 HugeCTR能够高效地利用GPU来进行推荐系统的训练
HugeCTR能够高效地利用GPU来进行推荐系统的训练

1. Introduction
HugeCTR 能够高效地利用 GPU 来进行推荐系统的训练,为了使它还能直接被其他 DL 用户,比如 TensorFlow 所直接使用,我们开发了 SparseOperationKit (SOK),来将 HugeCTR 中的高级特性封装为 TensorFlow 可直接调用的形式,从而帮助用户在 TensorFlow 中直接使用 HugeCTR 中的高级特性来加速他们的推荐系统。
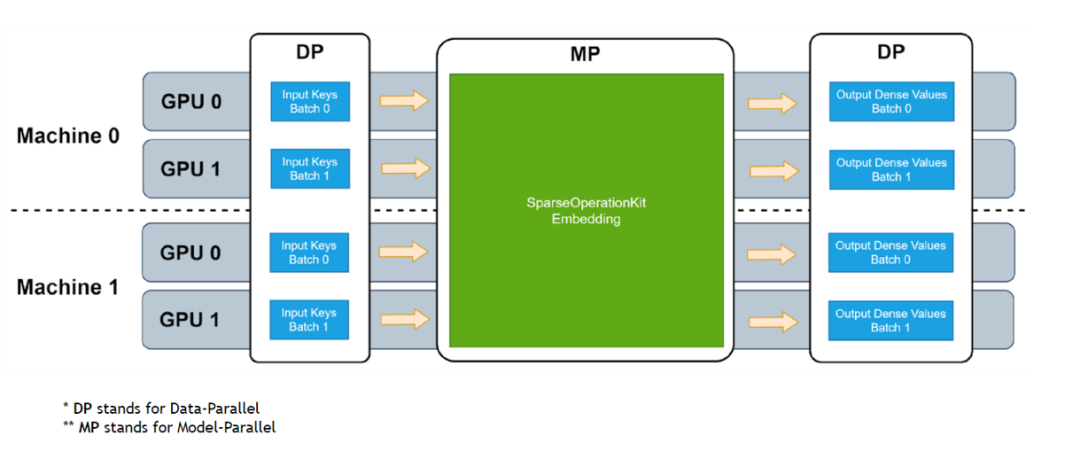
图 1. SOK embedding 工作流程
SOK 以数据并行的方式接收输入数据,然后在 SOK 内部做黑盒式地模型转换,最后将计算结果以数据并行的方式传递给初始 GPU。这种方式可以尽可能少地修改用户已有的代码,以更方便、快捷地在多个 GPU 上进行扩展。
SOK 不仅仅是加速了 TensorFlow 中的算子,而是根据业界中的实际需求提供了对应的新解决方案,比如说 GPU HashTable。SOK 可以与 TensorFlow 1.15 和 TensorFlow 2.x 兼容使用;既可以使用 TensorFlow 自带的通信工具,也可以使用 Horovod 等第三方插件来作为 embedding parameters 的通信工具。
使用 MLPerf 的标准模型 DLRM 来对 SOK 的性能进行测试。
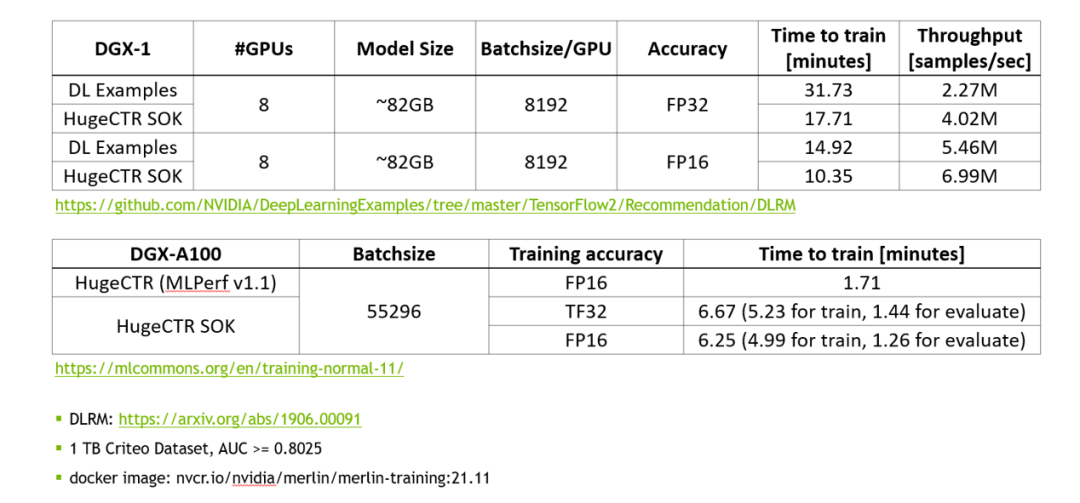
图 2. SOK 性能测试数据
相比于 NVIDIA 的 DeepLearning Examples,使用 SOK 可以获得更快的训练速度以及更高的吞吐量。
3. API
SOK 提供了简洁的、类 TensorFlow 的 API;使用 SOK 的方式非常简单、直接;让用户通过修改几行代码就可以使用 SOK。
1. 定义模型结构

左侧是使用 TensorFlow 的 API 来搭建模型,右侧是使用 SOK 的 API 来搭建相同的模型。使用 SOK 来搭建模型的时候,只需要将 TensorFlow 中的 Embedding Layer 替换为 SOK 对应的 API 即可。
2. 使用 Horovod 来定义 training loop

同样的,左侧是使用 TensorFlow 来定义 training loop,右侧是使用 SOK 时,training loop 的定义方式。可以看到,使用 SOK 时,只需要对 Embedding Variables 和 Dense Variables 进行分别处理即可。其中,Embedding Variables 部分由 SOK 管理,Dense Variables 由 TensorFlow 管理。
3. 使用 tf.distribute.MirroredStrategy 来定义 training loop

类似的,还可以使用 TensorFlow 自带的通信工具来定义 training loop。
4. 开始训练

在开始训练过程时,使用 SOK 与使用 TensorFlow 时所用代码完全一致。
4. 结语
SOK 将 HugeCTR 中的高级特性包装为 TensorFlow 可以直接使用的模块,通过修改少数几行代码即可在已有模型代码中利用上 HugeCTR 的先进设计。
审核编辑 :李倩
-
gpu
+关注
关注
28文章
5283浏览量
136094 -
SOK
+关注
关注
0文章
5浏览量
6475
原文标题:Merlin HugeCTR Sparse Operation Kit 系列之一
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于openEuler平台的CPU、GPU与FPGA异构加速实战

GPU 利用率<30%?这款开源智算云平台让算力不浪费 1%
利用 Banana Pi BPI-CM5 Pro(ARMSoM CM5 SoM) 加速保护科学
在Ubuntu20.04系统中训练神经网络模型的一些经验
提高RISC-V在Drystone测试中得分的方法
NVIDIA Isaac Lab多GPU多节点训练指南
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
PCIe协议分析仪能测试哪些设备?
aicube的n卡gpu索引该如何添加?
如何在Ray分布式计算框架下集成NVIDIA Nsight Systems进行GPU性能分析
别让 GPU 故障拖后腿,捷智算GPU维修室来救场!

利用API提升电商用户体验:个性化推荐系统

SL3075 dcdc65V耐压 5A电流高效率降压芯片替换TPS54340
Vicor高效电源模块优化自动驾驶系统
提升AI训练性能:GPU资源优化的12个实战技巧




评论