 Google科学家设计简化稀疏架构Switch Transformer,语言模型的参数量可扩展至 1.6 万亿
Google科学家设计简化稀疏架构Switch Transformer,语言模型的参数量可扩展至 1.6 万亿

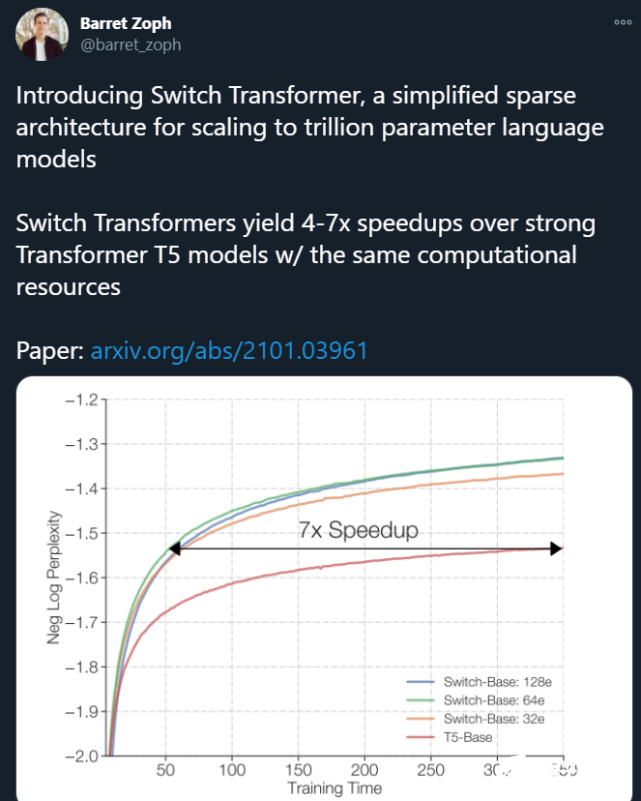
刚刚,Google Brain 高级研究科学家 Barret Zoph 发帖表示,他们设计了一个名叫「Switch Transformer」的简化稀疏架构,可以将语言模型的参数量扩展至 1.6 万亿(GPT-3 是 1750 亿)。在计算资源相同的情况下,Switch Transformer 的训练速度可以达到 T5 模型的 4-7 倍。
在深度学习领域,模型通常会对所有输入重用相同的参数。但 Mixture of Experts (MoE,混合专家) 模型是个例外,它们会为每个输入的例子选择不同的参数,结果得到一个稀疏激活模型——虽然参数量惊人,但计算成本恒定。
目前,MoE 模型已在机器翻译领域取得了令人瞩目的成就,但由于模型复杂度高、通信成本高、训练不够稳定,其广泛应用受到了一定的阻碍。
为了解决这些问题,Google Brain 的研究者提出了 Switch Transformer。在 Switch Transformer 的设计中,它们简化了 MoE 的路由算法(routing algorithm),设计了直观的改进模型,新模型的通信成本和计算成本都大大降低。此外,他们提出的训练技术还提高了训练的稳定性,首次表明大型稀疏模型也可以用低精度(bfloat16)进行训练。

论文链接:https://arxiv.org/pdf/2101.03961.pdf
代码链接:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
研究者还将新模型与 T5-Base 和 T5-Large 进行了对比,结果表明,在相同的计算资源下,新模型实现了最高 7 倍的预训练速度提升。这一改进还可以扩展至多语言设置中,在所有的 101 种语言中都测到了新模型相对于 mT5-Base 版本的性能提升。
最后,研究者在 Colossal Clean Crawled Corpus 上进行预训练,将语言模型的参数量提升至上万亿,且相比 T5-XXL 模型实现了 4 倍加速。
研究者还表示,虽然这项工作着眼于规模,但它也表明,Switch Transformer 架构不仅在具备超级计算机的环境下具有优势,在只有几个计算核心的计算机上也是有效的。此外,研究者设计的大型稀疏模型可以被蒸馏为一个小而稠密的版本,同时还能保留稀疏模型质量提升的 30%。
Switch Transformer 的设计原理
Switch Transformer 的主要设计原则是,以一种简单且计算高效的方式最大化 Transformer 模型的参数量。Kaplan 等人(2020)已经对扩展的效益进行了详尽的研究,揭示了随模型、数据集大小以及计算预算变化的幂定律缩放。重要的是,该研究提倡在相对较少数据上训练大型模型,将其作为计算最优方法。
基于这些,研究者在增加参数量的同时保持每个示例的 FLOP 不变。他们假设参数量与执行的总计算量无关,是可以单独缩放的重要组件。所以,研究者通过设计一个稀疏激活的模型来实现这一目标,该模型能够高效地利用 GPU 和 TPU 等为稠密矩阵乘法设计的硬件。
在分布式训练设置中,模型的稀疏激活层在不同设备上分配唯一的权重。所以,模型权重随设备数量的增加而增加,同时在每个设备上保持可管理的内存和计算空间。
Switch Transformer 的编码器块如下图 2 所示:
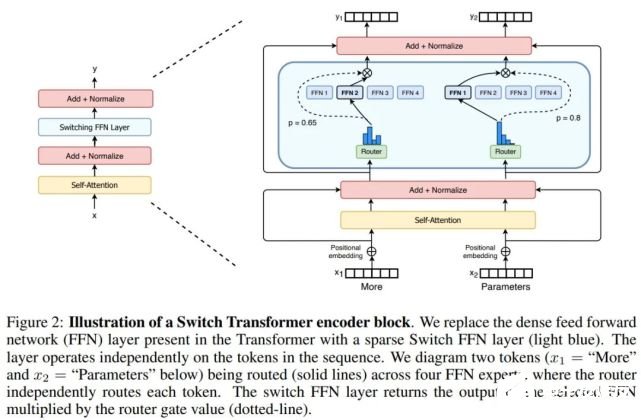
简化稀疏路由
Shazeer 等人(2017)提出了一个自然语言 MoE 层,它以 token 表征 x 为输入,然后将其发送给最坚定的 top-k 专家(从 N 个专家组成的 ^N_i=1 集合中选出)。他们假设将 token 表征发送给 k》1 个专家是必要的,这样可以使 routing 函数具备有意义的梯度。他们认为如果没有对比至少两个专家的能力,则无法学习路由。
与这些想法不同,谷歌大脑这项研究采用简化策略,只将 token 表征发送给单个专家。研究表明,这种简化策略保持了模型质量,降低了路由计算,并且性能更好。研究者将这种 k=1 的策略称为 Switch 层。
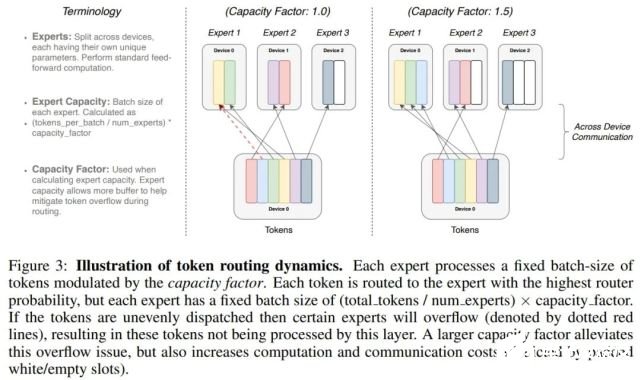
下图 3 展示了具有不同专家容量因子(expert capacity factor)的路由示例:
高效稀疏路由
研究者使用了 Mesh-Tensorflow 库 (MTF),它具有类似于 TensorFlow 的语义和 API,可促进高效分布式数据和模型并行架构。研究者在设计模型时考虑到了 TPU,它需要静态大小。
分布式 Switch Transformer 实现:所有张量形状在编译时均得到静态确定,但由于训练和推断过程中的路由决策,计算是动态的。鉴于此,一个重要的技术难题出现了:如何设置专家容量?
专家容量(每个专家计算的 token 数量)的计算方式为:每个批次的 token 数量除以专家数量,再乘以容量因子。如公式(3)所示:
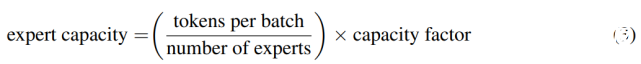
如果将太多 token 发送给一个专家(下文称为「丢弃的 token」),则会跳过计算,token 表征通过残差连接直接传递到下层。但增加专家容量也不是没有缺点,数值太高将导致计算和内存浪费。这当着的权衡如上图 3 所示。
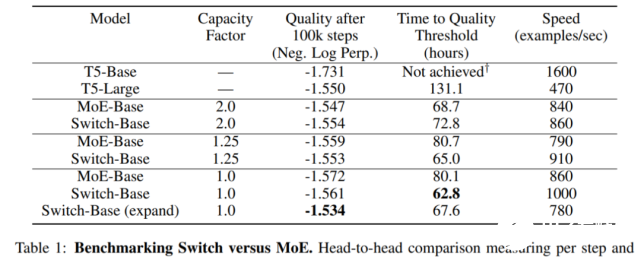
实证研究发现,将丢弃的 token 比例保持在较低水平对于稀疏专家模型的扩展很重要。设计决策对模型质量和速度的影响参见下表 1。
Switch Transformer
研究者首先在 Colossal Clean Crawled Corpus (C4) 数据集上对 Switch Transformer 进行了预训练测试,使用了掩蔽语言建模任务。在预训练设置中,他们遵循 Raffel 等人(2019)确定的最优方案,去掉了 15% 的 token,然后使用单个 sentinel token 来替代掩蔽序列。为了比较模型性能,研究者提供了负对数困惑度的结果。
Switch Transformer 与 MoE Transformer 的比较结果如下表 1 所示。结果表明,Switch Transformer 在速度 - 质量(speed-quality)基础上优于精心调整的稠密模型和 MoE Transformer,并在固定计算量和挂钟时间情况下取得了最佳结果;Switch Transformer 的计算占用空间比 MoE Transformer 小;Switch Transformer 在低容量因子(1.0, 1.25)下表现更好。
提升训练和微调的技巧
与原版 Transformer 模型相比,稀疏专家模型在训练时可能更加困难。所有这些层中的 hard-swithing(路由)决策都可能导致模型的不稳定。此外,像 bfloat16 这样的低精度格式可能加剧 router 的 softmax 计算问题。研究者采取了以下几种技巧来克服训练困难,并实现稳定和可扩展的训练。
对大型稀疏模型使用可选择行精度(Selective precision with large sparse models)
为实现稳定性使用更小的参数初始化(Smaller parameter initialization for stability)
正则化大型稀疏模型(Regularizing large sparse models)
预训练可扩展性
在预训练期间,研究者对 Switch Transformer 的可扩展性进行了研究。在此过程中,他们考虑了一个算力和数据都不受限制的机制。为了避免数据受限,研究者使用了大型 C4 数据库,里面包含 180B 的目标 token。在观察到收益递减之前,他们一直进行训练。
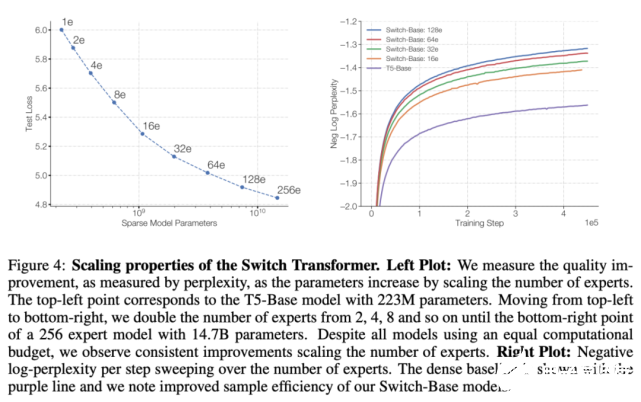
专家的数量是扩展模型最有效的维度。增加专家的数量几乎不会改变计算成本,因为模型只为每个 token 选择一个专家,这与专家的总体数量无关。router 必须基于更多的专家计算概率分布,但这是一个轻量级的计算成本 O(d_model × num experts)。其中,d_model 是层与层之间所传递的 token 的嵌入维度。在这一部分,研究者以固定的计算成本考虑基于步数和时间的可伸缩性。
基于步数的可扩展性
下图 4 展示了多个模型在训练步数恒定、专家数量增加时表现出的可扩展性提升情况。从中可以观察到一个趋势:在保持每个 token 的 FLOPS 不变时,拥有更多的参数(专家)可以提高训练速度。
基于时间的可扩展性
如上图 4 所示,随着专家数量的增加,模型的性能会不断提升。虽然模型的每个 token 拥有与基线近乎相同的 FLOPS,但 Switch Transformers 会产生额外的跨设备通信成本,路由机制也会带来额外的计算开销。因此,在基于步数的设置中观察到的样本效率提升未必能转化为时间上的模型质量提升。这就引出了一个问题:
在训练时间和计算成本都固定的前提下,我们应该训练一个稠密模型还是稀疏模型?
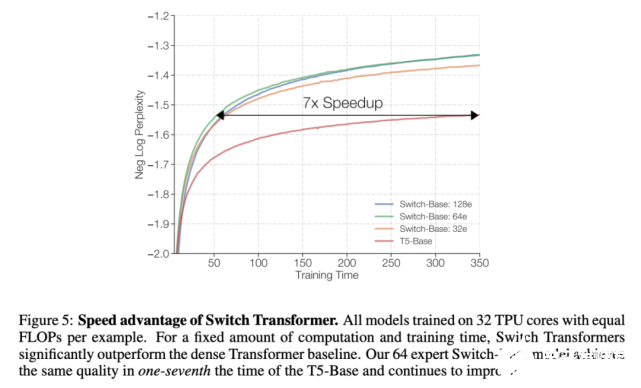
下图 5 和 6 解决了这个问题。图 5 展示了预训练模型质量随训练时间增加所产生的变化。在训练时间和计算成本都固定的情况下,Switch Transformer 的速度优势非常明显。在这种设置下,如果要达到相似的困惑度,Switch-Base 64 专家模型的训练时间仅为 T5-Base 模型的 1/7。
可扩展性 VS. 一个更大的稠密模型
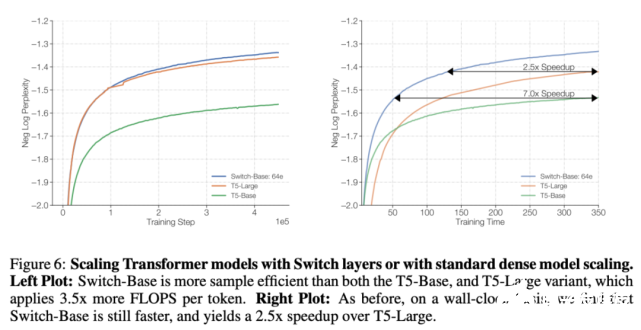
上面的实验表明,一个计算不受限制的稠密模型已经被 Switch 超越。图 6 考虑了一种不同的情况:如果把计算资源分给一个更大的稠密模型会怎么样?
为了验证这个问题,研究者将 Switch-Base 与更强的基线 T5-Large 进行了对比。实验结果表明,尽管 T5-Large 每个 token 所用的 FLOPs 是 Switch-Base 的 3.5 倍,但后者的样本效率依然更高,而且速度是前者的 2.5 倍。此外,如果设计一个与 T5-Large 所需 FLOPs 相同的 Switch 模型(Switch-Large),上述提升还会更加明显。
下游任务中的结果
微调
这里使用的基线方法是经过高度调参、具备 223M 参数的 T5-Base 和具备 739M 参数的 T5-Large 模型。针对这两个模型,该研究作者设计了具备更多参数的 FLOP-matched Switch Transformer。
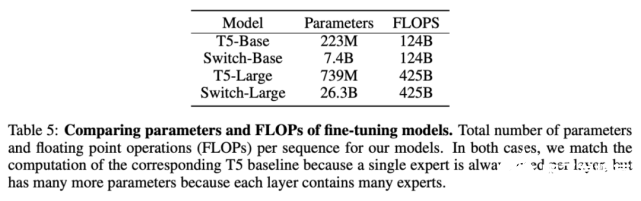
在多项自然语言任务中,Switch Transformer 带来了显著性能提升。最明显的是 SuperGLUE,在该基准上 FLOP-matched Switch Transformer 相比 T5-Base 和 T5-Large 的性能分别提升了 4.4% 和 2%,在 Winogrande、closed book Trivia QA 和 XSum 上也出现了类似情况。唯一没有观察到性能提升的基准是 AI2 推理挑战赛(ARC)数据集:在 ARC challenge 数据集上 T5-Base 的性能超过 Switch-Base;在 ARC easy 数据集上,T5-Large 的性能超过 Switch-Large。
整体而言,Switch Transformer 模型在多项推理和知识任务中带来了显著性能提升。这说明该模型架构不只对预训练有用,还可以通过微调将质量改进迁移至下游任务中。
蒸馏
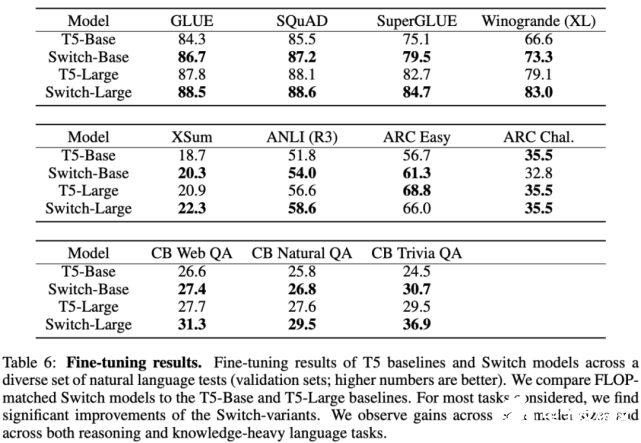
部署具备十亿、万亿参数量的大型神经网络并非易事。为此,该论文研究了如何将大型稀疏模型蒸馏为小型稠密模型。下表 7 展示了该研究所用的蒸馏技术:
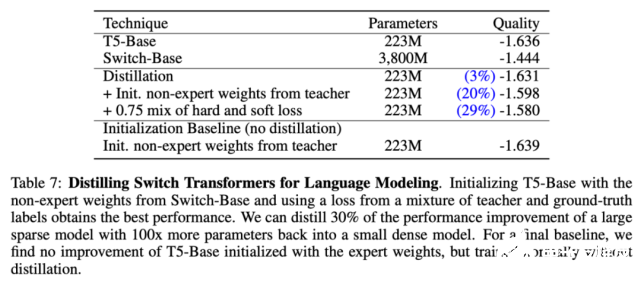
使用表 7 中最优的蒸馏技术后,研究者将多个稀疏模型蒸馏为稠密模型。他们对 Switch-Base 模型进行蒸馏,由于专家数量的不同,其参数量在 11 亿至 147 亿之间。该研究可以将具备 11 亿参数量的模型压缩 82%,同时保留 37% 的性能提升。最极端的情况下,将模型压缩了 99%,且维持了 28% 的性能提升。
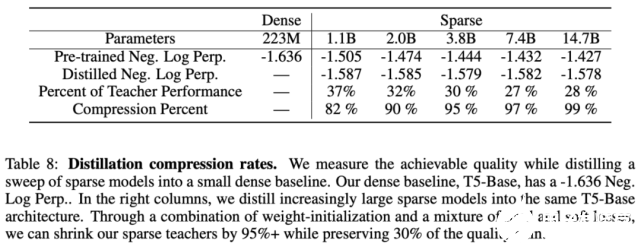
最后,研究者将微调稀疏模型蒸馏为稠密模型。下表 9 展示了对 74 亿参数 Switch-Base 模型(该模型针对 SuperGLUE 任务进行了微调)的蒸馏结果——223M T5-Base。与预训练结果类似,蒸馏后的模型仍保留 30% 的性能提升。这可能有助于确定用于微调任务的特定专家并进行提取,从而获得更好的模型压缩。

多语言学习
在下游任务实验中,研究者衡量了模型质量和速度的权衡,模型在 101 种不同语言上进行了预训练。下图 7 展示了 Switch T5 Base 模型与 mT5-Base 在所有语言上的质量提升情况(负对数困惑度)。对两个模型经过 100 万步预训练后,Switch Transformer 的最终负对数困惑度相较基线有所提升。
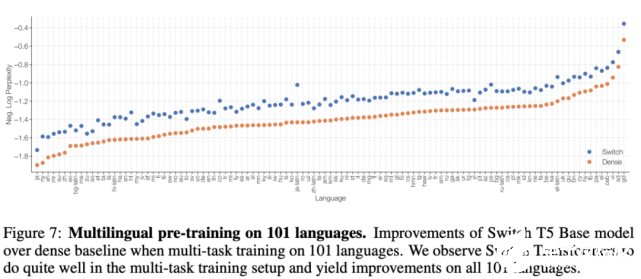
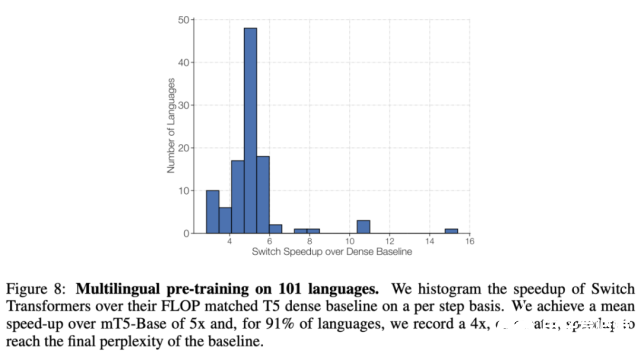
下图 8 展示了 Switch Transformer 相较 mT5-Base 的每一步加速情况,前者实现了平均 5 倍的加速,其中在 91% 的语言上实现了至少 4 倍加速。这表明 Switch Transformer 是高效的多任务和多语言学习器。
使用数据、模型和专家并行化来设计模型
随意地增加专家数量会出现收益递减问题(参见上图 4),该研究介绍了一些补充性的扩展策略,涉及结合数据、模型与专家并行化的权衡。
结合数据、模型与专家并行化,构建万亿参数模型
Switch Transformer 设计过程中,研究者试图平衡 FLOPs per token 和参数量。当专家数量增加时,则参数量增加,但不改变 FLOPs per token。要想增加 FLOPs,则需增加 d_ff 维度(这也会带来参数量的增加,但相对较少)。这就是一种权衡:增加 d_ff 维度会导致每个核心内存的耗尽,因而必须增加 m。但由于核心 N 的数量是固定的 N = n × m,因此必须降低 n,也就是说需要使用更小的批大小。

在结合模型并行化和专家并行化之后,发送 token 到正确的专家以及模型并行化导致的内部 all-reduce 通信会带来 all-to-all 通信成本。在结合这三种方法时,如何平衡 FLOPs、通信成本和每个核心的内存变得非常复杂。
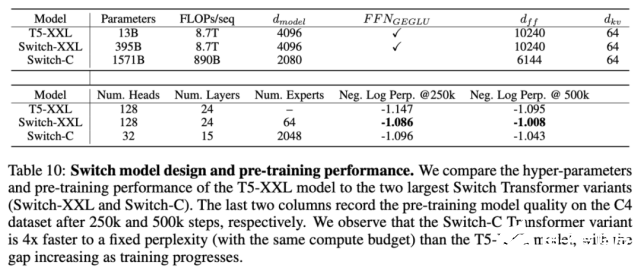
该研究结合数据、模型与专家并行化,设计了两个大型 Switch Transformer 模型,分别具备3950 亿参数和1.6 万亿参数,并研究了这些模型在上游预训练语言模型和下游微调任务中的性能。参数量、FLOPs 和不同模型的超参数参见下表 10:
关于 Switch Transformer 还有很多问题
在论文最后部分,谷歌大脑研究者探讨了一些关于 Switch Transformer 和稀疏专家模型的问题(这里稀疏指的是权重,而不是注意力模式)。
问题 1:Switch Transformer 的性能更好吗?原因是否在于巨量参数?
性能的确更好,但原因不在参数量,而在于设计。参数有助于扩展神经语言模型,大模型的性能确实会好一些。但是该研究提出的模型在使用相同计算资源的情况下具备更高的样本效率。
问题 2:没有超级计算机的情况下,我能使用该方法吗?
尽管这篇论文聚焦非常大型的模型,但研究者仍找到了具备两个专家的模型,既能提升性能又可以轻松适应常用 GPU 或 TPU 的内存限制。因此,研究者认为该技术可用于小规模设置中。
问题 3:在速度 - 准确率帕累托曲线上,稀疏模型的表现优于稠密模型吗?
是的。在多种不同模型规模情况下,稀疏模型在每一步和墙上时钟时间方面都优于稠密模型。受控实验表明,对于固定的计算量和时间而言,稀疏模型的表现超过稠密模型。
问题 4:我无法部署万亿参数模型,可以将模型缩小吗?
虽然无法完整维持万亿参数模型的质量,但通过将稀疏模型蒸馏为稠密模型,可实现 10-100 倍的压缩率,同时获得专家模型约 30% 的质量改进。
问题 5:为什么要使用 Switch Transformer 代替模型并行稠密模型?
以时间为基准,Switch Transformer 要比使用分片参数(sharded parameter)的稠密模型高效得多。同时,这一选择并非互斥,Switch Transformer 中也可以使用模型并行化,这可以提高 FLOPs per token,但也会导致传统模型并行化的减速。
问题 6:为什么稀疏模型未得到广泛使用?
尝试稀疏模型的想法被稠密模型的巨大成功所阻挠。并且,稀疏模型面临着多个问题,包括模型复杂度、训练难度、通信成本等。而 Switch Transformer 缓解了这些问题。
责任编辑:PSY
-
Google
+关注
关注
5文章
1817浏览量
60659 -
架构
+关注
关注
1文章
537浏览量
26650 -
语言模型
+关注
关注
0文章
575浏览量
11349
发布评论请先 登录
零基础手写大模型资料2026
Cadence 与 Google 合作,利用 ChipStack AI Super Agent 在 Google Cloud 上扩展 AI 驱动的芯片设计
Cadence与Google合作,利用ChipStack AI Super Agent在Google Cloud上扩展AI驱动的芯片设计
NVIDIA与Google探讨AI模型的演进方向
中兴通讯崔丽受邀出席2025腾冲科学家论坛
科学家利用微波激光照射钻石,制造出时间准晶体


国际类脑计算科学家Yulia Sandamirskaya教授加盟时识科技
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的科学应用
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
小白学大模型:国外主流大模型汇总

自动驾驶中Transformer大模型会取代深度学习吗?

浪潮信息发布"元脑SD200"超节点,面向万亿参数大模型创新设计

芯原超低能耗NPU可为移动端大语言模型推理提供超40 TOPS算力
Transformer架构概述




评论