 transformer模型详解:Transformer 模型的压缩方法
transformer模型详解:Transformer 模型的压缩方法

动机&背景
Transformer 模型在各种自然语言任务中取得了显著的成果,但内存和计算资源的瓶颈阻碍了其实用化部署。低秩近似和结构化剪枝是缓解这一瓶颈的主流方法。然而,作者通过分析发现,结构化剪枝在高稀疏率时往往不可避免地删除表达神经元,这将导致模型性能严重降低。低秩近似则旨在压缩表达神经元,它对于压缩神经元中的相干部分十分有效,其本质就是提取神经元共享相干子空间的公共基,该方法在 Transformer 结构上也遇到了困难,不同于 CNN,Transformer 模型的权重矩阵往往是满秩的,这导致低秩近似会破坏神经元的多样性,从而影响模型的表达能力。
为了解决结构化剪枝和低秩近似的局限性和困难,本文提出了一种新的模型压缩技术 LoSparse(Low-Rank and Sparse approximation),该技术通过低秩矩阵和稀疏矩阵的和来近似权重矩阵。这种复合近似将相干部分与神经元的非相干部分解耦。低秩近似压缩神经元中的连贯和表达部分,而修剪去除神经元中的不连贯和非表达部分。从这个意义上说,低秩近似可以防止剪枝过度去除表达神经元,而稀疏近似增强了低秩近似的多样性。
3. 方法:LoSparse
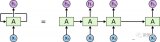
本文提出了一种 Transformer 模型的压缩方法——LoSparse。具体来说,LoSparse 通过低秩矩阵和稀疏矩阵的和来近似权重矩阵(如图 1 所示)。这两个近似的组合使得压缩方法更有效和稳定。
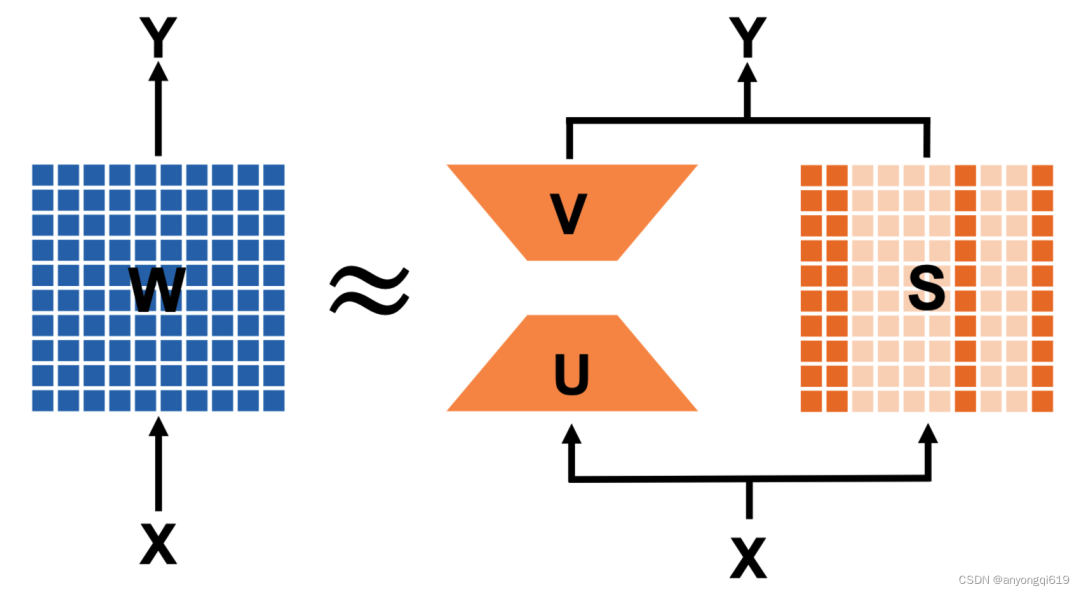 图 1. LoSparse 在单个线性投影矩阵的示意图(两部分并行进行前向传递)
图 1. LoSparse 在单个线性投影矩阵的示意图(两部分并行进行前向传递)
图 1. LoSparse 在单个线性投影矩阵的示意图(两部分并行进行前向传递)
3.1 低秩矩阵和稀疏矩阵的近似
给定一个权重矩阵 ,通常采用结构化剪枝稀疏矩阵 来近似 以进行压缩。然而,稀疏矩阵近似导致性能不佳,尤其是当压缩比率较高时。因此,本文引入了一个低秩矩阵来改进近似。具体来说,权重矩阵可以表示为:
其中 和 的乘积表示秩为 的低秩矩阵。
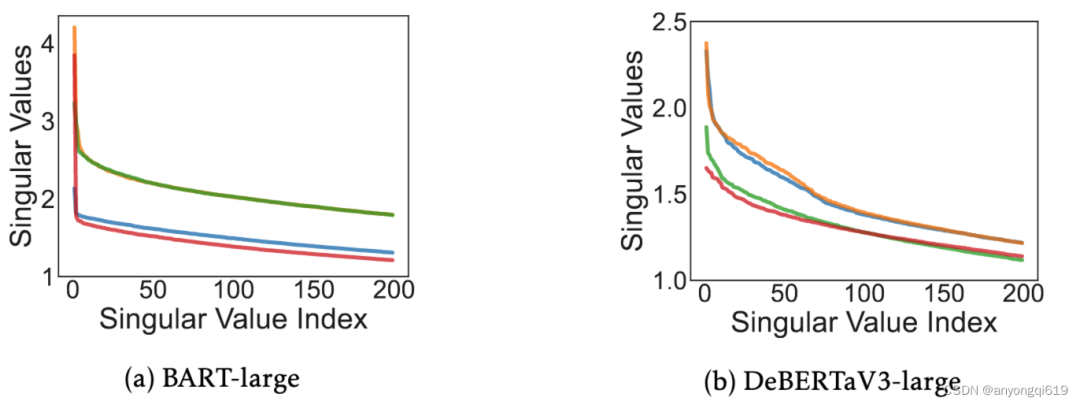 图 2. 语言模型的奇异值
图 2. 语言模型的奇异值
图 2. 语言模型的奇异值
为什么需要低秩矩阵?首先,它可以有效地逼近神经元的相干部分。如图 2 所示,我们可以看到语言模型中权重矩阵的频谱在开始时迅速下降。这表明权重矩阵中的神经元有一个共同的子空间,可以看作是这些神经元的连贯部分。此外,公共子空间可以通过顶部奇异值的奇异向量来恢复。其次,低秩矩阵和稀疏矩阵的解耦使得剪枝变得容易。图 2 中的尾谱表示每个神经元跨越它们的单个子空间,可以表示这些神经元的非相干部分。由于这些子空间不共享,因此低秩近似无法捕获非相干部分。幸运的是,低秩矩阵能够将相干部分与神经元的非相干部分解耦。这使我们能够通过添加一个新的矩阵 来近似剩余的不连贯部分,然后修剪非表达不连贯的部分。图 3 表明,大多数不连贯的部分在解耦后具有较低的重要性分数,这有助于剪枝删除这些冗余参数。
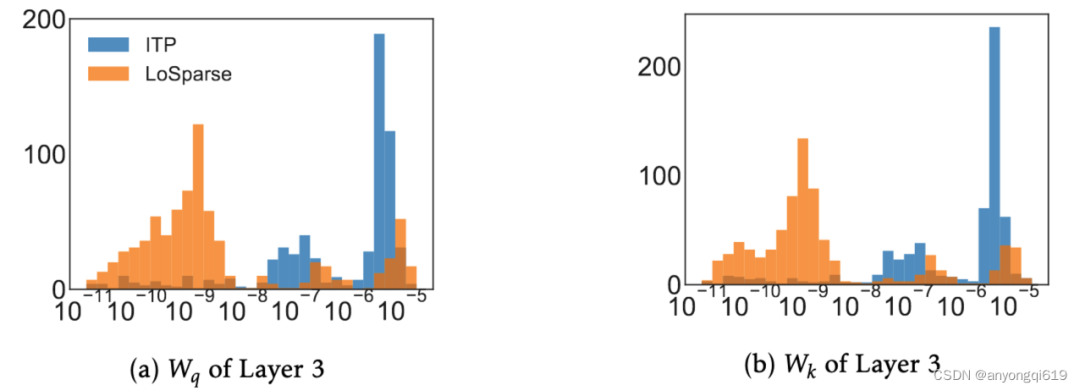 图3. 线性投影的神经元的重要性得分分布情况(ITP vs LoSparse)
图3. 线性投影的神经元的重要性得分分布情况(ITP vs LoSparse)
图3. 线性投影的神经元的重要性得分分布情况(ITP vs LoSparse)
3.2 算法
给定一个预训练的权重矩阵 ,我们首先基于 的奇异值分解(SVD)初始化秩 的低秩矩阵。具体来说,本文选择:
在此基础上,我们可以初始化 为:
原始的前向传递()可替换为更高效的形式:
LoSparse 对模型的每个权重矩阵应用这样的分解,并将 表示为所有稀疏矩阵的集合。初始化后,本文对 进行迭代结构化剪枝。具体来说,在第 次迭代时,我们首先采用随机梯度下降更新 、 和 。重要性得分和迭代更新策略均采用标准设置(一阶泰勒评估重要性+三次时间表的迭代衰减策略)。具体算法见算法 1。
 Untitled
Untitled
4. 实验
自然语言理解:表 1 和 表 2 分别展示了 DeBERTaV3-base 和 BERT-base 模型上各个压缩方法在 GLUE 上的表现。LoSparse 表现出了远超其他方法的性能,与此同时,它还比其他方法更稳定,这是因为 LoSparse 方法中每个权重矩阵至少有一个低秩矩阵来保证连贯和表达神经元信息的不过分丢失。
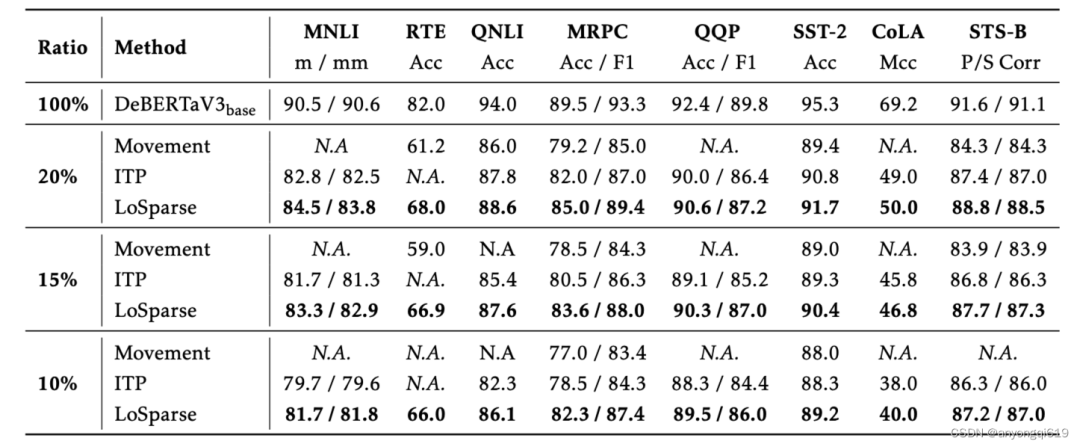 表 1. GLUE 验证集上 DeBERTaV3-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
表 1. GLUE 验证集上 DeBERTaV3-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
表 1. GLUE 验证集上 DeBERTaV3-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
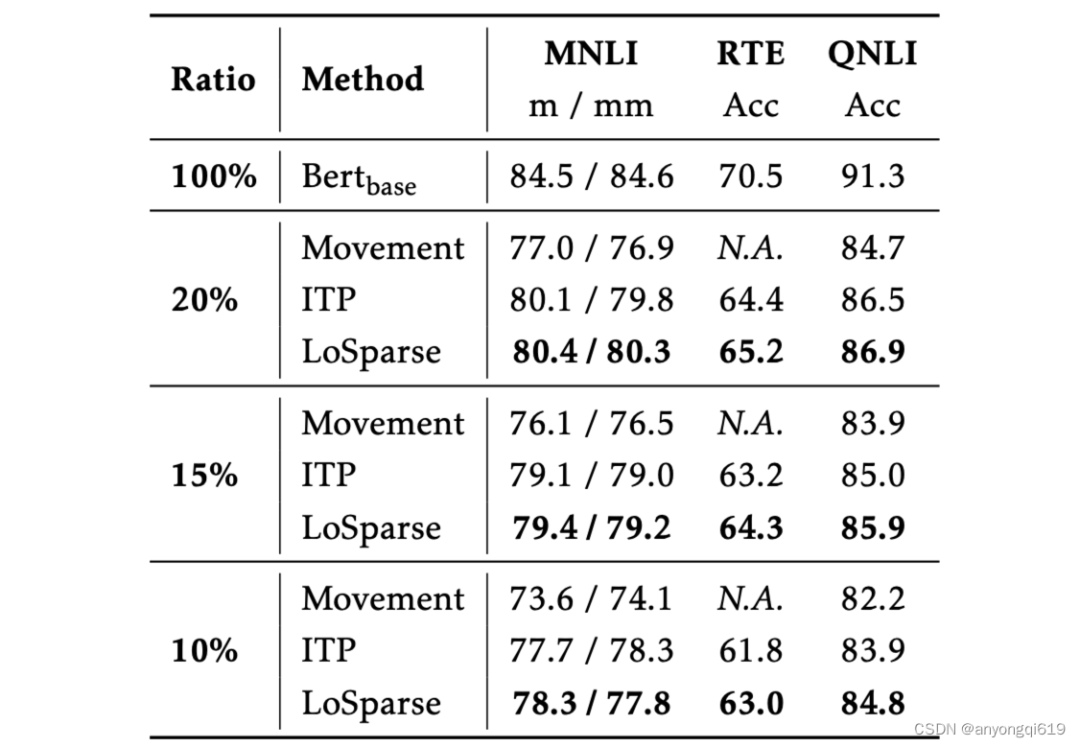 表 2. GLUE 验证集上 BERT-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
表 2. GLUE 验证集上 BERT-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
表 2. GLUE 验证集上 BERT-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
问答任务:表 3 对比了 LoSparse 方法在 SQuAD v1.1 上的表现。在所有压缩比率下,LoSparse 都优于其他压缩方法,尤其是在更高压缩比的情况下。
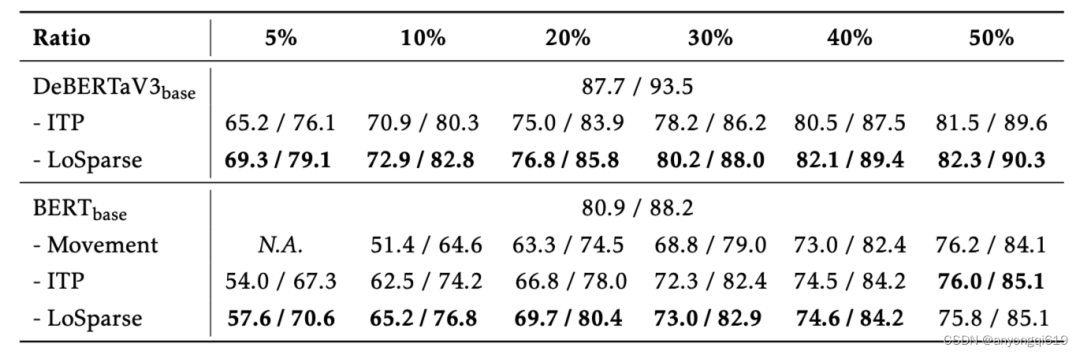 表 3. SQuAD v1.1 上 DeBERTaV3-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
表 3. SQuAD v1.1 上 DeBERTaV3-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
表 3. SQuAD v1.1 上 DeBERTaV3-base 的压缩结果(Ratio 表示剩余权重比例,N.A.表示模型不收敛,最佳结果以粗体显示)
自然语言生成:表 4 说明在自然语言生成任务上,LoSparse 仍然表现优异,在各个压缩比下优于现有方法。值得注意的是,LoSparse 在更困难的摘要任务上表现更好。
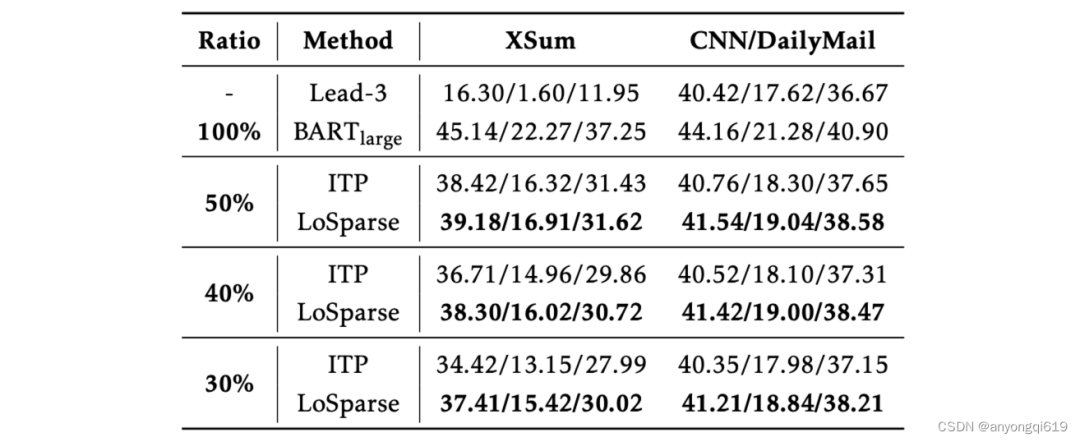 表 4. XSum 上 BART-Large 的压缩结果(Ratio表示剩余权重比例,最佳结果以粗体显示)
表 4. XSum 上 BART-Large 的压缩结果(Ratio表示剩余权重比例,最佳结果以粗体显示)
表 4. XSum 上 BART-Large 的压缩结果(Ratio表示剩余权重比例,最佳结果以粗体显示)
消融实验:论文分析了稀疏近似的有效性和稀疏分配的影响(低秩矩阵和稀疏矩阵的权重占比),实验表明本文提出的稀疏近似对于性能有很大正贡献,且 LoSparse 对稀疏分配策略相对鲁棒,具体细节可见原文。
-
模型
+关注
关注
1文章
3879浏览量
52355 -
神经元
+关注
关注
1文章
369浏览量
19222 -
Transformer
+关注
关注
0文章
156浏览量
6981
原文标题:标题:ICML 2023 | LoSparse:低秩近似和结构化剪枝的有机组合
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文详解Transformer神经网络模型

如何使用MATLAB构建Transformer模型

大语言模型背后的Transformer,与CNN和RNN有何不同

【大语言模型:原理与工程实践】大语言模型的基础技术
你了解在单GPU上就可以运行的Transformer模型吗
Transformer模型的多模态学习应用
使用跨界模型Transformer来做物体检测!

Microsoft使用NVIDIA Triton加速AI Transformer模型应用
Transformer结构及其应用详解
基于Transformer的大型语言模型(LLM)的内部机制

基于 Transformer 的分割与检测方法

基于Transformer模型的压缩方法





评论