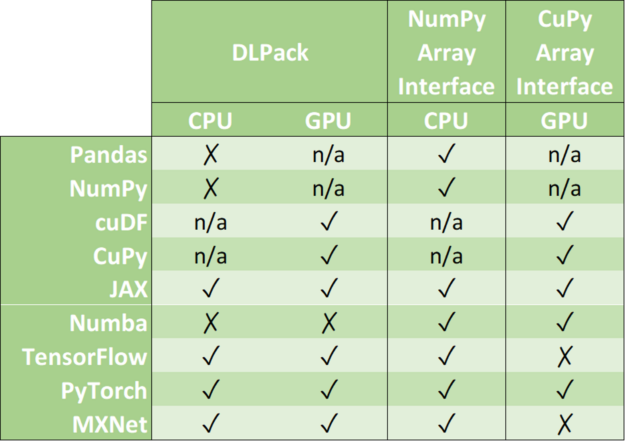
表 1 :数据格式支持矩阵。
请注意, cuDF 和 CuPy 等库只在 GPU 设备上运行。虽然可以将 NumPy 数组转换为 cuDF 或 CuPy 对象,但我们已将其支持标记为 n/a ,因为它请求主机内存( CPU )和设备内存( GPU )之间的数据移动。
在下文中,我们将讨论各种框架中关联数据对象的内存布局、使用零拷贝高效转换数据对象,以及混合框架时使用联合内存池。
内存池
内存分配很昂贵。它们通常会设置全球壁垒,在分配完成之前阻碍剩余的业务。因此,从性能的角度来看,在训练神经网络的过程中,重复分配紧循环的内存是禁止的。现代数据科学和深度学习框架通过专用内存池解决了这一问题。它要么在程序开始时预先分配一大块内存(例如, TensorFlow ),要么使用一些不频繁的分配(例如, PyTorch )来递增池。然后,通过异步地将该内存范围的子集分配给/从任何请求它的人收回,以智能的方式重用预先分配的内存。例如, RAPIDS 内存管理器( RMM ) 是最初为 RAPIDS 数据科学框架编写的内存池。 RMM 促进了极快的主机和设备内存分配。 麦克哈里斯 量化了 本帖 中 RMM 的影响:“我们通过使用 RMM 分配替换对 %s :没有足够的空闲空间 和 %s :没有足够的空闲空间 的所有调用,在 cuDF 中集中了内存管理。这是一个很大的工作,但它得到了回报。 RMM 调用的速度大约是 马洛克 和 cudaFree 的 1000 倍。结果是抵押贷款演示的速度提高了 10 倍。”
当组合不同的数据科学库时,几个特定于库的内存池 MIG ht 竞争相同的视频 RAM 。一个简单的解决方法是将每个内存池的容量限制为可用内存的固定分区。更好的解决方案是对所有框架使用相同的内存池。请注意,这并不一定意味着所有框架都必须同意其普通版本中提供的相同内存池实现。所有供应商都同意使用外部分配器接口( EAI )来请求和释放其框架中的内存就足够了。
void* allocate(std::size_t bytes, cudaStream_t stream) void deallocate(void* p, std::size_t bytes, cudaStream_t stream)
EAI 的进一步优势是直观的日志记录功能、内存泄漏检查以及速率或资源限制功能。例如, RAPIDS 内存管理器利用统一内存透明地超额订阅 GPU 内存。前者意味着在处理不适合 GPU 内存的大型数据集时,显著降低了内存不足错误的几率。
好消息是,在导入其他所有内容之前,只需导入 RAPIDS cuDF ,就可以将 RMM 与 CuPy 和 Numba 一起使用。
import cudf # <= now RMM is the global memory pool import cupy import numba
或者,您可以在不使用 RAPIDS cuDF 的情况下组合使用 Numba 和 RMM 。
import rmm from numba import cuda cuda.set_memory_manager(rmm.RMMNumbaManager)
结论
在我们的框架互操作性系列的这篇文章中,您了解了不同的内存布局,以及 Apache Arrow 格式如何显著加快跨不同数据科学和机器学习框架(如 TensorFlow 、 PyTorch 、 MXNet 、 cuDF 、 丘比。 、 麻木 和 JAX 的数据传输。我们还讨论了由内存池促进的异步内存分配对于避免高达管道总运行时间 90% 的开销至关重要。
在本系列的第二部分中,您将了解如何利用远程直接内存访问( RDMA )在多 GPU 设置中进一步加速数据加载和数据传输。
关于作者
Christian Hundt 在德国美因茨的 Johannes Gutenberg 大学( JGU )获得了理论物理的文凭学位。在他的博士论文中,他研究了时间序列数据挖掘算法在大规模并行架构上的并行化。作为并行和分布式体系结构组的博士后研究员,他专注于各种生物医学应用的高效并行化,如上下文感知的元基因组分类、基因集富集分析和胸部 mri 的深层语义图像分割。他目前的职位是深度学习解决方案架构师,负责协调卢森堡的 NVIDIA 人工智能技术中心( NVAITC )的技术合作。
Miguel Martinez 是 NVIDIA 的高级深度学习数据科学家,他专注于 RAPIDS 和 Merlin 。此前,他曾指导过 Udacity 人工智能纳米学位的学生。他有很强的金融服务背景,主要专注于支付和渠道。作为一个持续而坚定的学习者, Miguel 总是在迎接新的挑战。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
11320浏览量
225832 -
gpu
+关注
关注
28文章
5258浏览量
136039 -
内存
+关注
关注
9文章
3230浏览量
76496
发布评论请先 登录

吉事励引领电动汽车充电互操作性与兼容性测试新风向


是德科技携手爱立信赋能Pre-6G互操作性验证
通过恩智浦RW612三频无线MCU提升多协议互操作性
IO序列化操作:提升系统互操作性的关键技术

【「Linux 设备驱动开发(第 2 版)」阅读体验】+读深入理解Linux内核内存分配
集装箱储能系统标准解析系列(一)|IEC 62933-2-1:电能存储(EES)系统 第2-1部分-储能单元参数和试验方法

集装箱储能系统标准解析系列(三)| IEC TS 62933-4-1电能存储系统(EES) 第4-1部分:环境问题指导
是德科技与HEAD acoustics成功完成新一代eCall系统互操作性测试
灵活高效ZBUFF — C内存数据操作库:优化内存管理的利器

灵活高效双引擎驱动:ZBUFF让C语言内存操作更智能!



评论