 python网络爬虫概述
python网络爬虫概述

网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
网络爬虫按照系统结构和实现技术,大致可分为一下几种类型:
通用网络爬虫:就是尽可能大的网络覆盖率,如 搜索引擎(百度、雅虎和谷歌等…)。
聚焦网络爬虫:有目标性,选择性地访问万维网来爬取信息。
增量式网络爬虫:只爬取新产生的或者已经更新的页面信息。特点:耗费少,难度大
深层网络爬虫:通过提交一些关键字才能获取的Web页面,如登录或注册后访问的页面。
应用场景
爬虫技术在科学研究、Web安全、产品研发、舆情监控等领域可以做很多事情。
在数据挖掘、机器学习、图像处理等科学研究领域,如果没有数据,则可以通过爬虫从网上抓取;
在Web安全方面,使用爬虫可以对网站是否存在某一漏洞进行批量验证、利用;
在产品研发方面,可以采集各个商城物品价格,为用户提供市场最低价;
在舆情监控方面,可以抓取、分析新浪微博的数据,从而识别出某用户是否为水军
学习爬虫前的技术准备
(1). Python基础语言: 基础语法、运算符、数据类型、流程控制、函数、对象 模块、文件操作、多线程、网络编程 … 等
(2). W3C标准: HTML、CSS、JavaScript、Xpath、JSON
(3). HTTP标准: HTTP的请求过程、请求方式、状态码含义,头部信息以及Cookie状态管理
(4). 数据库: SQLite、MySQL、MongoDB、Redis …
关于爬虫的合法性
几乎每个网站都有一个名为robots.txt的文档,当然也有有些网站没有设定。对于没有设定robots.txt的网站可以通过网络爬虫获取没有口令加密的数据,也就是该网站所有页面的数据都可以爬取。如果网站有文件robots.txt文档,就要判断是否有禁止访客获取数据 如:https://www.baidu.com/robots.txt
-
机器学习
+关注
关注
67文章
8574浏览量
137559 -
python
+关注
关注
60文章
4896浏览量
90597 -
爬虫
+关注
关注
0文章
87浏览量
8242
发布评论请先 登录
onsemi PYTHON系列图像传感器:技术解析与应用指南
onsemi PYTHON 480图像传感器:特性、应用与设计要点
Python全栈一课通(470集)(12.96 GB)-网盘资源下载
使用PYTHON进行的跨平台仿真
[VirtualLab] 使用Python运行VirtualLab Fusion光学仿真
[VirtualLab] 使用Python进行跨平台参数扫描
如何在 VisionFive 上使用 Python 包?
京东关键词搜索商品列表的Python爬虫实战
没有专利的opencv-python 版本
# 深度解析:爬虫技术获取淘宝商品详情并封装为API的全流程应用
用 Python 给 Amazon 做“全身 CT”——可量产、可扩展的商品详情爬虫实战
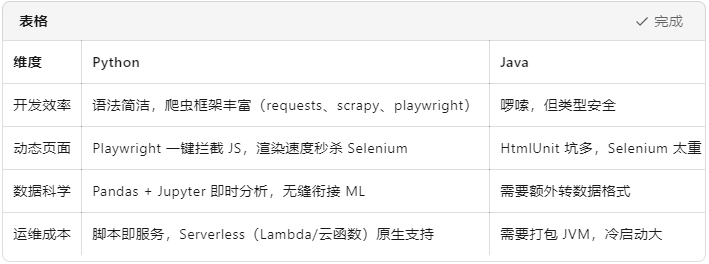
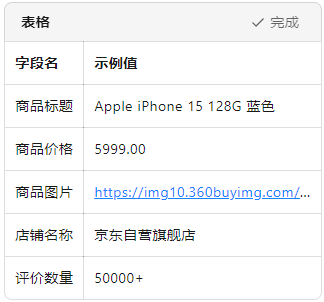
从 0 到 1:用 PHP 爬虫优雅地拿下京东商品详情



评论