 通过NVIDIA GPU内存预取实现应用程序性能的提高
通过NVIDIA GPU内存预取实现应用程序性能的提高

NVIDIA GPU 具有强大的计算能力,通常必须以高速传输数据才能部署这种能力。原则上这是可能的,因为 GPU 也有很高的内存带宽,但有时他们需要你的帮助来饱和带宽。
在本文中,我们将研究一种实现这一点的特定方法:预取。我们将解释在什么情况下预取可以很好地工作,以及如何找出这些情况是否适用于您的工作负载。
上下文
NVIDIA GPU 从大规模并行中获得力量。 32 个线程的许多扭曲可以放置在流式多处理器( SM )上,等待轮到它们执行。当一个 warp 因任何原因暂停时, warp 调度程序会以零开销切换到另一个,确保 SM 始终有工作要做。
在高性能的 NVIDIA Ampere 架构 A100 GPU 上,多达 64 个活动翘板可以共享一个 SM ,每个都有自己的资源。除此之外, A100 还有 108 条短信,可以同时执行 warp 指令。
大多数指令都必须对数据进行操作,而这些数据几乎总是源于连接到 GPU 的设备内存( DRAM )。 SM 上大量的翘曲都可能无法工作的一个主要原因是,它们正在等待来自内存的数据。
如果出现这种情况,并且内存带宽没有得到充分利用,则可以重新组织程序,以改善内存访问并减少扭曲暂停,从而使程序更快地完成。这叫做延迟隐藏。
预取
CPU 上的硬件通常支持的一种技术称为预取。 CPU 看到来自内存的请求流到达,找出模式,并在实际需要数据之前开始获取数据。当数据传输到 CPU 的执行单元时,可以执行其他指令,有效地隐藏传输成本(内存延迟)。
预取是一种有用的技术,但就芯片上的硅面积而言很昂贵。相对而言, GPU 的这些成本甚至更高,因为 GPU 的执行单元比 CPU 多得多。相反, GPU 使用多余的扭曲来隐藏内存延迟。当这还不够时,可以在软件中使用预取。它遵循与硬件支持的预取相同的原理,但需要明确的指令来获取数据。
要确定此技术是否能帮助您的程序更快地运行,请使用 GPU 评测工具(如 NVIDIA Nsight Compute )检查以下内容:
确认没有使用所有内存带宽。
确认翘曲被阻止的主要原因是 摊位长记分牌 ,这意味着 SMs 正在等待来自 DRAM 的数据。
确认这些暂停集中在迭代互不依赖的大型循环中。
展开
考虑这种循环的最简单可能的优化,称为展开。如果循环足够短,可以告诉编译器完全展开循环,并显式展开迭代。由于迭代是独立的,编译器可以提前发出所有数据请求(“加载”),前提是它为每个加载分配不同的寄存器。
这些请求可以相互重叠,因此整个负载集只经历一个内存延迟,而不是所有单个延迟的总和。更妙的是,加载指令本身的连续性隐藏了单个延迟的一部分。这是一种接近最优的情况,但可能需要大量寄存器才能接收加载结果。
如果循环太长,可能会部分展开。在这种情况下,成批的迭代会被扩展,然后您会遵循与之前相同的一般策略。你的工作很少(但你可能没那么幸运)。
如果循环包含许多其他指令,这些指令的操作数需要存储在寄存器中,那么即使只是部分展开也可能不是一个选项。在这种情况下,在您确认满足之前的条件后,您必须根据进一步的信息做出一些决定。
预取意味着使数据更接近 SMs 的执行单元。寄存器是最接近的。如果有足够的可用空间(可以使用 Nsight Compute Occupation 视图找到),可以直接预取到寄存器中。
考虑下面的循环,其中数组arr被存储在全局存储器( DRAM )中。它隐式地假设只使用了一个一维线程块,而对于从中派生的激励应用程序来说,情况并非如此。然而,它减少了代码混乱,并且不会改变参数。
在本文的所有代码示例中,大写变量都是编译时常量。BLOCKDIMX假定预定义变量blockDim.x的值。出于某些目的,它必须是编译时已知的常数,而出于其他目的,它有助于避免在运行时进行计算。
for (i=threadIdx.x; i };>
假设您有八个寄存器用于预取。这是一个调整参数。下面的代码在每四次迭代开始时获取四个双精度值,占据八个 4 字节寄存器,并逐个使用它们,直到批耗尽,此时您将获取一个新批。
为了跟踪批处理,引入一个计数器(ctr),该计数器随着线程执行的每个后续迭代而递增。为了方便起见,假设每个线程的迭代次数可以被 4 整除。
double v0, v1, v2, v3; for (i=threadIdx.x, ctr=0; i };>
通常,预取的值越多,该方法就越有效。虽然前面的例子并不复杂,但有点麻烦。如果预取值(PDIST或预取距离)的数量发生变化,则必须添加或删除代码行。
将预取值存储在共享内存中更容易,因为您可以使用数组表示法,无需任何努力就可以改变预取距离。然而,共享内存并不像寄存器那样接近执行单元。当数据准备好使用时,它需要一条额外的指令将数据从那里移动到寄存器中。为了方便起见,我们引入宏vsmem来简化共享内存中数组的索引:
#define vsmem(index) v[index+PDIST*threadIdx.x] __shared__ double v[PDIST* BLOCKDIMX]; for (i=threadIdx.x, ctr=0; i };>
除了批量预取,还可以进行“滚动”预取。在这种情况下,在进入主循环之前填充预取缓冲区,然后在每次循环迭代期间从内存中预取一个值,以便在以后的PDIST迭代中使用。下一个示例使用数组表示法和共享内存实现滚动预取。
__shared__ double v[PDIST* BLOCKDIMX]; for (k=0; k };>
与批处理方法相反,滚动预取在主循环执行期间不会再出现足够大的预取距离的内存延迟。它还使用相同数量的共享内存或寄存器资源,因此它似乎是首选。然而,一个微妙的问题可能会限制其有效性。
循环中的同步(例如,syncthreads)构成了一个内存围栏,并迫使arr的加载在同一迭代中的该点完成,而不是在以后的 PDIST 迭代中完成。解决方法是使用异步加载到共享内存中,最简单的版本在 CUDA 程序员指南的 Pipeline interface 部分中解释。这些异步加载不需要在同步点完成,只需要在显式等待时完成。
以下是相应的代码:
#include __shared__ double v[PDIST* BLOCKDIMX]; for (k=0; k };>
由于每一条__pipeline_wait_prior指令都必须与一条__pipeline_commit指令匹配,我们在进入主计算循环之前,将后者放入预取缓冲区的循环中,以简化匹配指令对的簿记。
绩效结果
图 1 显示,对于不同的预取距离,在前面描述的五种算法变化下,从金融应用程序中获取的内核的性能改进。
分批预取到寄存器(标量分批)
分批预取到共享内存( smem 分批)
将预取滚动到寄存器(标量滚动)
将预取滚动到共享内存( smem 滚动)
使用异步内存拷贝将预取滚动到共享内存( smem 滚动异步)
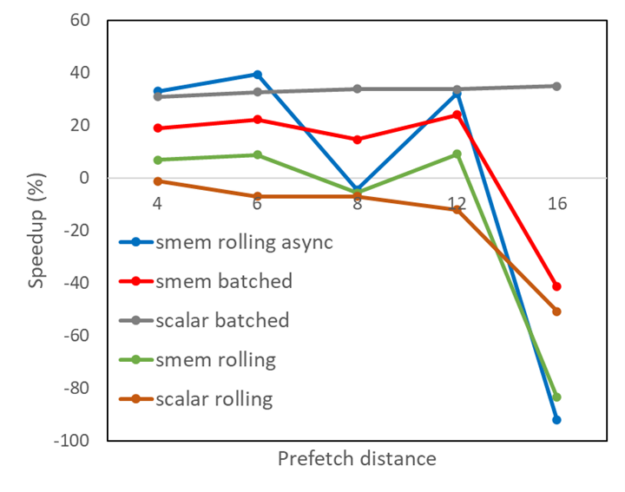
图 1 。不同预取策略的内核加速
显然,将预取滚动到具有异步内存拷贝的共享内存中会带来很好的好处,但随着预取缓冲区大小的增加,这是不均匀的。
使用 Nsight Compute 对结果进行更仔细的检查后发现,共享内存中会发生内存组冲突,这会导致异步负载的扭曲被拆分为比严格必要的更连续的内存请求。经典的优化方法是在共享内存中填充数组大小,以避免错误的跨步,这种方法在这种情况下有效。PADDING的值的选择应确保PDIST和PADDING之和等于二加一的幂。将其应用于所有使用共享内存的变体:
#define vsmem(index) v[index+(PDIST+PADDING)*threadIdx.x]
这导致图 2 所示的共享内存结果得到改善。预取距离仅为 6 ,再加上以滚动方式进行的异步内存拷贝,就足以以比原始版本代码近 60% 的加速比获得最佳性能。实际上,我们可以通过更改共享内存中数组的索引方案来实现这种性能改进,而无需使用填充,这是留给读者的练习。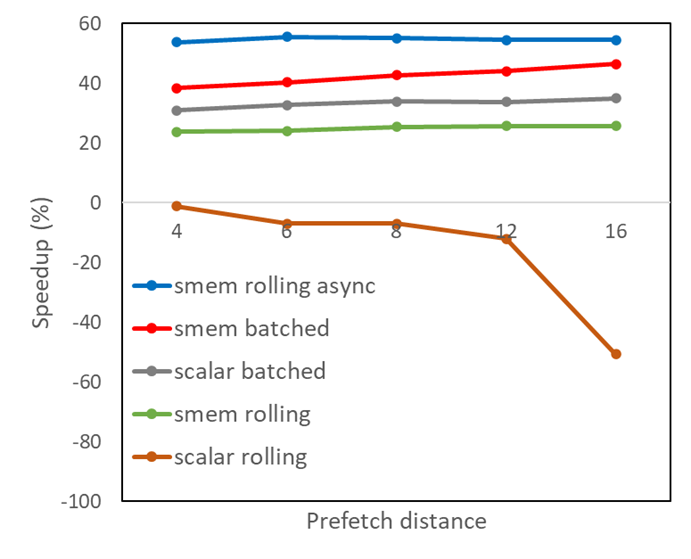
图 2 。使用共享内存填充的不同预取策略的内核加速
一个尚未讨论的 预取的变化 将数据从全局内存移动到二级缓存,如果共享内存中的空间太小,无法容纳所有符合预取条件的数据,这可能很有用。这种类型的预取在 CUDA 中无法直接访问,需要在较低的 PTX 级别进行编程。
总结
在本文中,我们向您展示了源代码的本地化更改示例,这些更改可能会加快内存访问。这些不会改变从内存移动到 SMs 的数据量,只会改变时间。通过重新安排内存访问,使数据在到达 SM 后被多次重用,您可以进行更多优化。
关于作者
Rob Van der Wijngaart 是 NVIDIA 的高级高性能计算( HPC )架构师。他在各种工业和政府实验室从事 HPC 领域的研究超过三十年,是广泛使用的 NAS 并行基准测试的共同开发者。Ren é Peters 是 NVIDIA 的产品经理,他在增强/虚拟现实和人工智能的交叉点指导产品开发。在科技行业任职期间,他还与物联网( IoT )和云计算等技术合作。迈尔斯·麦克林( Miles Macklin )是NVIDIA 的首席工程师,致力于模拟技术。他从哥本哈根大学获得计算机科学博士学位,从事计算机图形学、基于物理学的动画和机器人学的研究。他在 ACM SIGGRAPH 期刊上发表了几篇论文,他的研究已经被整合到许多商业产品中,包括NVIDIA 的 PhysX 和 ISAAC 健身房模拟器。他最近的工作旨在为 GPU 上的可微编程开发健壮高效的框架。
Fred Oh 是 CUDA 、 CUDA on WSL 和 CUDA Python 的高级产品营销经理。弗雷德拥有加州大学戴维斯分校计算机科学和数学学士学位。他的职业生涯开始于一名 UNIX 软件工程师,负责将内核服务和设备驱动程序移植到 x86 体系结构。他喜欢《星球大战》、《星际迷航》和 NBA 勇士队。
审核编辑:郭婷
-
存储器
+关注
关注
39文章
7771浏览量
172490 -
NVIDIA
+关注
关注
14文章
5732浏览量
110336 -
gpu
+关注
关注
28文章
5337浏览量
136263
发布评论请先 登录
微基准测试的性能特征及如何在应用程序中使用统一内存
NVIDIA火热招聘GPU高性能计算架构师
GPU加速XenApp/Windows 2016/Office/IE性能会提高吗
探求NVIDIA GPU极限性能的利器
近600个应用程序通过NVIDIA GPU实现了提速
LabVIEW应用程序中性能瓶颈的解决
使用NVIDIA TensorRT部署实时深度学习应用程序
如何使用NVIDIA Docker部署GPU服务器应用程序
通过GPU内存访问调整提高应用程序性能
使用Brocade Gen 7 SAN确保应用程序性能和可靠性




评论