 多模态中NLP与CV融合的方式有哪些?
多模态中NLP与CV融合的方式有哪些?

最早接触多模态是一个抖音推荐项目,有一些视频,标题,用户点赞收藏等信息,给用户推荐作品,我当时在这个项目里负责用NLP部分上分,虽然最后用wide and deep 整个团队效果还可以,但是从a/b test 看文本部分在其中起到的作用为0... ( ) 现在看来还是wide and deep这种方式太粗暴了(对于复杂信息的融合),本文写写多模态扫盲基础和最近大家精巧的一些图像文本融合的模型设计,主要是在VQA(视觉问答)领域,也有一个多模态QA,因为在推荐领域,你也看到了,即使NLP的贡献为零,用户特征足够,效果也能做到很好了。
一. 概念扫盲
多模态(MultiModal)
多种不同的信息源(不同的信息形式)中获取信息表达
五个挑战
表示(Multimodal Representation)的意思,比如shift旋转尺寸不变形,图像中研究出的一种表示
表示的冗余问题
不同的信号,有的象征性信号,有波信号,什么样的表示方式方便多模态模型提取信息
表示的方法
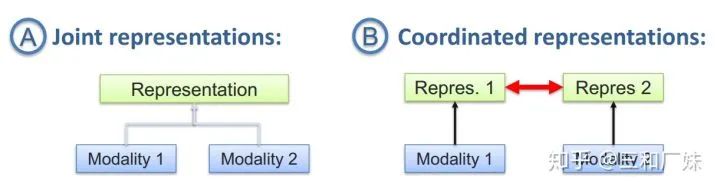
联合表示将多个模态的信息一起映射到一个统一的多模态向量空间
协同表示负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束。
2. 翻译/转化/映射
信号的映射,比如给一个图像,将图像翻译成文字,文字翻译成图像,信息转化成统一形式后来应用
方式,这里就跟专门研究翻译的领域是重叠,基于实例的翻译,涉及到检索,字典(规则)等,基于生成方法如生成翻译的内容
3. 对齐
多模态对齐定义为从两个或多个模态中查找实例子组件之间的关系和对应,研究不同的信号如何对齐(比如给电影,找出剧本中哪一段)
对齐方式,有专门研究对齐的领域,主要两种,显示对齐(比如时间维度上就是显示对齐的),隐式对齐(比如语言的翻译就不是位置对位置)
4. 融合
比如情感分析中语气和语句的融合等
这个最难也是被研究最多的领域,比如音节和唇语头像怎么融合,本笔记主要写融合方式
二. 应用
试听语音识别,多媒体内容检索,视频理解,视频总结,事件监测,情感分析,视频会议情感分析,媒体描述,视觉问答等,应用其实很广,只不过被现在的智能程度大大限制了,whatever, 我觉得视觉也语言的结合比纯NLP,是离智能更近的一步。
三.VQA扫盲 and 常用方式
VQA(Visual Question Answering)
给定一张图片(视频)和一个与该图片相关的自然语言问题,计算机能产生一个正确的回答。这是文本QA和Image Captioning的结合,一般会涉及到图像内容上的推理,看起来更炫酷(不是指逻辑,就就指直观感受)。
目前VQA的四大方式
Joint embedding approaches,只是直接从源头编码的角度开始融合信息,这也很自然的联想到最简单粗暴的方式就是把文本和图像的embedding直接拼接(ps:粗暴拼接这种方式很work),Billiner Fusion 最常用了,Fusion届的LR
Attention mechanisms,很多VQA的问题都在attention上做文章,attention本身也是一个提取信息的动作,自从attention is all you need后,大家对attention的应用可以说是花式了,本文后面专门介绍CVPR2019的几篇
Compositional Models,这种方式解决问题的思路是分模块而治之,各模块分别处理不同的功能,然后通过模块的组装推理得出结果
比如在[1]中,上图,问题是What color is his tie?先选择出 attend 和classify 模块,并且根据推理方式组装模块,最后得出结论 4.Models using external knowledge base利用外部知识库来做VQA和很好理解,QA都喜欢用知识库,这种知识储备一劳永逸,例如,为了回答“图上有多少只哺乳动物”这样的问题,模型必须得知道“哺乳动物”的定义,而你想从图像上去学习到哺乳动物是有难度的,因此把知识库接进来检索是种解决方式,例如在[2]
四. 多模态中CV和NLP融合的几种方式
1. Bilinear Fusion 双线性融合 and Joint embedding Bilinear Fusion 双线性融合是最常见的一种融合方式了,很多论文用这种方式做基础结构,在CVPR2019一遍VQA多模态推理[3]中,提出的CELL就是基于这个,作者做关系推理,不仅对问题与图片区域的交互关系建模,也对图片区域间的联系建模。并且推导过程是逐步逼近的过程。
作者提出的MuRel,Bilinear Fusion 将每个图像区域特征都分别与问题文本特征融合得到多模态embedding(Joint embedding ),后者对这些embedding进行成对的关系建模。
第一部分双线性融合,所谓双线性简单来讲就是函数对于两个变量都是线性的,参数(表达两种信息关联)是个多为矩阵,作者采用的MUTAN模型里面的Tucker decomposition方法, 将线性关系的参数分解大大减小参数量 第二部分Pairwise relation学习的是经过融合后节点之间的两两关系(主要是图像的关系),然后和原始text 信息有效(粗暴)拼接 最后如下图放在网络,进行迭代推理。实验结果显示在跟位置推断类的问题中,这种结构表现比较好。
2. 花式动态attention融合 这篇[4]作者更上篇一样同时注意到了模态内和模态间的关系,即作者说的intra-modality relation(模态内部关系)和inter-modality relation(跨模态关系),但是作者更机智(个人观点)的用了attention来做各种fusion。 作者认为intra-modality relation是对inter-modality relation的补充:图像区域不应该仅获得来自问题文本的信息,而且需要与其他图像区域产生关联。 模型结构是首先各自分别对图像和文本提取特征,然后通过通过模态内部的attention建模和模态间的attention建模,这个模块堆叠多次,最后拼接后进行分类。模态间的attention是相互的(文本对图像,图像对文本),attention就是采用transform中的attention.
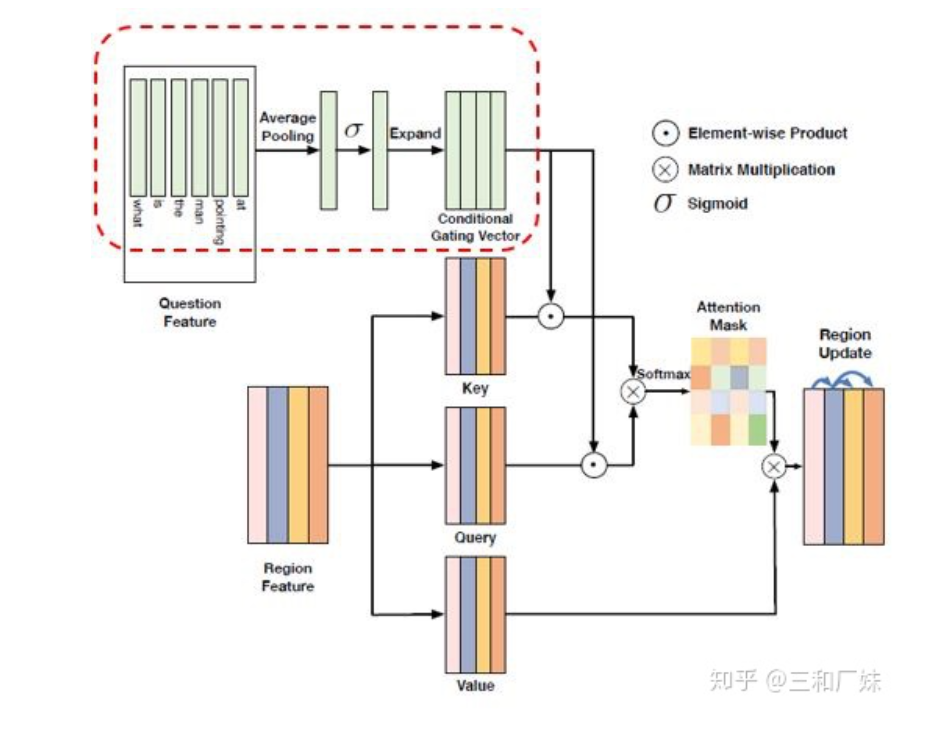
进行模态内关系建模的模块是Dynamic Intra-modality Attention Flow (DyIntraMAF), 文中最大的亮点是进行了 条件attention,即图像之间的attention信心建立不应该只根据图像,也要根据不同的具体问题而产生不同的关联。
这种条件attention的condition设计有点类似lstm的门机制,通过加入gating机制来控制信息,下图中图像的self attention 就是经过了text的门机制来过滤信息。最后作者做了很多ablation studies,达到了SOTA效果。
3. VQA对话系统 另外有一篇[5]个多模态的QA,这篇文章fusion 挺普通的multimodal fusion 也是普通的 billinear, 但是这个应用场景非常非常实用,我们通常用语言描述的说不清楚的时候,会有一图胜千言语感觉,而多模态就是从这个点出发,发一张图,like this, like that... 文中就是用这个做商业客服的QA
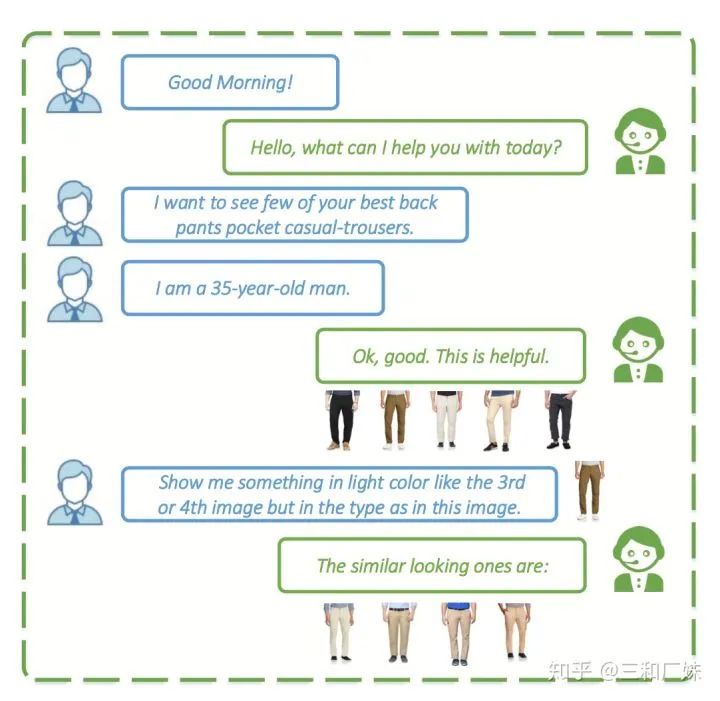
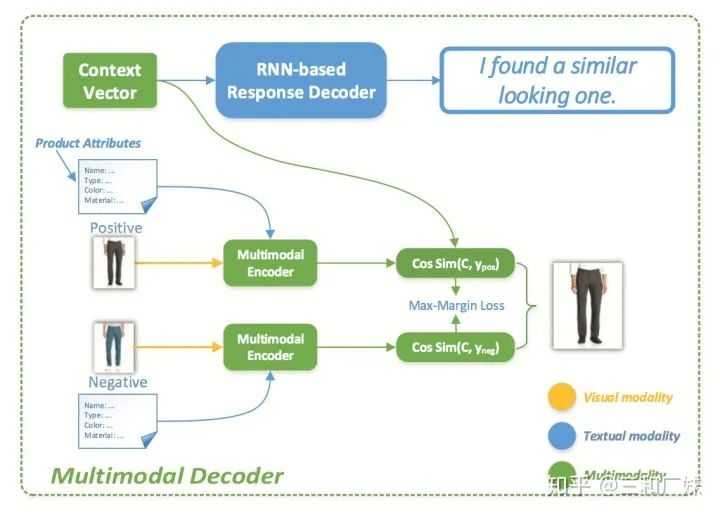
模型比较常规,encoder端,先CNN提取了图片特征,然后根据商品属性建一个属性分类树,文本常规处理,最后通过MFB融合
Decoder 时,文本RNNdecode, 但是图像居然是用求cos相似,就电商那种产品数据的量级,除非在业务上做很多前置工作,这种计算量就不现实
In all
这篇属于扩展NLP的广度,写的不深,选的论文和很随便(因为我不很了解),作为一个NLPer, 宽度上来说我觉得这也是一个方向.
原文标题:多模态中NLP与CV融合的一些方式
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
深度学习
+关注
关注
73文章
5614浏览量
124778 -
MLP
+关注
关注
0文章
57浏览量
5047
原文标题:多模态中NLP与CV融合的一些方式
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
视美泰多模态融合+姿态感知技术,让机器真正 “读懂” 世界

商汤科技正式开源多模态自主推理模型SenseNova-MARS

商汤开源SenseNova-MARS:突破多模态搜索推理天花板
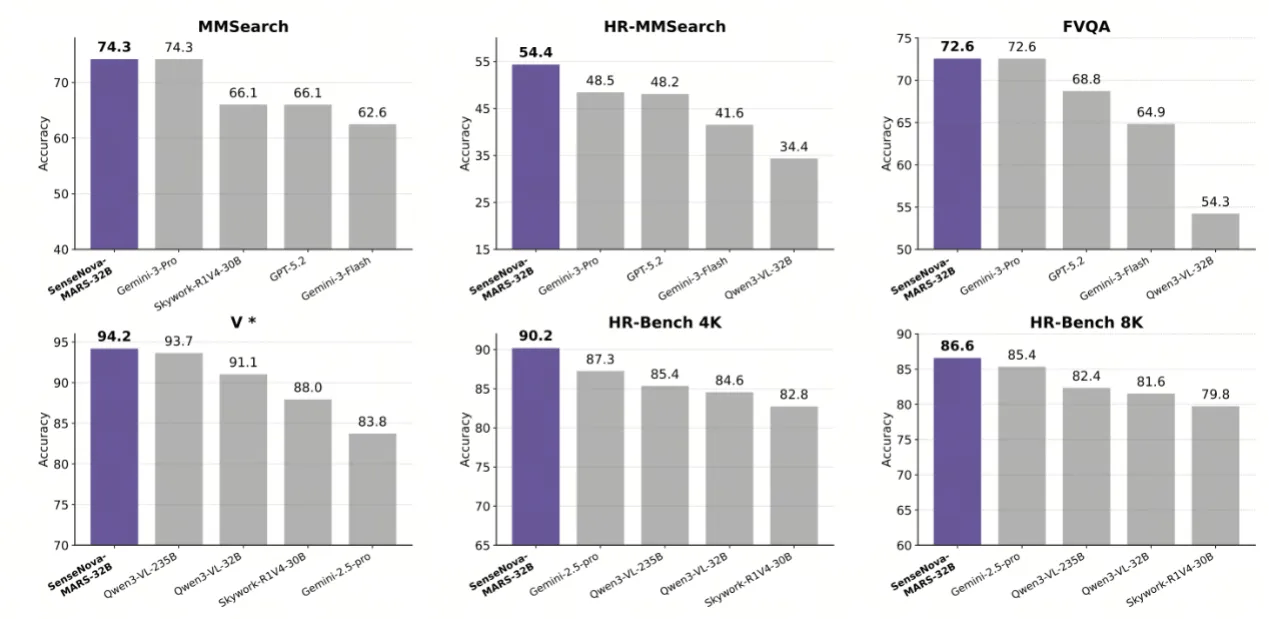
格灵深瞳多模态大模型荣登InfoQ 2025中国技术力量年度榜单
多模态感知大模型驱动的密闭空间自主勘探系统的应用与未来发展
商汤科技正式发布并开源全新多模态模型架构NEO

亚马逊云科技上线Amazon Nova多模态嵌入模型

米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
浅析多模态标注对大模型应用落地的重要性与标注实例
商汤科技多模态通用智能战略思考
NVIDIA助力图灵新讯美推出企业级多模态视觉大模型融合解决方案
多模态感知+豆包大模型!家居端侧智能升级




评论