 浅谈GPU: 衡量计算效能的正确姿势(3)
浅谈GPU: 衡量计算效能的正确姿势(3)

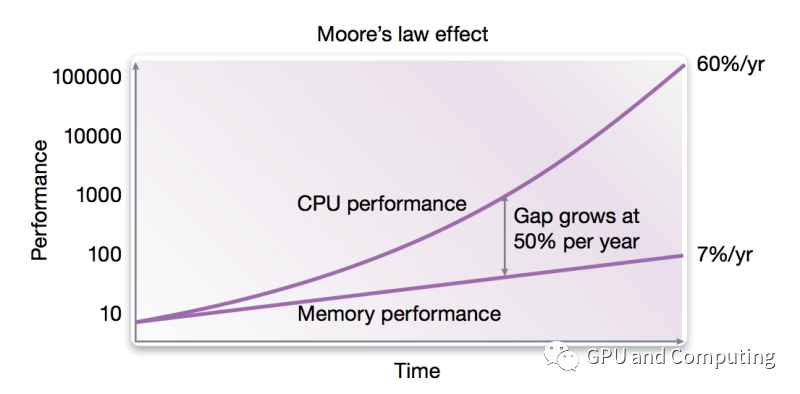
上期我们讲了现代计算机体系结构通过处理器(CPU/GPU)和内存的交互来执行计算程序,处理输入数据,并输出结果。实际上,由于CPU是高速器件,而内存访问速度往往受限(如图所示,CPU和内存的性能差距从上个世纪80年代开始,不断拉大),为解决速度匹配的问题,在CPU和内存之间设置了高速缓冲存储器Cache。
而且Cache往往分几个层级,与内存以及其它外部存储器共同构成计算机系统的存储器层次结构(Memory Hierarchy),如下图所示,使得整个系统在性能,成本和制造工艺达到平衡。
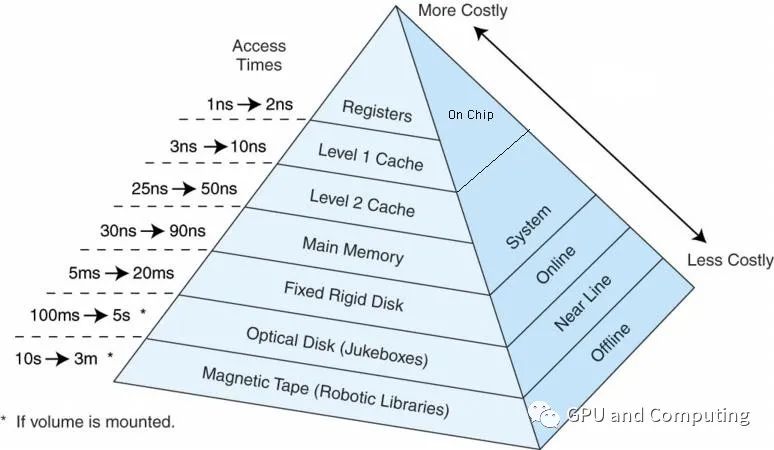
我们可以看到,各个存储层次在访问时间上存在数量级别的差异,访问速度越快,单位制造成本越高,容量越小。在这里,我们并不打算讨论Cache具体设计和实现,只是希望针对Cache及其命中率对性能的影响有一个直观的认识。为了简化讨论问题的复杂性,我们这里做如下假设。
整个流水线分为5个阶段,分别为《1》取指、《2》译码、《3》运算执行、《4》访存读写 (可选)、《5》写回结果至寄存器。
这里只考虑一级Cache,而且指令、数据共享L1 Cache。Cache命中的情况下,每个阶段都是1个时钟(cycle),而cache不命中的情况,阶段《1》,《5》各耗时100个时钟(cycles)。
访存指令占所有指令1/3。下面我们来分别计算3种情况下的CPI。
= 100 cycles + 3 * (1 cycle) + ((1 cycle * 2/3) + (100 cycles * 1/3))
= 137 cycles.
= (1 cycle * 0.9 + 100 cycles * (1 - 0.9)) + (3 cycles) + ((1 cycle * (2/3 + 0.9/3)) + (100cycles * (1 - 0.9) * 1/3))
= 18.2 cycles.
= (1 cycle * (0.99) + 100 cycles * (1 - 0.99)) + (3 cycles) + ((1 cycle * (2/3 + 0.99/3)) + (100 cycles * (1 - 0.99) * 1/3))
= 6.32 cycles.
Cache完全缺失。
CPI = 《1》阶段的时钟+《2, 3, 5》阶段的时钟+《4》阶段的时钟
Cache命中率达到90%。
CPI = 《1》阶段的时钟+《2, 3, 5》阶段的时钟+《4》阶段的时钟
Cache命中率达到99%
CPI = 《1》阶段的时钟+《2, 3, 5》阶段的时钟+《4》阶段的时钟另外在上期文章里我们也提到同样32b数据的访问,DRAM的耗能是SRAM的百倍(640pJ vs 5pJ)。完全可见正确配置Cache对高能效高性能计算的重要作用。
值得一提的是,由于CPU和GPU设计面向的差异,他们的Memory Hierarchy存在明显的区别,一个典型的对比如下图,可以看到GPU的Memeory Hierarchy设计的时候更注意带宽或者说Throughput,而相比之下对Latency就没有CPU重视, GPU Cache容量也相对比较小。
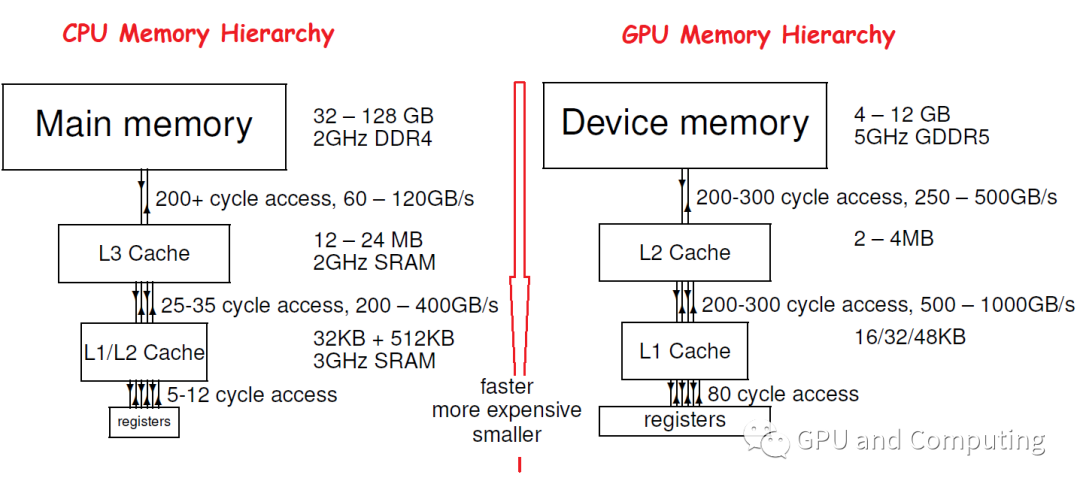
那我们不禁要问,GPU的Latency指标这么糟糕,按照我们先前的计算,Cache不命中的后果是不是很严重?不过不要担心,CPU的Cache不命中可能会导致叫停流水线的严重后果,而对GPU,只要计算任务量足够,它的硬件调度器(Hardware Scheduler)能够自动在不同的任务间无缝切换,来掩藏特定任务访问memory带来的延迟。关于GPU的Latency hiding,值得大书特书,我们以后会详细讨论。
编辑:lyn
-
cpu
+关注
关注
68文章
11327浏览量
225901 -
Cache
+关注
关注
0文章
130浏览量
29790
原文标题:GPU: 衡量计算效能的正确姿势(3)
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
成功案例:象帝先计算技术与Imagination合作——面向现代图形与计算工作负载的专业GPU

炎核开源开放平台上架推出OpenSparseBlas高性能稀疏计算库
汽车中的GPU是如何使用的?


绝缘子漏电起痕试验仪泄漏电流信号的小波变换分析及电弧能量计算


一步步教你正确的电磁流量计安装

别让 GPU 故障拖后腿,捷智算GPU维修室来救场!

如何选择合适的电池电量计
如何计算孔板流量计和平衡流量计的流量?计算公式一样吗?
GPU架构深度解析




评论