 入门炫酷的Kubernetes网络方案
入门炫酷的Kubernetes网络方案

最近业界使用范围最广的K8S CNI网络方案 Calico 宣布支持 eBPF,而作为第一个通过 eBPF 实现了 kube-proxy 所有功能的 K8S 网络方案——Cilium,它的先见之名是否能转成优势,继而成为 CNI 新的头牌呢?今天我们一起来入门最 Cool Kubernetes 网络方案 Cilium。Cilium介绍
以下基于 Cilium官网文档翻译整理。
当前趋势
现代数据中心的应用系统已经逐渐转向基于微服务架构的开发体系,一个微服务架构的应用系统是由多个小的独立的服务组成,它们之间通过轻量通信协议如 HTTP、gRPC、Kafka 等进行通信。微服务架构下的服务天然具有动态变化的特点,结合容器化部署,时常会引起大规模的容器实例启动或重启。要确保这种向高度动态化的微服务应用之间的安全可达,既是挑战,也是机遇。现有问题
传统的 Linux 网络访问安全控制机制(如 iptables)是基于静态环境的IP地址和端口配置网络转发、过滤等规则,但是 IP 地址在微服务架构下是不断变化的,非固定的;出于安全目的,协议端口(例如 HTTP 传输的 TCP 端口 80)也不再固定用来区分应用系统。为了匹配大规模容器实例快速变化的生命周期,传统网络技术需要维护成千上万的负载均衡规则和访问控制规则,并且需要以不断增长的频率更新这些规则,而如果没有准确的可视化功能,要维护这些规则也是十分困难,这些对传统网络技术的可用性和性能都是极大的挑战。比如经常会有人对 kube-proxy 基于 iptables 的服务负载均衡功能在大规模容器场景下具有严重的性能瓶颈,同时由于容器的创建和销毁非常频繁,基于 IP 做身份关联的故障排除和安全审计等也很难实现。解决方案
Cilium 作为一款 Kubernetes CNI 插件,从一开始就是为大规模和高度动态的容器环境而设计,并且带来了 API 级别感知的网络安全管理功能,通过使用基于 Linux 内核特性的新技术——BPF,提供了基于 service/pod/container 作为标识,而非传统的 IP 地址,来定义和加强容器和 Pod 之间网络层、应用层的安全策略。因此,Cilium 不仅将安全控制与寻址解耦来简化在高度动态环境中应用安全性策略,而且提供传统网络第 3 层、4 层隔离功能,以及基于 http 层上隔离控制,来提供更强的安全性隔离。另外,由于 BPF 可以动态地插入控制 Linux 系统的程序,实现了强大的安全可视化功能,而且这些变化是不需要更新应用代码或重启应用服务本身就可以生效,因为 BPF 是运行在系统内核中的。以上这些特性,使 Cilium 能够在大规模容器环境中也具有高度可伸缩性、可视化以及安全性。部署 Cilium部署 Cilium 非常简单,可以通过单独的 yaml 文件部署全部组件(目前我使用了这个方式部署了1.7.1 版本),也可以通过 helm chart 一键完成。重要的是部署环境和时机:- 官方建议所有部署节点都使用 Linux 最新稳定内核版本,这样所有的功能都能启用,具体部署环境建议可以参照这里。
- 作为一个 Kubernetes 网络组件,它应该在部署 Kubernetes 其他基础组件之后,才进行部署。这里,我自己遇到的问题是,因为还没有 CNI 插件,coredns 组件的状态一直是 pending的,直到部署完 Cilium 后,coredns 完成了重置变成running状态。
>kubectlapply-fconnectivity-check.yaml NAMEREADYUP-TO-DATEAVAILABLEAGE echo-a1/11116d echo-b1/11116d host-to-b-multi-node-clusterip1/11116d host-to-b-multi-node-headless1/11116d pod-to-a1/11116d pod-to-a-allowed-cnp1/11116d pod-to-a-external-11111/11116d pod-to-a-l3-denied-cnp1/11116d pod-to-b-intra-node1/11116d pod-to-b-multi-node-clusterip1/11116d pod-to-b-multi-node-headless1/11116d pod-to-external-fqdn-allow-google-cnp1/11116d 如果所有的 deployment 都能成功运行起来,说明 Cilium 已经成功部署并工作正常。网络可视化神器 Hubble上文提到了 Cilium 强大之处就是提供了简单高效的网络可视化功能,它是通过 Hubble组件完成的。Cilium在1.7版本后推出并开源了Hubble,它是专门为网络可视化设计,能够利用 Cilium 提供的 eBPF 数据路径,获得对 Kubernetes 应用和服务的网络流量的深度可见性。这些网络流量信息可以对接 Hubble CLI、UI 工具,可以通过交互式的方式快速诊断如与 DNS 相关的问题。除了 Hubble 自身的监控工具,还可以对接主流的云原生监控体系—— Prometheus 和 Grafana,实现可扩展的监控策略。
部署 Hubble 和 Hubble UI
官方提供了基于 Helm Chart 部署方式,这样可以灵活控制部署变量,实现不同监控策略。出于想要试用 hubble UI 和对接 Grafana,我是这样的部署的:>helmtemplatehubble --namespacekube-system --setmetrics.enabled="{dns:query;ignoreAAAA;destinationContext=pod-short,drop:sourceContext=pod;destinationContext=pod,tcp,flow,port-distribution,icmp,http}" --setui.enabled=true >hubble.yaml >kubectlapply-fhubble.yaml #包含两个组件 #-daemonsethubble #-deploymenthubbleUI >kubectlgetpod-nkube-system|grephubble hubble-67ldp1/1Running021h hubble-f287p1/1Running021h hubble-fxzms1/1Running021h hubble-tlq641/1Running121h hubble-ui-5f9fc85849-hkzkr1/1Running015h hubble-vpxcb1/1Running021h
运行效果
由于默认的 Hubble UI 只提供了 ClusterIP 类似的 service,无法通过外部访问。因此需要创建一个 NodePort 类型的 service,如下所示:#hubble-ui-nodeport-svc.yaml kind:Service apiVersion:v1 metadata: namespace:kube-system name:hubble-ui-np spec: selector: k8s-app:hubble-ui ports: -name:http port:12000 nodePort:32321 type:NodePort执行
kubectl apply -f hubble-ui-nodeport-svc.yaml,就可以通过任意集群节点 IP 地址加上 32321 端口访问 Hubble UI 的 web 服务了。打开效果如下所示:
-
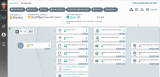
页面上半部分是之前部署的一整套 conectivity-check 组件的数据流向图,官方叫做
Service Map,默认情况下可以自动发现基于网络 3 层和 4 层的访问依赖路径,看上去非常 cool,也有点分布式链路追踪图的感觉。点击某个服务,还能看到更为详细的关系图:
- 下图是 kube-system 命名空间下的数据流图,能看到 Hubble-UI 组件和 Hubble 组件是通过gRPC 进行通信的,非常有趣。但令人感到的好奇的是,为何没有显示 Kubernetes 核心组件之间的调用关系图:
对接 Grafana + Prometheus
如果你跟一样是 Grafana+ Prometheus 的忠实粉丝,那么使 Hubble 对接它们就是必然操作了。仔细的同学已经发现之前 helm template 的玄机了:--setmetrics.enabled="{dns:query;ignoreAAAA;destinationContext=pod-short,drop:sourceContext=pod;destinationContext=pod,tcp,flow,port-distribution,icmp,http}" #上面的设置,表示开启了 hubble 的 metrics 输出模式,并输出以上这些信息。 #默认情况下,Hubble daemonset 会自动暴露 metrics API 给 Prometheus。 你可以对接现有的 Grafana+Prometheus 服务,也可以部署一个简单的:
#下面的命令会在命名空间cilium-monitoring下部署一个Grafana服务和Prometheus服务 $kubectlapply-fhttps://raw.githubusercontent.com/cilium/cilium/v1.6/examples/kubernetes/addons/prometheus/monitoring-example.yaml #创建对应NodePortService,方便外部访问web服务 $kubectlexposedeployment/grafana--type=NodePort--port=3000--name=gnp-ncilium-monitoring $kubectlexposedeployment/prometheus--type=NodePort--port=9090--name=pnp-ncilium-monitoring 完成部署后,打开 Grafana 网页,导入官方制作的 dashboard,可以快速创建基于 Hubble 的 metrics 监控。等待一段时间,就能在 Grafana 上看到数据了: Cilium 配合 Hubble,的确非常好用!取代 kube-proxy 组件Cilium 另外一个很大的宣传点是宣称已经全面实现kube-proxy的功能,包括
ClusterIP,NodePort,ExternalIPs和LoadBalancer,可以完全取代它的位置,同时提供更好的性能、可靠性以及可调试性。当然,这些都要归功于 eBPF 的能力。官方文档中提到,如果你是在先有 kube-proxy 后部署的 Cilium,那么他们是一个 “共存” 状态,Cilium 会根据节点操作系统的内核版本来决定是否还需要依赖 kube-proxy 实现某些功能,可以通过以下手段验证是否能停止 kube-proxy 组件:#检查Cilium对于取代kube-proxy的状态 >kubectlexec-it-nkube-system[Cilium-agent-pod]--ciliumstatus|grepKubeProxyReplacement #默认是Probe状态 #当Ciliumagent启动并运行,它将探测节点内核版本,判断BPF内核特性的可用性, #如果不满足,则通过依赖kube-proxy来补充剩余的Kubernetess, #并禁用BPF中的一部分功能 KubeProxyReplacement:Probe[NodePort(SNAT,30000-32767),ExternalIPs,HostReachableServices(TCP,UDP)] #查看Cilium保存的应用服务访问列表 #有了这些信息,就不需要kube-proxy进行中转了 >kubectlexec-it-nkube-system[Cilium-agent-pod]--ciliumservicelist IDFrontendServiceTypeBackend 110.96.0.10:53ClusterIP1=>100.64.0.98:53 2=>100.64.3.65:53 210.96.0.10:9153ClusterIP1=>100.64.0.98:9153 2=>100.64.3.65:9153 310.96.143.131:9090ClusterIP1=>100.64.4.100:9090 410.96.90.39:9090ClusterIP1=>100.64.4.100:9090 50.0.0.0:32447NodePort1=>100.64.4.100:9090 610.1.1.179:32447NodePort1=>100.64.4.100:9090 7100.64.0.74:32447NodePort1=>100.64.4.100:9090 810.96.190.1:80ClusterIP 910.96.201.51:80ClusterIP 1010.96.0.1:443ClusterIP1=>10.1.1.171:6443 2=>10.1.1.179:6443 3=>10.1.1.188:6443 1110.96.129.193:12000ClusterIP1=>100.64.4.221:12000 120.0.0.0:32321NodePort1=>100.64.4.221:12000 1310.1.1.179:32321NodePort1=>100.64.4.221:12000 14100.64.0.74:32321NodePort1=>100.64.4.221:12000 1510.96.0.30:3000ClusterIP 1610.96.156.253:3000ClusterIP 17100.64.0.74:31332NodePort 180.0.0.0:31332NodePort 1910.1.1.179:31332NodePort 2010.96.131.215:12000ClusterIP1=>100.64.4.221:12000 #查看iptables是否有kube-proxy维护的规则 >iptables-save|grepKUBE-SVC
责任编辑:haq
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
网络
+关注
关注
14文章
8336浏览量
95568 -
容器
+关注
关注
0文章
536浏览量
23029
原文标题:Kubernetes 网络方案——炫酷的 Cilium
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
Kubernetes Ingress Controller对比解析
Kubernetes集群对外提供服务时,Ingress是标准的服务暴露方式。Ingress资源定义了HTTP/HTTPS路由规则,而Ingress Controller则是这些规则的实现者
Kubernetes Pod异常问题排查实战
集群跑着跑着,Pod 挂了。Slack 告警一刷屏,脑子一片空白。打开终端敲 kubectl get pods,看到一堆 CrashLoopBackOff、ImagePullBackOff、Pending,不知道从哪下手。这是每个刚接触 Kubernetes 运维的人都会遇到的场景。
Trinamic方案加持,3D风扇屏如何实现稳定酷炫的显示效果?
效果。它有很多名字这类设备有很多叫法,比如:3D全息广告机全息风扇屏它的正式名称是3D全息智能炫屏。原理其实不复杂它的成像原理,简单来说,就是利用了人眼的“视觉暂留

KubePi:开源Kubernetes可视化管理面板,让集群管理如此简单
应用。解决方案 :部署KubePi作为统一的视觉化管理平台,让开发人员和有限的运维人员能够通过直观的界面轻松管理应用部署、监控集群状态,无需深入记忆复杂的Kubernetes命令。
5.2 教育培训环境
挑战
发表于 02-11 12:53
Kubernetes kubectl命令行工具详解
kubectl是Kubernetes官方提供的命令行工具,作为与Kubernetes集群交互的主要接口,它通过调用Kubernetes API Server实现对集群资源的全面管理。在生产环境中,运维工程师需要熟练掌握kubec
香港服务器支持Docker和Kubernetes吗?
和Kubernetes的部署与运行? 答案是肯定的,而且香港服务器由于其独特的优势,往往是部署容器化应用的绝佳选择。 下面,我们将从技术支持、网络优势、实践指南和注意事项等方面,全面解析香港服务器与云原生技术的完美契合度。 一、核心技术支持:坚如磐石的基
Kubernetes安全加固的核心技术
在生产环境中,Kubernetes集群的安全性直接关系到企业数据安全和业务稳定性。本文将从实战角度,带你掌握K8s安全加固的核心技术。
高效管理Kubernetes集群的实用技巧
作为一名经验丰富的运维工程师,我深知在日常的Kubernetes集群管理中,熟练掌握kubectl命令是提升工作效率的关键。今天,我将分享15个经过实战检验的kubectl实用技巧,帮助你像艺术家一样优雅地管理K8s集群。
基于eBPF的Kubernetes网络异常检测系统
作为一名在云原生领域深耕多年的运维工程师,我见过太多因为网络问题导致的生产事故。传统的监控手段往往是事后诸葛亮,当你发现问题时,用户已经在抱怨了。今天,我将分享如何利用 eBPF 这一革命性技术,构建一套能够实时检测 Kubernetes
生产环境中Kubernetes容器安全的最佳实践
随着容器化技术的快速发展,Kubernetes已成为企业级容器编排的首选平台。然而,在享受Kubernetes带来的便利性和可扩展性的同时,安全问题也日益凸显。本文将从运维工程师的角度,深入探讨生产环境中Kubernetes容器
树莓派部署 Kubernetes:通过 UDM Pro 实现 BGP 负载均衡!
最近,我将家庭实验室的架构核心切换为一组树莓派。尽管在树莓派上运行的Kubernetes发行版众多,但在资源受限的设备上运行Kubernetes时,控制平面的开销是一个常见挑战

Kubernetes Helm入门指南
Helm 是 Kubernetes 的包管理工具,它允许开发者和系统管理员通过定义、打包和部署应用程序来简化 Kubernetes 应用的管理工作。Helm 的出现是为了解决在 Kubernetes



评论