 NLP:序列标注
NLP:序列标注

0 小系列初衷
自己接触的项目大都是初创,没开始多久的项目,从0到1的不少,2020年快结束,感觉这个具有一定个人特色的技术经验可以在和大家分享一下。
计划篇章:
(已完成)文本分类篇。针对NLP文本分类任务。
序列标注(NER)篇。针对命名实体识别、序列标注任务。
文本匹配篇。针对语义相似度计算、向量匹配等问题。
人工特征学习篇。针对多特征的机器、深度学习方案。
1 序列标注的场景
文本分类是对整个句子的把握,而NER就是深入到句子内部,对句子的局部进行深入分析,这个粒度的分析往往更为精准详尽,当然难度也会更高,下面列举几个比较常见的场景:
搜索、对话的实体、关系抽取。
搜索的关键词抽取,词权重问题。
纠错的错误检测。
总而言之,只要是抽取局部信息,那其实就可以抽象为序列标注了。
严谨起见,来个专业点的定义吧:
给定一个序列(含特征),预测一组和序列一一对应的结果,这种预测就是序列标注。
2 方案选型——通用方法
之所以把序列标注放一起,是因为问题类似,既然问题类似,那其实就可以找到通式通法来解决,所以先给大家说一些比较通用的方法。大家也把序列标注问题带入来分析计算,其实很多的解法很类似。
2.1 非模型操作
常见的两个非模型操作,直接通过规则或者词典的模式:
通过配置句式,用正则表达式的方式来抽取。
运用词典,用最大逆向匹配来完成。之前写过文章:NLP.TM[29] | ner自动化打标方法
当然了这种非模型操作的优缺点点也是很明显,之前也聊过不少了:
优点:
高准确。
方便快捷。
缺点:
召回低,泛化能力弱。
2.2 模型操作
模型往往是泛化能力较强的,规则和模板无法满足召回的情况下,我们就需要模型来处理了。序列标注需要对序列依赖要求很高,所以比较推荐大家用抽取序列特征的模型来处理。
HMM、CRF。序列标注的经典操作,有关CRF,我之前还写过长文讨论过:NLP.TM[19] | 条件随机场知识整理(超长文!)。
BiLSTM-CRF,之前也提到过,能上深度的情况下,这个的基线效果还是比较强的。NLP.TM | 命名实体识别基线 BiLSTM+CRF(上),NLP.TM | 命名实体识别基线 BiLSTM+CRF(下)
Bert-CRF。超级大的模型,整体效果是还不错的。
和上次一样,也是介绍3个,只要数据质量足够好,准招七八十是没什么大问题的,如果效果不好,往往是因为数据之类的原因导致的,此时我们该做的就是精炼数据集,只有足够数量和质量的数据,模型的效果才会好。
而相比文本分类任务,NER的样本往往更加难得,但是小样本还是可以通过人工标注、挖掘等方式获取,然后通过数据增强的方式来拓展出更多有代表性的query。
当然了,序列标注是一个很广义的问题,有一些特异的任务需要有特异的方法。
2.3 关键词抽取
有关关键词抽取,其实我在原来的文章就讲过,文章在这里:NLP.TM[20] | 词权重问题,这里可以考虑这几个方案:
预训练的IDF词典,例如jieba的。
很多关键词抽取的任务都有场景特色,jieba那种通用的不适合,根据自己的数据自己训一个,可能是最简单的,自己手写也不太累的模型训练了。
如果数据和特征够多,学美团的方案(前沿重器[2] | 美团搜索理解和召回)自己训一个机器学习模型或者用深度学习整一个关键词抽取的序列标注模型。
2.4 纠错的错误检测
在现在比较前沿的技术里,纠错其实已经是一整个完整的模块,被拆分为错误检测、候选召回、召回排序三步,其中的错误检测就是为了找到句子中可能出错的部分,这里其实就可以抽象为序列标注问题,当然用模型的方式来处理肯定是可以的,不过这同样需要大量的标注数据才能解决,相比之下,获取一批正常的语料还是很简单的,这些预料可以训练语言模型,通过语言模型来判断句子中是否存在通顺程度异常的位点,这块详情大家可以看看我之前的文章,尤其是第一篇。
NLP.TM[33] | 纠错:pycorrector的错误检测
NLP.TM[34] | 纠错:pycorrector的候选召回
NLP.TM[35] | 纠错:pycorrector的候选排序
NLP.TM[37] | 深入讨论纠错系统
3 效果调优
有关效果调优,上面其实多多少少聊了很多,这里简单总结一下吧。
无监督方案还是要多用,毕竟有监督方法需要足量,无论是数量还是质量,的数据。
如果实在需要有监督模型,但受限于数据,可以通过数据增强的方式挖掘到一批质量还行的数据。NLP.TM[32] | 浅谈文本增强技术
从关键词抽取和纠错的错误检测中其实可以看到,解决序列标注的思路还是很丰富的,大家要注意多积累。
4 其他想说的
在这次总结里,一方面是仍然强烈感受到对方案和数据把控的重要性,尤其在序列标注这个问题下,足量的标注数据是模型使用的先决条件,因此对数据的管理和优化非常重要。另外,序列标注需要对句子中的每个字/词都要标注,这个标注数据是真的不好拿,因此需要我们对无监督、非模型的方法也有足够的了解,如果排期足够,这种无监督非模型的方案是可以作为有监督模型数据的标注的,没有时间,无监督非模型的方法也可以作为基线直接上线,这个也很好。最后一点事,我感觉我对前沿方案的把控还需要提升,这一轮输出完成后,我可能要开始对前沿方案重新调研升级,从而升级自己的武器库。
责任编辑:xj
原文标题:任务方案思考:序列标注(NER)篇
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
序列
+关注
关注
0文章
70浏览量
20289 -
自然语言处理
+关注
关注
1文章
630浏览量
14767 -
nlp
+关注
关注
1文章
491浏览量
23387
原文标题:任务方案思考:序列标注(NER)篇
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
特斯拉百万年薪招人!数据标注行业迎来第二春?

通过DSC实现VI与TestStand序列交互

自动驾驶占用网络还需要数据标注吗?

大模型时代自动驾驶标注有什么特殊要求?

JSON:简洁代码高效搞定序列化与反序列化

极简代码,搞定JSON序列化与反序列化

自动驾驶数据标注是所有信息都要标注吗?

算法工程师不愿做标注工作,怎么办?

浅析多模态标注对大模型应用落地的重要性与标注实例
小语种OCR标注效率提升10+倍:PaddleOCR+ERNIE 4.5自动标注实战解析
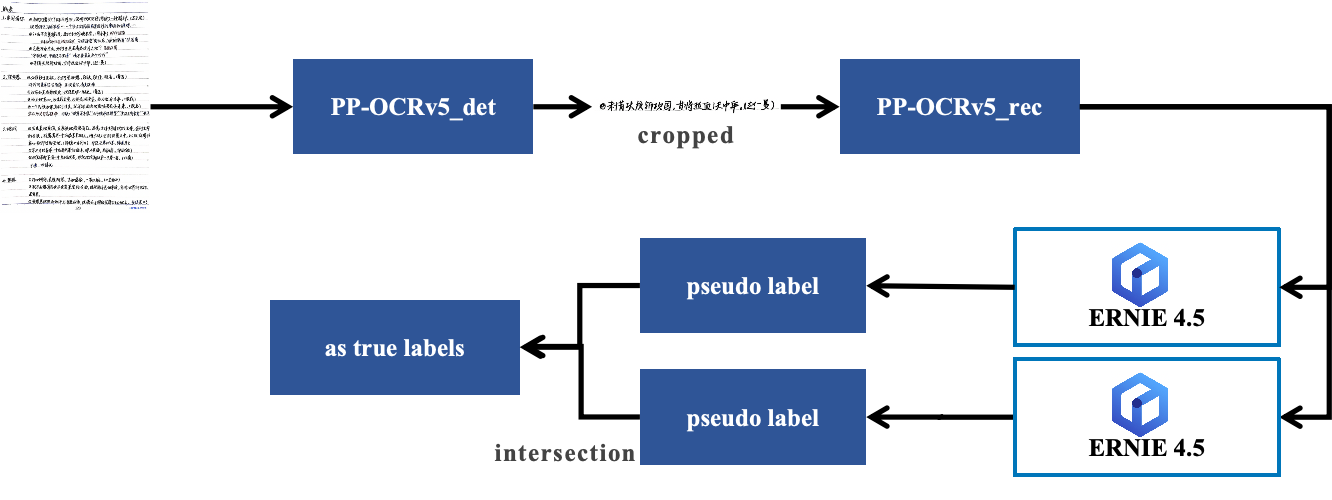
请问AICube所需的目标检测数据集标注可以使用什么工具?
自动驾驶数据标注主要是标注什么?
什么是自动驾驶数据标注?如何好做数据标注?
端到端数据标注方案在自动驾驶领域的应用优势
数据标注与大模型的双向赋能:效率与性能的跃升



评论