 有效解决内存墙问题 存算一体正处在快速发展阶段
有效解决内存墙问题 存算一体正处在快速发展阶段

电子发烧友网报道(文/李弯弯)随着技术的发展,现在计算的任务越来越复杂,需要的数据也越来越多,而在冯诺依曼架构中,数据需要在存储、内存、缓存、计算单元中不断搬运,造成大部分时间、带宽、缓存、功耗都消耗在数据搬运上,而不是计算上,因此内存墙都成了一个越来越严重的问题。
这种问题在人工智能计算中尤为明显,知存科技创始人兼CEO王绍迪近日在某论坛分享到:“这种数据搬运消耗的功耗超过95%以上,带宽也会达到80%以上,比如片上缓存,1MB的SRAM和8KB的SRAM在数据搬运上消耗的功耗相差10倍。”因此业界都在思考减少内存墙问题。
存算一体有效解决内存墙问题
存算一体主要有近存计算和存内计算。近存计算可以理解为通过先进封装拉近存储、内存和计算单元的距离,比如SRAM,在冯诺依曼架构中,很多时候SRAM用作缓存,多核共同使用,这样缓存到每个核都有一定距离,数据搬运、访问时间、功耗都会增加,王绍迪介绍:“近缓存计算把SRAM与计算单元合在一起,这个SRAM只供本地计算单元使用,数据访问时间和带宽都有很大提升。”
存内计算比近存计算更高效,同时也更难以实现,存内计算一般是使用存储的参数去完成计算,比如SRAM存内计算,Flash存内计算、以及RRAM存内计算。存内计算实际上是一个计算的模块,而不再是存储的模块,实践的方式是用存储的参数去完成运算,从存储器中读出的数据是运算的结果,而不是存储的数据。
在冯诺依曼架构中,不管是做加法运算还是乘法运算,都需要把数据从存储架构中读出来,包括缓存、内存、以及片外的存储,最终将数据读到计算单元中完成运算。从缓存中读取数据,要消耗运算几倍、几十倍、甚至几百倍的功耗,从内存读取数据,搬运功耗是运算的近千倍,从外部的存储读取,达到上万倍。
因此在数据量很大的计算中,冯诺依曼架构的效率就会非常低,而存内计算,存储器中存储了参数,被处理的数据作为输入信号,被处理的信号流过存储器中所有的参数,从存储器中输出的数据就是运算的结果。王绍迪表示,“存内计算的优势在于,能够将存储器中众多的存储单元转化为运算单元,这样能计算的并行度就会大幅提高,从原来几十、几百个并行,到存内计算几百万、几千万、甚至几亿个乘加法的并行度,运算效率很高。”
除了可以大规模并行运算,还可以很大程度节省数据带宽。简单来说,一个传统的存储器,多行多列,一次至多激活一行,读取出一行的数据,而要把多行数据读取出来,需要进行多个存储器周期,分别激活每一行,读出每一行的数据。而存内计算可以同时把输入数据给多行,同时多行的输入数据与每一行的参数做乘法运算,在列的方向直接把运算的结果读取出来,它是同时多行多列并行激活的方法。
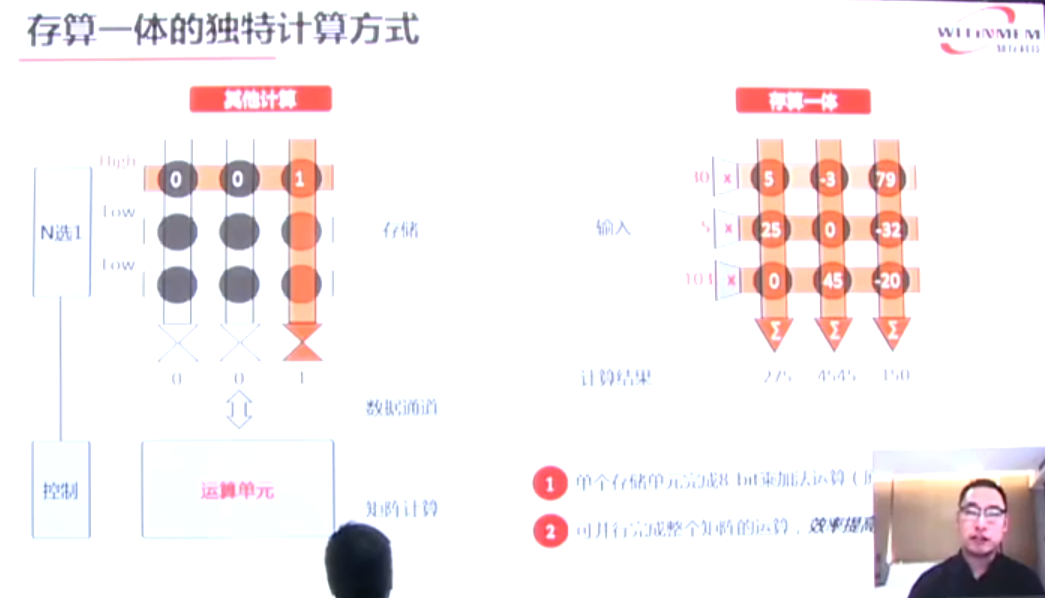
现在的存内计算可以做到千行千列同时开启,使用效率比传统存储器提高近千倍,王绍迪谈到:“整体来看,包括输入输出,存内计算运算效率一般会有几十倍的提升,而且提升倍数还一直在增加,存内计算的发展速度很快,最近处于早期的快速发展阶段,每年都有数倍性能的提升。”
知存科技WTM2101智能解决方案
知存科技目前在存内计算领域较为领先,公司成立于2017年底,目前已经推出两款存算一体芯片,其中WTM1001已经批量量产,WTM2101处于小批量阶段,知存科技目前已经完成五轮融资。
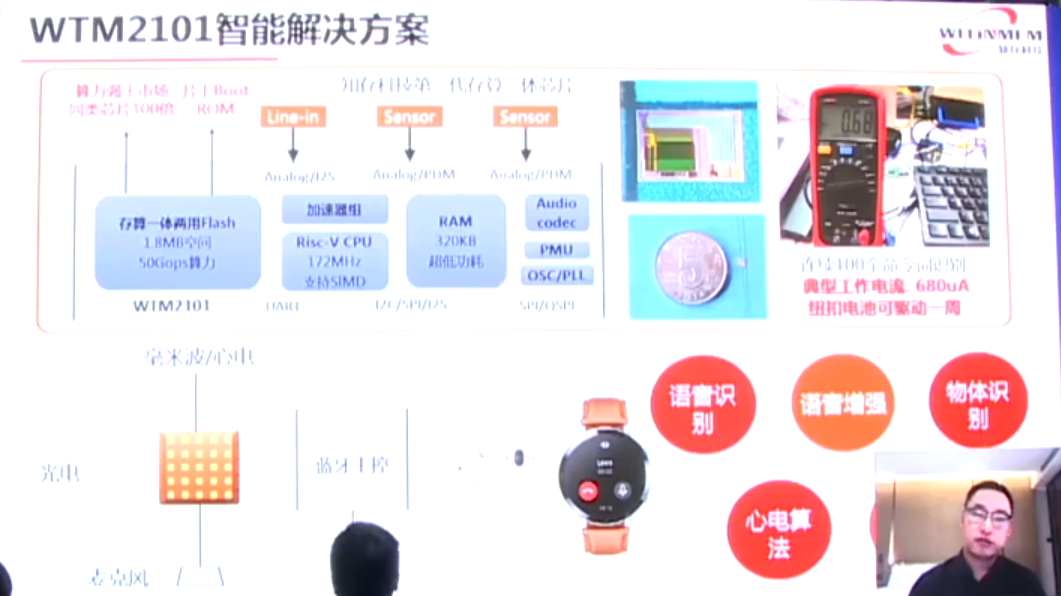
WTM2101是一款尺寸很小的SOC芯片,包括一个1.8MB存内计算的Flash,该存储模块除了用于存内计算,也可以用于普通的存储。王绍迪介绍:“这款芯片的封装很小,可以用在可穿戴设备中,目前计算的功耗非常低,比如如果做连续100个词到300个词的识别,功耗可以控制在1mA以内,其中100个词可以功耗可以到60微安。该芯片在运行语音识别、语音增强、物体识别、智能健康,以及其他的一些AI算法上,可以把算力和效率提升20倍到50倍。”
另外WTM2101首次用了独有的专利HPU,它是一个混合计算单元,实际上是把数字计算和模拟计算结合在一起,因为模拟计算有精度上限,为了提高精度,加了一个稀疏的计算单元,可以把存内计算的精度进一步提高,最高提高4比特。

存内计算未来的发展趋势
随着存内计算的发展,未来的应用场景也会越来越广,当前存内计算主要应用在端侧,一是受精度的限制,8比特,二是受容量,在几兆的级别,三是算力,基本在0.1T到1T的范围。
不过未来一两年将会发展到边侧,精度会提高到12比特,容量会达到16兆到64兆,算力也可以提升到最大32T,这样可以覆盖很多边缘侧的应用需求。未来还会向云端发展,存内计算精度会达到到16比特,容量会超过1000M,算力会达到256T到1024T。
存内计算在云侧、边侧、端侧,存内计算的优势各不相同,在端侧,存内计算在功耗的限制下可以提供大的算力,在边缘侧,在功耗、体积限制下也有很强的算力,在云端,可以提供更低成本的解决方案。
存内计算现在处于一个很快的发展阶段,未来几年,每年都会有很快的迭代速度。早期,产业界对存内计算的关注不多,投入也很少,最近存内计算逐渐得到越来越多的关注,王绍迪认为,未来五年存内计算都会在处在非常快速的发展阶段,在各种各样的场景中,进行规模化的落地应用。
-
存储
+关注
关注
13文章
4892浏览量
90290 -
内存
+关注
关注
9文章
3234浏览量
76518 -
AI
+关注
关注
91文章
41156浏览量
302622 -
人工智能
+关注
关注
1820文章
50335浏览量
266976 -
知存科技
+关注
关注
0文章
72浏览量
5571 -
存算一体
+关注
关注
1文章
121浏览量
5217
发布评论请先 登录
安克创新发布Thus™芯片:存算一体架构重塑AI音频新生态
中科曙光scaleX40超节点革新AI存算协同
算力革命下的隐形基石:存算一体时代呼唤更精准的“时间心跳”

AI存算一体,这家ReRAM新型存储受关注

知存科技王绍迪:AI可穿戴需求爆发,存算一体成主流AI芯片架构

载誉而归 | 苹芯科技斩获AABI火炬技术转移奖,存算一体技术探索跨境创新合作

存算一体AI芯片公司九天睿芯完成超亿元B轮融资
后摩尔定律时代,3D-CIM+RISC-V打造国产存算一体新范式

知存科技荣获2025半导体市场创新表现奖
在TR组件优化与存算一体架构中构建技术话语权

存算一体技术加持!后摩智能 160TOPS 端边大模型AI芯片正式发布

缓解高性能存算一体芯片IR-drop问题的软硬件协同设计
国际首创新突破!中国团队以存算一体排序架构攻克智能硬件加速难题

苹芯科技 N300 存算一体 NPU,开启端侧 AI 新征程



评论