 CPLD和FPGA的基本结构
CPLD和FPGA的基本结构

CPLD是复杂可编程逻辑器件(Complex Programable Logic Device)的简称,FPGA是现场可编程门阵列(Field Programable Gate Array)的简称,两者的功能基本相同,编程等过程也基本相同(烧写文件不一样,但是是由软件自动产生的),只是芯片内部的实现原理和结构略有不同。
CPLD
CPLD主要由可编程I/O单元、基本逻辑单元、布线池和其他辅助功能模块构成。
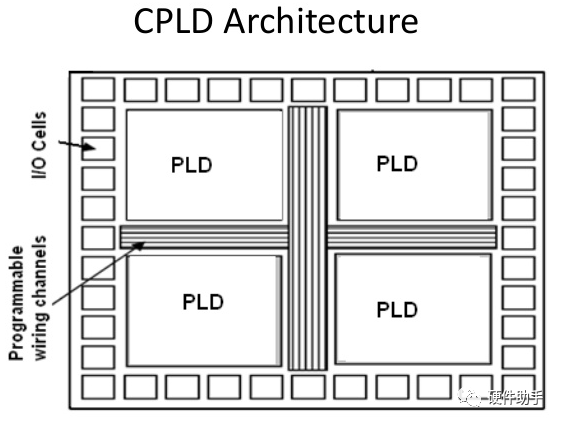
可编程逻辑单元
作用与FPGA的基本I/O口相同,但是CPLD应用范围局限性较大,I/O的性能和复杂度与FPGA相比有一定的差距,支撑的I/O标准较少,频率也较低。
基本逻辑单元
CPLD中基本逻辑单元是宏单元。所谓宏单元就是由一些与、或阵列加上触发器构成的,其中“与或”阵列完成组合逻辑功能,触发器用以完成时序逻辑。 与CPLD基本逻辑单元相关的另外一个重要概念是乘积项。所谓乘积项就是宏单元中与阵列的输出,其数量标志了CPLD容量。乘积项阵列实际上就是一个“与或”阵列,每一个交叉点都是一个可编程熔丝,如果导通就是实现“与”逻辑,在“与”阵列后一般还有一个“或”阵列,用以完成最小逻辑表达式中的“或”关系。
布线池、布线矩阵
CPLD中的布线资源比FPGA的要简单的多,布线资源也相对有限,一般采用集中式布线池结构。所谓布线池,其本质就是一个开关矩阵,通过打结点可以完成不同宏单元的输入与输出项之间的连接。由于CPLD器件内部互连资源比较缺乏,所以在某些情况下器件布线时会遇到一定的困难。由于CPLD的布线池结构固定,所以CPLD的输入管脚到输出管脚的延时固定,被称为Pin to Pin延时,用Tpd表示,Tpd延时反映了CPLD器件可以实现的最高频率,也就清晰地表明了CPLD器件的速度等级。
FPGA
FPGA由6部分组成,分别为可编程输入/输出单元、基本可编程逻辑单元、嵌入式块RAM、丰富的布线资源、底层嵌入功能单元和内嵌专用硬核等。
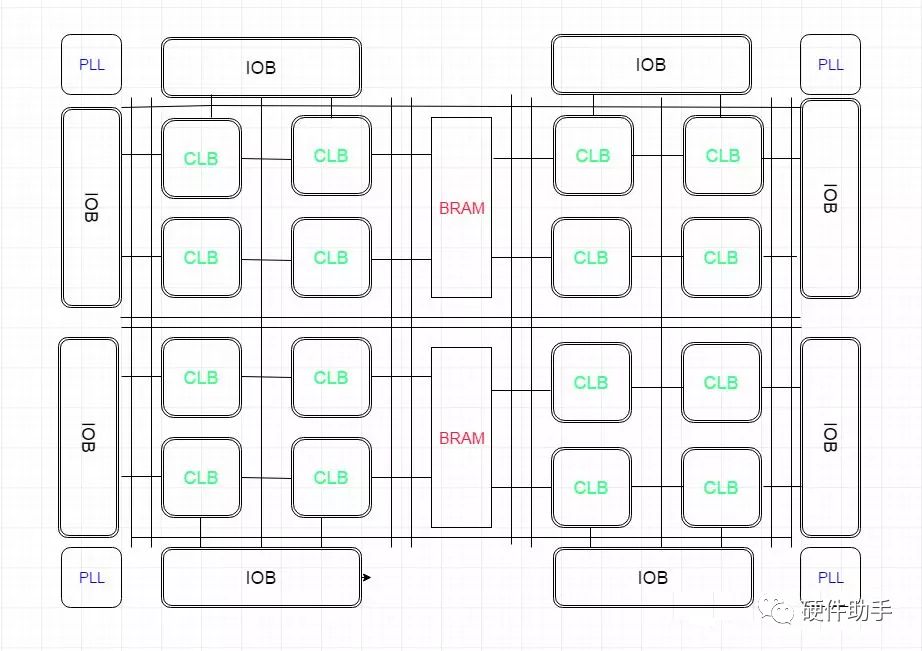
可编程输入/输出单元(IOB)
可编程输入/输出单元是芯片与外界电路的接口部分,完成不同电气特性下对输入/输出信号的驱动与匹配要求。FPGA内部的I/O按组分类,每组都能够独立地支持不同的I/O标准。通过软件的灵活配置,可适应不同的电气标准与I/O物理特性,可以调整匹配阻抗特性,可以改变上、下拉电阻,可以调整驱动电流的大小。 外部输入信号可以通过IOB模块的存储单元输入到FPGA的内部,也可以直接输入FPGA内部。当外部输入信号经过IOB模块的存储单元输入到FPGA内部时,其保持时间(Hold Time)的要求可以降低,通常默认为0。 为了便于管理和适应多种电器标准,FPGA的IOB被划分为若干个组(bank),每个bank的接口标准由其接口电压VCCO决定,一个bank只能有一种VCCO,但不同bank的VCCO可以不同。只有相同电气标准的端口才能连接在一起,VCCO电压相同是接口标准的基本条件。
基本可编程逻辑单元
FPGA的基本可编程逻辑单元是由查找表(LUT)和寄存器(Register)组成的,查找表完成纯组合逻辑功能。FPGA内部寄存器可配置为带同步/异步复位和置位、时钟使能的触发器,也可以配置成为锁存器。FPGA一般依赖寄存器完成同步时序逻辑设计。一般来说,比较经典的基本可编程单元的配置是一个寄存器加一个查找表,但不同厂商的寄存器和查找表的内部结构有一定的差异,而且寄存器和查找表的组合模式也不同。 了解底层配置单元的LUT和Register比率的一个重要意义在于器件选型和规模估算。由于FPGA内部除了基本可编程逻辑单元外,还有嵌入式的RAM、PLL或DLL,专用的Hard IP Core等,这些模块也能等效出一定规模的系统门,所以简单科学的方法是用器件的Register或LUT的数量衡量。
嵌入式块RAM
目前大多数FPGA都有内嵌的块RAM。嵌入式块RAM可被配置为单端口RAM、双端口RAM、内容地址存储器(CAM)以及FIFO等常用存储结构。 CAM,即为内容地址存储器。写入CAM的数据会和其内部存储的每一个数据进行比较,并返回与端口数据相同的所有内部数据的地址。简单的说,RAM是一种写地址,读数据的存储单元;CAM与RAM恰恰相反。 除了块RAM,Xilinx和Lattice的FPGA还可以灵活地将LUT配置成RAM、ROM、FIFO等存储结构。
丰富的布线资源
布线资源连通FPGA内部所有单元,连线的长度和工艺决定着信号在连线上的驱动能力和传输速度。根据工艺、长度、宽度和分布位置的不同而划分为4类不同的类别:
全局性的专用布线资源:用以完成芯片内部全局时钟和全局复位/置位的布线;
长线资源:用以完成器件Bank间的一些高速信号和一些第二全局时钟信号的布线;
短线资源:用来完成基本逻辑单元间的逻辑互连与布线;
其他:在逻辑单元内部还有着各种布线资源和专用时钟、复位等控制信号线。
由于在设计过程中,往往由布局布线器自动根据输入的逻辑网表的拓扑结构和约束条件选择可用的布线资源连通所用的底层单元模块,所以常常忽略布线资源。其实布线资源的优化与使用和实现结果有直接关系。
底层内嵌功能单元
内嵌功能模块主要指DLL(Delay Locked Loop)、PLL(Phase Locked Loop)、DSP和CPU等软处理核(Soft Core)。现在越来越丰富的内嵌功能单元,使得单片FPGA成为了系统级的设计工具,使其具备了软硬件联合设计的能力,逐步向SOC平台过渡。 DLL和PLL具有类似的功能,可以完成时钟高精度、低抖动的倍频和分频,以及占空比调整和移相等功能。Xilinx公司生产的芯片上集成了DLL,Altera公司的芯片集成了PLL,Lattice公司的新型芯片上同时集成了PLL和DLL。PLL和DLL可以通过IP核生成的工具方便地进行管理和配置。
内嵌专用硬核
与“底层嵌入单元”是有区别的,这里指的硬核主要是那些通用性相对较弱,不是所有FPGA器件都包含的硬核。 内嵌专用硬核是相对底层嵌入的软核而言的,指FPGA处理能力强大的硬核(Hard Core),等效于ASIC电路。为了提高FPGA性能,芯片生产商在芯片内部集成了一些专用的硬核。例如:为了提高FPGA的乘法速度,主流的FPGA中都集成了专用乘法器;为了适用通信总线与接口标准,很多高端的FPGA内部都集成了串并收发器(SERDES),可以达到数十Gbps的收发速度。 Xilinx公司的高端产品不仅集成了ARM,还内嵌了DSP Core模块,并提出MPSoC、RFSoC等概念。
原文标题:FPGA系列之“CPLD和FPGA的基本结构”
文章出处:【微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
FPGA
+关注
关注
1665文章
22608浏览量
641901 -
cpld
+关注
关注
32文章
1259浏览量
174408
原文标题:FPGA系列之“CPLD和FPGA的基本结构”
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
国产芯片突围下的FPGA+MCU:噱头之外的硬核趋势
FPGA电源设计:从理论到实践的全面指南
工程师高培解读XilinxVivadoFPGA设计进阶与AI自动编程

不用再画 CPLD!AG32 替代方案有多香?(二)
不用再画 CPLD!AG32 替代方案有多香?(一)
一起盘点AG32 MCU 的特性及产品特色,异构SOC入门推荐
使用Aurora 6466b协议实现AMD UltraScale+ FPGA与AMD Versal自适应SoC的对接
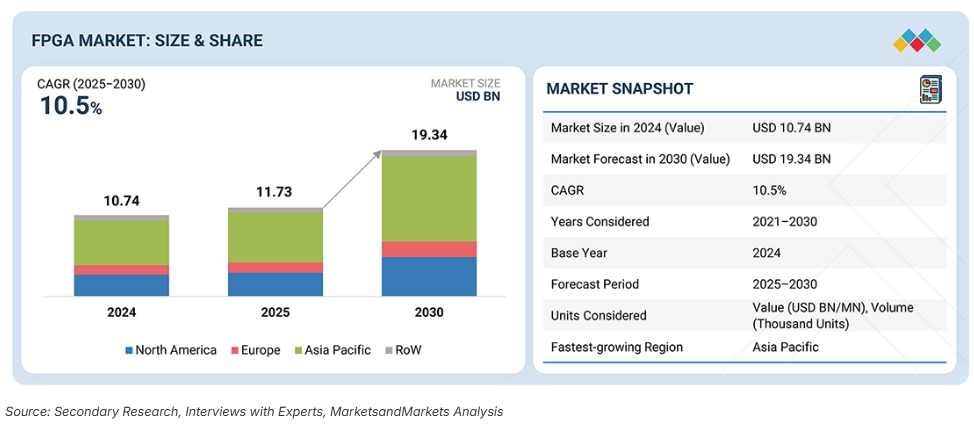
MarketsandMarkets FPGA行业报告,2026~2030 FPGA市场洞察
嵌入式与FPGA的区别
谁家在低成本MCU中集成CPLD/FPGA,这有何优势呢?
AG32 内置的CPLD 的DMA功能如何实现?
如何在FPGA部署AI模型
AG32:dma在cpld中的使用
Altera Agilex™ 3 FPGA和SoC FPGA

基于FPGA的压缩算法加速实现



评论