 STM32Cube.AI库的高级特性
STM32Cube.AI库的高级特性

STM32Cube.AI是意法半导体AI生态系统的一部分,是STM32Cube的一个扩展包,它可以自动转换和优化预先训练的神经网络模型并将生成的优化库集成到用户项目中,从而扩展了STM32CubeMX的功能。它还提供几种在桌面PC和STM32上验证神经网络模型以及测量模型性能的方法,而无需用户手工编写专门的C语言代码。
上一篇文章大致介绍了STMCube.AI的基本特性,以及其工作流程。
本文将更深入地介绍它的一些高级特性。将涉及以下主题:
运行时环境支持:Cube.AI vs TensorFlow Lite
量化支持
图形流与存储布局优化
可重定位的二进制模型支持
运行时环境支持:Cube.AI vs TensorFlow Lite
STM32Cube.AI支持两种针对不同应用需求的运行时环境:Cube.AI和TensorFlow Lite。作为默认的运行时环境,Cube.AI是专为STM32高度优化的机器学习库。而TensorFlow Lite for Microcontroller是由谷歌设计,用于在各种微控制器或其他只有几KB存储空间的设备上运行机器学习模型的。其被广泛应用于基于MCU的应用场景。STM32Cube.AI集成了一个特定的流程,可以生成一个即时可用的STM32 IDE项目,该项目内嵌TensorFlow Lite for Microcontrollers运行时环境(TFLm)以及相关的TFLite模型。这可以被看作是Cube.AI运行时环境的一个替代方案,让那些希望拥有一个跨多个项目的通用框架的开发人员也有了选择。
虽然这两种运行时环境都是为资源有限的MCU而设计,但Cube.AI在此基础上针对STM32的独特架构进行了进一步优化。因此,TensorFlow Lite更适合有跨平台可移植性需求的应用,而Cube.AI则更适合对计算速度和内存消耗有更高要求的应用。
下表展示了两个运行时环境之间的性能比较(基于一个预训练的神经网络参考模型)。评价指标是在STM32上的推断时间和内存消耗。
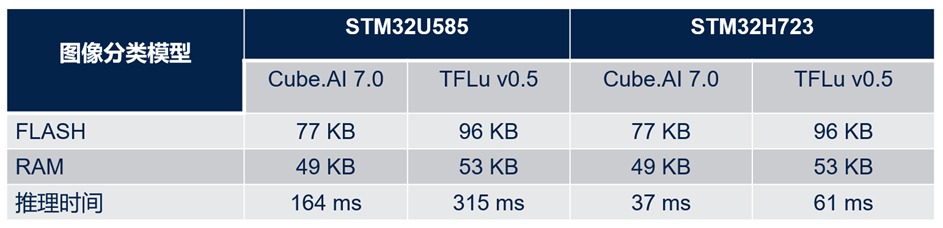
如表中所示,对于同一模型,Cube.AI运行时环境比TFLite运行时环境节约了大概20%的flash存储和约8%的RAM存储。此外,它的运行速度几乎比TFLite运行时环境快了2倍。
对于TFLite模型,用户可以在STM32Cube.AI的网络配置菜单中对2个运行时环境进行选择。
量化支持
量化是一种被广泛使用的优化技术,它将32位浮点模型压缩为位数更少的整数模型,在精度只略微下降的情况下,减少了存储大小和运行时的内存峰值占用,也减少了CPU/MCU的推断时间和功耗。量化模型对整数张量而不是浮点张量执行部分或全部操作。它是面向拓扑、特征映射缩减、剪枝、权重压缩等各种优化技术的重要组成部分,可应用在像MCU一样资源受限的运行时环境。
通常有两种典型的量化方法:训练后量化(PTQ)和量化训练(QAT)。PTQ相对容易实现,它可以用有限的具有代表性的数据集来量化预先训练好的模型。而QAT是在训练过程中完成的,通常具有更高的准确度。
STM32Cube.AI通过两种不同的方式直接或间接地支持这两种量化方法:
首先,它可以用来部署一个由PTQ或QAT过程生成的TensorFlow Lite量化模型。在这种情况下,量化是由TensorFlow Lite框架完成的,主要是通过“TFLite converter” utility导出TensorFlow Lite文件。
其次,其命令行接口(CLI)还集成了一个内部的训练后量化(PTQ)的过程,支持使用不同的量化方案对预训练好的Keras模型进行量化。与使用TFLite Converter工具相比,该内部量化过程提供了更多的量化方案,并在执行时间和精确度方面有更好的表现。
下表显示了在STM32上部署量化模型(与原有浮点模型相比)的好处。此表使用FD-MobileNet作为基准模型,共有12层,参数大小145k,MACC操作数24M,输入尺寸为224x224x3。
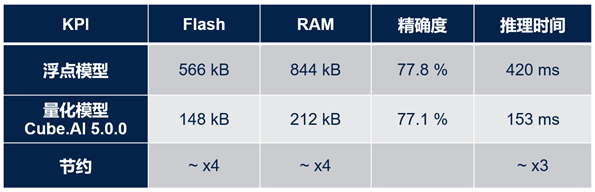
从表中很容易看出,量化模型节省了约4倍的flash存储和RAM存储,且运行速度提高了约3倍,而精确度仅仅下降了0.7%。
如果已经安装了X-Cube-AI包,用户可以通过以下路径找到关于如何使用命令行界面(CLI)进行量化的教程:
C:UsersusernameSTM32CubeRepositoryPacksSTMicroelectronicsX-CUBE-AI7.0.0Documentationquantization.html。
在文档的末尾还附上了一个快速实践示例:“量化一个MNIST模型”。
图形流与存储布局优化
除了量化技术,STM32Cube.AI还通过使用其C代码生成器的优化引擎,针对推理时间优化内存使用(RAM & ROM)。该引擎基于无数据集的方法,无需验证或测试数据集来应用压缩和优化算法。
第一种方法:权重/偏置项压缩,采用k -均值聚类算法。该压缩算法仅适用于全连接层。其优势是压缩速度快,但是结果并不是无损的,最终的精度可能会受到影响。STM32Cube.AI提供“验证”功能,用于对所生成的C模型中产生的误差进行评估。
“压缩”选项可以在STM32Cube.AI的网络配置中激活,如下图所示:
第二种方法:操作融合,通过合并层来优化数据布局和相关的计算核。转换或优化过程中会删除一些层(如“Dropout”、“Reshape”),而有些层(如非线性层以及卷积层之后的池化层)会被融合到前一层中。其好处是转换后的网络通常比原始网络层数少,降低了存储器中的数据吞吐需求。
最后一种方法是优化的激活项存储。其在内存中定义一个读写块来存储临时的隐藏层值(激活函数的输出)。此读写块可以被视为推理函数使用的暂存缓冲区,在不同层之间被重复使用。因此,激活缓冲区的大小由几个连续层的最大存储需求决定。比如,假设有一个3层的神经网络,每一层的激活值分别有5KB, 12KB和3KB,那么优化后的激活缓冲区大小将是12KB,而不是20KB。
可重定位的二进制模型支持
非可重定位方法(或“静态”方法)指的是:生成的神经网络C文件被编译并与最终用户应用程序堆栈静态链接在一起。
如下图所示,所有对象(包括神经网络部分和用户应用程序)根据不同的数据类型被一起链接到不同的部分。在这种情况下,当用户想要对功能进行部分更新时(比如只更新神经网络部分),将需要对整个固件进行更新。
相反,可重定位二进制模型指定一个二进制对象,该对象可以安装和执行在STM32内存子系统的任何位置。它是所生成的神经网络C文件的编译后的版本,包括前向核函数以及权重。其主要目的是提供一种灵活的方法来更新AI相关的应用程序,而无需重新生成和刷写整个终端用户固件。
生成的二进制对象是一个轻量级插件。它可以从任何地址(位置无关的代码)运行,其数据也可放置于内存中的任何地方(位置无关的数据)。
STM32Cube.AI简单而高效的AI可重定位运行时环境可以将其实例化并使用它。STM32固件中没有内嵌复杂的资源消耗型动态链接器,其生成的对象是一个独立的实体,运行时不需要任何外部变量或函数。
下图的左侧部分是神经网络的可重定位二进制对象,它是一个自给自足的独立实体,链接时将被放置于终端用户应用程序的一个单独区域中(右侧部分)。它可以通过STM32Cube.AI的可重定位运行时环境被实例化以及动态链接。因此,用户在更新AI模型时只需要更新这部分二进制文件。另外,如果有进一步的灵活性需求,神经网络的权重也可以选择性地被生成为独立的目标文件。
可重定位网络可以在STM32Cube.AI的高级设置中激活
最后,作为意法半导体人工智能生态系统的核心工具,STM32Cube.AI提供许多基本和高级功能,以帮助用户轻松创建高度优化和灵活的人工智能应用。如需详细了解特定解决方案或技术细节,请随时关注我们的后续文章。
责任编辑:haq
-
STM32
+关注
关注
2313文章
11196浏览量
374798 -
意法半导体
+关注
关注
31文章
3410浏览量
112112 -
AI
+关注
关注
91文章
41464浏览量
302791
原文标题:AI技术专题之五 |专为STM32 MCU优化的STM32Cube.AI库
文章出处:【微信号:STM32_STM8_MCU,微信公众号:STM32单片机】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
光子跃迁推出LEAPTIC Cube 8K AI拇指运动相机
华邦电子CUBE引领边缘AI存力革新
如何在 STM32Cube CMake 工程中添加源文件
LAT1574_如何在 STM32Cube CMake 工程中添加源文件
意法半导体STM32 MCU AI模型库再扩容
德赛西威推出机器人智能基座AI Cube
国产MCU开始卷开发工具了?McuStudio是对STM32Cube的拙劣模仿还是真香逆袭?
立即在GitHub上抢先体验面向STM32U5的最新STM32Cube HAL更新
HTTP开发必备:核心库与httpplus扩展库应用示例全攻略




评论