 一种越来越多被应用于加速机器学习应用的浮点格式bfloat16
一种越来越多被应用于加速机器学习应用的浮点格式bfloat16

Arm早前曾宣布其ArmV8-A架构的下一版本将包括对bfloat16的支持,现在透露了更多细节。
bfloat16是一种越来越多被应用于加速机器学习应用的浮点格式。谷歌、英特尔和不少新创公司都将bfloat16作为其AI加速架构的核心功能之一。
Bfloat16是由Google发明,最初在其第三代Tensor处理单元(TPU)中导入,作为加速机器学习之用。英特尔也认为该格式在未来AI计算中也有庞大的应用潜力,因此整合到其即将推出的“Cooper Lake”Xeon SP处理器,以及“Spring Crest”神经网络处理器中,未来的Xe GPU也会支持。而包括Wave Computing、Habana Labs和Flex Logix等AI芯片新创公司也采用了支持该计算格式的定制AI处理器。
bfloat16的主要想法是提供动态范围与标准IEEE-FP32相同的16位浮点格式,精度较低。相当于将8位的FP32指数字段的大小匹配,并将FP32分数字段的大小缩小到7位。
根据Arm首席架构师和研究员Nigel Stephens的说法,在大多数情况下,bfloat16格式与FP32一样准确,用于神经网络计算,但是以一半的位址就可以完成任务。因此,与32位相比,吞吐量可以翻倍,内存需求可以减半。在多数情况下,blfloat16可以成为这些机器学习算法中FP32的“插入式”替代品。由于神经网络的计算性质,只要数据类型具有足够的范围和精度,就可以很好地适应少量噪声,精准的完成模型训练工作。
Arm将bfloat16的支持被放到ArmV8-A下的所有浮点处理的相关指令集,包含SVE(可扩展矢量扩展)、AArch64 Neon(64位SIMD)和AArch32 Neon(32位SIMD)。通过相关扩展的支持,加速基于Arm的客户端和服务器的机器学习推理和培训练过程。虽然Arm服务器市占率仍然很小,但其在智能手机等客户端方面拥有几乎绝对的统治地位,这意味着未来的手持式和物联网设备将很快能够利用更紧凑的数字格式来处理机器学习。
当然,Arm如果越强,那么采用自有AI架构的芯片设计业者压力其实也会越大,就好比华为先后使用寒武纪与达芬奇架构,都是封闭的专有架构,高通也是采用DSP结合NPU计算,如果Arm官方架构性能有飞跃性的改进,那么这些采用定制AI架构的芯片设计者可能最终会被迫放弃自己的封闭架构,转而拥抱Arm的开放架构。而这也有助于发展整体AI生态,毕竟使用相同开发环境的硬件基数越大,就能吸引更多应用开发者共同耕耘相关生态。
值得注意的是,Arm决定在SVE中加入bfloat16的支持这点。由于SVE是专门针对高性能计算的矢量指令集,截至目前为止,仅有富士通一家采用,并应用于其A64FX芯片上。Arm方面表示,由于HPC用户对机器学习的兴趣持续增加,过去只能依靠GPU方案来进行加速,若能在单一架构处理完机器学习的工作,那么就不用再额外花费成本添购专用的加速硬件。
使用bfloat16还有另一个好处,那就是它具有与FP32相同的动态范围,这使得转换现有使用FP32的现有计算代码非常简单,可以大规模无痛转换既有的FP32应用到blfloat16数据格式下。
然而,SVE原本就可以针对从128位到2048位等不同的矢量长度来实现计算工作,理论上,bfloat16应该放在128位的Neon计算单元内比较合理。但实际上,数据的吞吐量其实还是要取决于硬件的实现选择,比如说SVE执行单元的数量,以及Neon计算单元的数量。
而随着Arm增加了bfloat16这个数据格式的支持,借以加速AI计算,这也让GPU成为目前主流机器学习加速硬件中唯一不支持这种数据格式的架构,而英特尔即将推出的Xe GPU也会加入该格式的支持,包含AMD或NVIDIA,应该都会在下一代产品中增加此数据格式的支持。
根据ARM做的模拟,不同类型的运算中bfloat16带来的性能提升不等,少的有1.6倍性能,多的可达4倍性能,性能成长相当惊人。
-
ARM
+关注
关注
135文章
9589浏览量
393769 -
神经网络
+关注
关注
42文章
4844浏览量
108201 -
机器学习
+关注
关注
67文章
8567浏览量
137250
发布评论请先 登录
快问快答:为什么越来越多制造企业在选型气密仪时,更看重源头实力厂家?

PyTorch 中RuntimeError分析
快问快答:为什么越来越多海外客户选择中国国产气密性检测品牌?
为什么原厂越来越需要一套自己的 Studio
智慧水务为什么越来越多项目选择 BL118|水务物联网边缘计算方案解析

如何使用 ARM FPU 加速浮点计算?
risc-v中浮点运算单元的使用及其设计考虑
为什么越来越多的场所选择智能闸口控制系统?它有哪些优势?
为什么越来越多政府单位用上了国产云终端?它比你想的更能打

国产地物光谱仪为什么越来越多被科研团队选择?
RK3576 vs RK3588:为何越来越多的开发者转向RK3576?
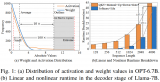
基于双向块浮点量化的大语言模型高效加速器设计
详解原子层沉积薄膜制备技术



评论