 用NVIDIA H100 CNX构建人工智能系统
用NVIDIA H100 CNX构建人工智能系统

人们对能够以更快的速度将数据从网络传输到 GPU 的服务器的需求不断增加。随着人工智能模型不断变大,训练所需的数据量需要多节点训练等技术才能在合理的时间范围内取得成果。 5G 的信号处理比前几代更复杂, GPU 可以帮助提高这种情况发生的速度。机器人或传感器等设备也开始使用 5G 与边缘服务器通信,以实现基于人工智能的决策和行动。
专门构建的人工智能系统,比如最近发布的 NVIDIA DGX H100 ,是专门为支持数据中心用例的这些需求而设计的。现在,另一种新产品可以帮助企业获得更快的数据传输和更高的边缘设备性能,但不需要高端或定制系统。
NVIDIA 首席执行官 Jensen Huang 上周在 NVIDIA 公司 GTC 宣布, NVIDIA H100 CNX 是一个高性能的企业包。它结合了 NVIDIA H100 的能力与 NVIDIA ConnectX-7 SmartNIC 先进的网络能力。这种先进的体系结构在 PCIe 板上提供,为主流数据中心和边缘系统的 GPU 供电和 I / O 密集型工作负载提供了前所未有的性能。
H100 CNX 的设计优势
在标准 PCIe 设备中,控制平面和数据平面共享相同的物理连接。然而,在 H100 CNX 中, GPU 和网络适配器通过直接 PCIe Gen5 通道连接。这为 GPU 和使用 GPUDirect RDMA 的网络之间的数据传输提供了专用的高速路径,并消除了通过主机的数据瓶颈。
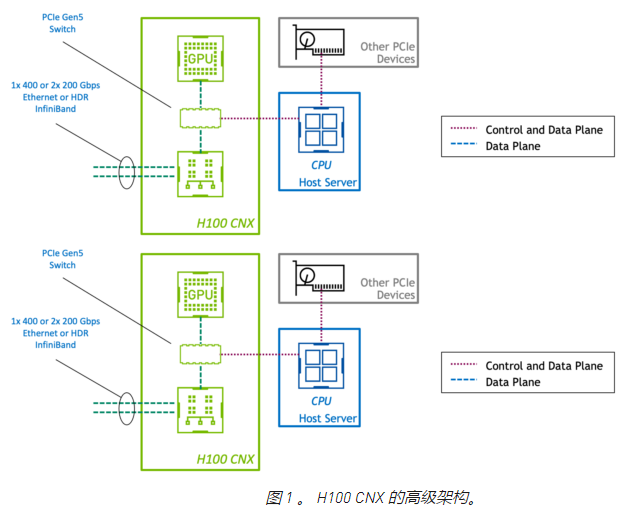
通过将 GPU 和 SmartNIC 组合在一块板上,客户可以利用 PCIe Gen4 甚至 Gen3 上的服务器。通过高端或专门构建的系统实现一次性能水平可以节省硬件成本。将这些组件放在一块物理板上也可以提高空间和能源效率。
将 GPU 和 SmartNIC 集成到单个设备中,通过设计创建了一个平衡的体系结构。在具有多个 GPU 和 NIC 的系统中,聚合加速卡强制 GPU 与 NIC 的比例为 1:1 。这避免了服务器 PCIe 总线上的争用,因此性能会随着附加设备线性扩展。
NVIDIA 的核心加速软件库(如 NCCL 和 UCX )自动利用性能最佳的路径将数据传输到 GPU 。现有的加速多节点应用程序可以在不做任何修改的情况下利用 H100 CNX ,因此客户可以立即从高性能和可扩展性中受益。
H100 CNX 用例
H100 CNX 提供 GPU 加速,同时具有低延迟和高速网络。这是在较低的功耗下完成的,与两个分立的卡相比,占用空间更小,性能更高。许多用例可以从这种组合中受益,但以下几点尤其值得注意。
5G 信号处理
使用 GPU 进行 5G 信号处理需要尽快将数据从网络移动到 GPU ,并且具有可预测的延迟也是至关重要的。 NVIDIA 聚合加速器与 NVIDIA Aerial SDK 相结合,为运行 5G 应用程序提供了性能最高的平台。由于数据不经过主机 PCIe 系统,因此处理延迟大大减少。在使用速度较慢的 PCIe 系统的商品服务器时,甚至可以看到这种性能的提高。
加速 5G 以上的边缘人工智能
NVIDIA AI on 5G 由 NVIDIA EGX 企业平台、 NVIDIA 公司的 SDK 软件定义的 5G 虚拟无线局域网和企业 AI 框架组成。这包括像 NVIDIA ISAAC 和 NVIDIA Metropolis 这样的 SDK 。摄像机、工业传感器和机器人等边缘设备可以使用人工智能,并通过 5G 与服务器通信。
H100 CNX 可以在单个企业服务器中提供此功能,而无需部署昂贵的专用系统。与NVIDIA 多实例 GPU 技术相比,应用于 5G 信号处理的相同加速器可用于边缘 AI 。这使得共享 GPU 用于多种不同目的成为可能。
多节点人工智能训练
多节点培训涉及不同主机上 GPU 之间的数据传输。在一个典型的数据中心网络中,服务器通常会在性能、规模和密度方面受到各种限制。大多数企业服务器不包括 PCIe 交换机,因此 CPU 成为这种流量的瓶颈。数据传输受主机 PCIe 背板的速度限制。虽然 GPU:NIC 的比例为 1:1 是理想的,但服务器中 PCIe 通道和插槽的数量可能会限制设备的总数。
H100 CNX 的设计缓解了这些问题。从网络到 GPU 有一条专用路径,供 GPUDirect RDMA 以接近线路速度运行。无论主机 PCIe 背板如何,数据传输也会以 PCIe Gen5 的速度进行。主机内 GPU 功率的放大可以以平衡的方式进行,因为 GPU:NIC 的比例是 1:1 。服务器还可以配备更多的加速能力,因为与离散卡相比,聚合加速器所需的 PCIe 通道和设备插槽更少。
NVIDIA H100 CNX 预计可在今年下半年购买。如果你有一个用例可以从这个独特而创新的产品中受益,请联系你最喜欢的系统供应商,询问他们计划何时将其与服务器一起提供。
关于作者:About Charu Chaubal
Charu Chaubal 在NVIDIA 企业计算平台集团从事产品营销工作。他在市场营销、客户教育以及技术产品和服务的售前工作方面拥有 20 多年的经验。 Charu 曾在云计算、超融合基础设施和 IT 安全等多个领域工作。作为 VMware 的技术营销领导者,他帮助推出了许多产品,这些产品共同发展成为数十亿美元的业务。此前,他曾在 Sun Microsystems 工作,在那里他设计了分布式资源管理和 HPC 基础设施软件解决方案。查鲁拥有化学工程博士学位,并拥有多项专利。
-
人工智能
+关注
关注
1821文章
50519浏览量
267766 -
5G
+关注
关注
1368文章
49252浏览量
644191 -
H100
+关注
关注
0文章
33浏览量
624
发布评论请先 登录
基于Arm架构的NVIDIA DGX Spark平台构建离线语音助手系统

AI爆款应用驱动需求增长,英伟达H100租赁费用飙升40%

中软国际教育科技集团携手兰州大学构建人工智能通识创新实验室
Magna AI加入NVIDIA Inception计划,推动生产级人工智能规模化发展
使用OpenUSD与NVIDIA Halos构建安全物理AI系统
嵌入式系统中的人工智能

英伟达 H100 GPU 掉卡?做好这五点,让算力稳如泰山!




评论