 OpenAI重磅推出语言模型DALL·E和图像识别系统CLIP
OpenAI重磅推出语言模型DALL·E和图像识别系统CLIP

人工智能(AI)研究组织OpenAI重磅推出了最新的语言模型DALL·E和图像识别系统CLIP。
这两个模型是OpenAI第三代语言生成器的一个分支。两种神经网络都旨在生成能够理解图像和相关文本的模型。OpenAI希望这些升级后的语言模型能够以接近人类解释世界的方式来解读图像。
2020年5月,OpenAI发布了迄今为止全球规模最大的预训练语言模型GPT-3。GPT-3具有1750亿参数,训练所用的数据量达到45TB。对于所有任务,应用GPT-3无需进行任何梯度更新或微调,仅需要与模型文本交互为其指定任务和展示少量演示即可使其完成任务。
GPT-3在许多自然语言处理数据集上均具有出色的性能,包括翻译、问答和文本填空任务,还包括一些需要即时推理或领域适应的任务等,已在很多实际任务上大幅接近人类水平。
新发布的语言模型DALL·E,是GPT-3的120亿参数版本,可以按照自然语言文字描述直接生成对应图片!
这个新系统的名称DALL·E,来源于艺术家萨尔瓦多·达利(Salvador Dali)和皮克斯的机器人英雄瓦力(WALL-E)的结合。新系统展示了“为一系列广泛的概念”创造图像的能力,可从文字标题直接创建图像以表达概念。通过从文本描述而不是标签数据生成图像,可以为模型提供了更多有关含义的上下文。
开发人员将DALL·E称为“转换语言模型”(transformer language model),能够将文本和图像作为单个数据流接收。这种训练程序使得DALL·E不仅可以从零开始生成图像,而且还可以重新生成现有图像的任何矩形区域……。以一种与文本提示一致的方式。
这种语言模型能够反映人类语言的微妙之处,包括 “将不同的想法结合起来合成物体的能力”。例如,在DALL·E模型中输入“牛油果形状的扶手椅”,它就可以生成这样的图片:

DALL·E还扩展了被称为“零样本推理”(zero-shotreasoning)的GPT-3功能,这是一种强大的常识性机器学习形式。DALL·E将这一功能扩展到了视觉领域,并且在以正确的方式提示时能够执行多种图像到图像的翻译任务。

图像识别系统CLIP的通用性比当前针对单个任务的系统更好,可以用网上公开的文字图像配对数据集来训练。CLIP系统可用于对比语言-图像预训练,通过从网络图像中收集的自然语言监督学习视觉概念。OpenAI表示CLIP的工作方式是提供要识别的视觉类别的名称。
当将其应用于图像分类基准时,可以指示模型执行一系列基准,而无需针对每个测试进行优化。OpenAI表示:“通过不直接针对基准进行优化,我们证明它变得更具代表性。” CLIP方法可将“稳健性差距”缩小多达75%。
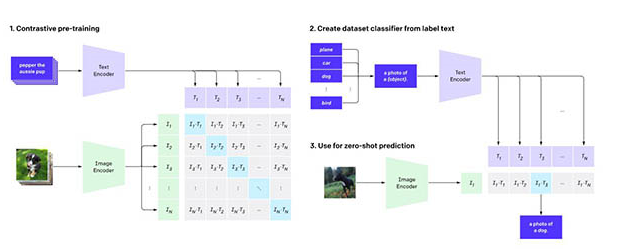
OpenAI 联合创始人、首席科学家 Ilya Sutskever认为,人工智能的长期目标是构建多模态神经网络,即AI能够学习不同模态之间的概念(文本和视觉领域为主),从而更好地理解世界,而 DALL·E 和 CLIP 使我们更接近“多模态 AI 系统”这一目标。
未来,我们将拥有同时理解文本和图像的模型。人工智能将能够更好地理解语言,因为它可以看到单词和句子的含义。
编辑:hfy
-
神经网络
+关注
关注
42文章
4842浏览量
108173 -
图像识别
+关注
关注
9文章
534浏览量
40180 -
人工智能
+关注
关注
1820文章
50324浏览量
266933 -
Clip
+关注
关注
0文章
35浏览量
7288 -
OpenAI
+关注
关注
9文章
1249浏览量
10279
发布评论请先 登录
如何让ResNet50图像识别模型在光计算硬件上飞快运行
海康威视矾花图像识别智能系统推动水质处理精细化管控
基于米尔MYC-YM90X安路飞龙DR1开发板仪表图像识别系统开发
华怡丰推出ISC-B/C系列图像识别传感器

EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
基于FPGA的数字识别系统设计
火车车号图像识别系统如何应对不同光照条件下的识别问题?

火车车号识别系统的基本原理是什么?
岸桥箱号识别系统的基本工作原理是什么?



工地AI行为识别系统作用
景区AI行为识别系统作用




评论