 一种基于RefineDet多层特征图融合的多尺度人脸检测方法
一种基于RefineDet多层特征图融合的多尺度人脸检测方法

摘要:
针对车站、商场等大型场所中客流量大、背景复杂等原因导致多尺度人脸检测精度低的问题,建立了一种基于RefineDet多层特征图融合的多尺度人脸检测方法。首先利用第一级网络进行特征提取并在不同尺度的特征图上粗略预估人脸位置;然后在第二级中通过特征金字塔网络将低层特征与高层特征融合,进一步增强小尺寸人脸的语义信息;最后,通过置信度和焦点损失函数对检测框进行二次抑制,达到边框的精确回归。实验中将人脸候选区域的宽高比只设置为1:1,以此来降低运算量并提高人脸检测精度。在Wider Face数据集上的实验结果表明,该方法能有效检测不同尺度的人脸,在Easy、Medium、Hard 3个子数据集上测试结果分别为93.4%、92%、84.4%的MAP,尤其对小尺寸人脸的检测精度有明显提高。
0 引言
人脸检测[1]作为人脸识别[2-3]、人脸对齐、人脸验证[4]以及人脸跟踪[5]等应用的关键步骤,其首要任务是判断视频或给定图像中是否存在人脸,再精确定位出人脸的位置和大小。在一些人脸目标尺寸跨度大且小目标众多的应用场景,人脸检测的效果将直接影响人脸识别等后续技术应用的准确率,因此研究多尺度人脸检测具有重要意义。 早期人脸检测算法多是人工提取特征,训练分类器,再进行人脸检测。如VIOLA P A和JONES M[6]提出的Haar-Like与AdaBoost级联的方法,其检测速度较快,但对多尺度、姿态多样性等情形检测效果不理想。随着深度学习在机器学习中的不断发展,卷积神经网络(Convolutional Neural Network,CNN)提取特征更加多样化、鲁棒性更好,在图像识别以及目标检测等领域[7-8]得到广泛应用。其中以Faster R-CNN[9]为代表的算法首先通过区域预测网络(Region Proposal Network,RPN)产生感兴趣的候选区域,再对该区域提取尺度不变的CNN特征,最后对区域进行分类和回归。JIANG H[10]等将Faster R-CNN应用于人脸检测,取得了较好效果,但速度较慢。文献[11]将人脸检测与人脸关键点检测结合,网络层数浅,检测速度快但精度较低。HU P[12]等人通过多尺度模板,利用图像上下文信息来解决小尺寸人脸检测精度较低的问题。 为进一步提高人脸检测精度,本文通过改进RefineDet[13]网络模型结构,建立了一种多尺度人脸检测模型。首先对待检测图像归一化处理,利用CNN提取图像特征,再通过特征金字塔网络[14](Feature Pyramid Networks,FPN)将更底层的conv3_3特征图与高层特征图进行融合,以便增强小尺寸人脸的语义信息,提高小目标人脸的检测精度。然后利用置信度和损失函数对检测框进行二次抑制,缓解类别失衡[15]问题。最后通过非极大值抑制算法得到精确回归后的人脸检测框和相应的位置信息。根据人脸区域特点,将人脸候选框的宽高比只设为1:1,以减少计算量进而提高检测精度。
1 多尺度人脸检测模型
1.1 改进的RefineDet多尺度检测模型网络结构
RefineDet是基于SSD[16]的改进方法,以VGG16[17]作为特征提取的骨干网络,包含fc6和fc7两个全连接层转换成的conv_fc6、conv_fc7以及扩展的conv6_1、conv6_2。其检测网络模型结构如图1中虚线框部分所示,采用conv4_3、conv5_3、conv_fc7和conv6_2作为检测层。
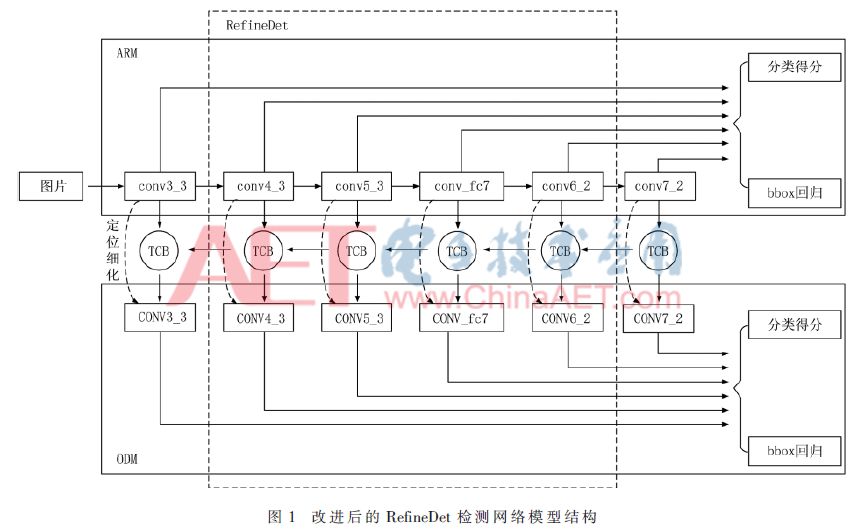
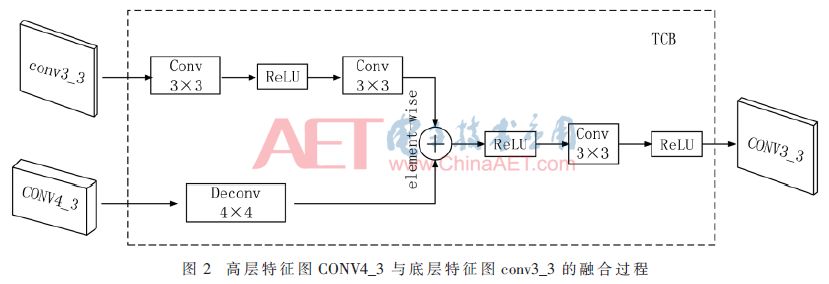
在CNN提取图像特征的过程中,感受野[18]用来表示卷积神经网络每一层输出的特征图上的像素点在原始图像上映射区域的大小。输入RefineDet网络的图像,由于卷积层与池化层之间均为局部连接,神经元无法对原始图像的所有信息进行感知,且每经过一次2×2的最大池化层处理,特征图变为原来的一半。随着网络层加深,特征图会越来越小,小尺寸人脸的信息也会逐步丢失,提取的特征也更抽象。因此,越高层的特征图对应原始图像的范围越大,包含语义层次更高的特征;越低层的特征图对应原始图像的范围越小,包含的特征更趋向于局部细节。可见,对于近景下的较大人脸需要更高层的特征图进行检测,而远景下的小尺寸人脸可以在更低层的特征图上检测到。为了提高不同尺度的人脸检测精度,进一步改善整个网络的检测性能,本文在RefineDet特征融合部分加入更低层的conv3_3特征图,以便检测较小尺寸的人脸,并在conv6_2后面添加额外的conv7_1和conv7_2,以便检测较大的人脸区域。改进的RefineDet检测网络模型结构如图1所示,选取conv3_3、conv4_3、conv5_3、conv_fc7、conv6_2和conv7_2 6个层的特征图作为检测层。 网络模型主要包括区域优化模块(Anchor Refine Module,ARM)和目标检测模块(Object Detect Module,ODM)。对输入640像素×640像素的待检测图片,在ARM中经过卷积层特征提取后得到不同大小的特征图,可粗略预估人脸的位置和得分,并滤除一些无效候选区,以减少分类器的搜索空间并且粗略地调整保留区域的位置和大小。同时,ARM的特征图通过连接模块(Transfer Connection Block,TCB)输入到ODM中,将高层特征与底层特征进行融合,用来增强底层特征的语义信息,以便检测更小的人脸目标。本文利用特征图融合的方式增加不同层之间的联系,通过这样的连接,检测网络中的特征图都融合了不同尺度、不同语义强度的特征,以此保证检测层的特征图可以检测不同尺度的人脸。此处以ODM的高层特征图CONV4_3和ARM的底层特征图conv3_3融合为例,其过程如图2所示,卷积核大小为3×3,通道数为256,反卷积核大小为4×4,步长为2,通道数为256。核大小为3×3,通道数为256,反卷积核大小为4×4,步长为2,通道数为256。不同层的特征图大小各不相同,因此,CONV4_3先通过反卷积操作缩放成与conv3_3特征图相同的大小;然后通过element-wise相加进行融合,得到CONV3_3;最后ODM对特征融合后的人脸候选区域进行更精确的回归,并且通过非极大值抑制算法得到不同尺度人脸的检测结果。
1.2 检测层参数设置
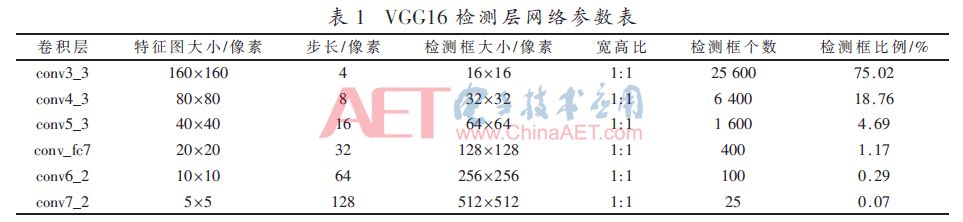
RefineDet选择conv4_3为初始检测层,步长为8,在特征图上移动一点相当于在原始图像上移动8个像素,这种设置不适合检测更小尺寸目标。本文将conv3_3作为初始检测层,特征图步长设为4,更利于检测小尺寸人脸。从conv3_3到conv7_2,宽高比为1:1,检测层参数设置如表1所示。通过在6层卷积特征图上设置不同大小的人脸检测框,能有效提高多尺度人脸的检测精度。
1.3 损失函数
实验中对于一张640×640的图像,人脸所占比例远远小于背景所占比例,图像中大部分区域为负样本。模型训练过程中,按照表1在每个卷积层生成不同数量的检测框,则conv3_3产生25 600个16×16的检测框,占检测框总数的75.02%,如果将全部正负样本都用来训练,这会引起类不平衡的问题,导致检测精度下降。因此,为了缓解失衡,利用损失函数对检测框进行二次抑制。当负样本的置信度大于0.99时,直接舍弃该候选区域,即对检测框进行首次抑制。 本文的损失函数主要包括ARM和ODM两部分损失,如式(1)所示。


式中,pt为不同类别的分类概率,pt越大,权重(1-pt)γ越小,这样对于一些很容易区分的样本可通过权重得到抑制,进而减少检测框的数量。αt用来调节正负样本的比例,本文采用与文献[15]相同的参数设置,正负样本比例为1:3,即αt=0.25,γ=2,实验表明,该参数适用于本文模型。
2 实验过程与结果分析
2.1 人脸数据集选择
实验采用Wider Face数据集,包含Easy、Medium、Hard 3个类别子集。该数据集共有32 203张图片,并标注了393 703张人脸。其中Easy子集为尺寸大于300像素的人脸,容易检测;Medium子集人脸尺寸为50~300像素,检测难度适中;Hard子集包含尺寸为10~50像素的小目标人脸,较难检测。该数据集适合本文建立的多尺度人脸检测模型。
2.2 模型训练过程
实验在Win10操作系统下进行,计算机配置为NVIDIA GeForce GTX 1080Ti显卡,采用的深度学习框架为Caffe。为了使训练所得模型对不同尺度的人脸有更好的鲁棒性,本文采用文献[16]中的随机光照失真以及裁剪原始图像并反转的方法扩充训练样本集。用ImageNet分类任务上预训练好的VGG16 卷积神经网络初始化特征并提取网络卷积层权重,训练过程采用随机梯度下降算法(SGD)优化整个网络模型。 本文训练过程采用SSD的匹配策略,不同的是将检测框与真实框的重叠率阈值由0.5降为0.35,大于0.35的判断为正样本,以此来增大匹配到的检测框数量。另外,网络初始学习率设置为0.000 5,8万次迭代后降为0.000 01,12万次迭代后设置为0.000 002,动量为 0.9,权重衰减为0.000 5,批次大小设置为4,共进行20万次迭代。
2.3 不同尺度的人脸检测结果
为了验证方法的有效性,本文在Wider Face验证集上进行实验验证。首先选择RefineDet的网络模型结构,输入640×640大小的图像,宽高比设为1:1,本文将其称之为模型A;其次,以相同的输入,选择加入底层特征conv3_3后的6层卷积特征图作为检测层进行实验,称之为模型B;最后,本文在模型B的基础上,采用focal loss作为损失函数进行实验,称之为本文模型。验证结果如表2所示。
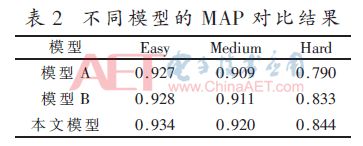
由表2可见,在输入相同的情况下,模型B相比于模型A在Easy、Medium、Hard 3个子集上的平均检测精度(Mean Average Precision,MAP)分别提高了0.1%、0.2%和4.3%,表明加入底层conv3_3的特征融合后可以有效改善小尺寸人脸的语义信息,进而提高多尺度人脸检测精度。本文模型相比于模型B在3个子集上的检测精度又分别提高了0.6%、0.9%和1.1%,表明改进损失函数能有效缓解类别不平衡的问题,进而提高检测精度。
2.4 与其他方法比较
为进一步验证模型的性能,将本文方法与近年来的主流算法ScaleFace[20]、Multitask Cascade CNN[11]、HR[12]在相同实验环境和相同数据集上进行了对比,采用官方评估方法进行评估[21]。在Wider Face人脸验证集上得到的P-R曲线如图3所示。
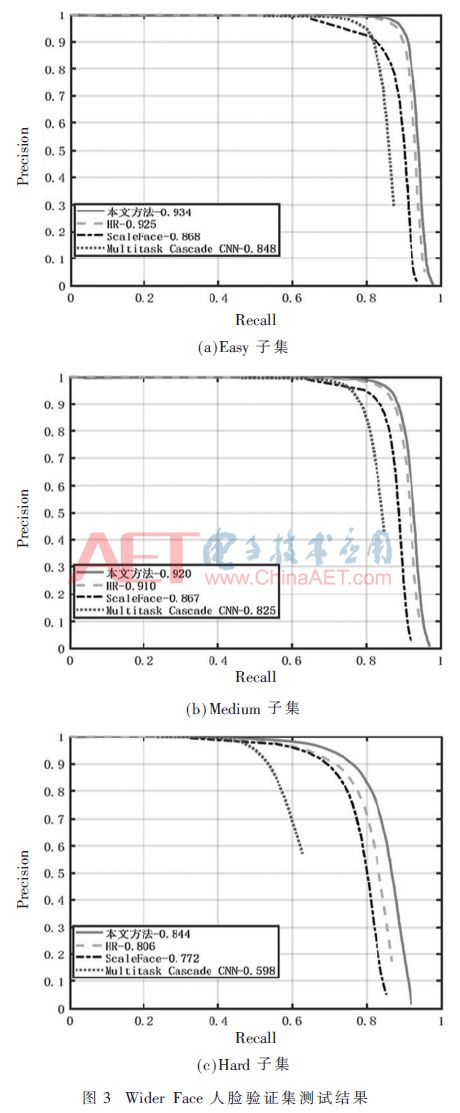
P-R图中横坐标表示检测框的召回率(Recall),纵坐标表示检测精度(Precision)。召回率用来评估检测出来的人脸占样本标记总人脸数的比例,检测精度用来评估检测出的正确人脸占检测出的总人脸数的比例,因此,曲线右上越凸,表示检测效果越好。由图3可见,本文方法较其他方法在检测精度上均有所提高,尤其在Hard子集上更达到了84.4%的检测精度,表明了方法的有效性,也显示了该模型检测小尺寸人脸的优越性。
2.5 检测效果
图4为本文方法与RefineDet的检测结果对比,矩形框表示检测出的人脸位置,圆形框表示两者的着重对比区域。由图4(a)和图4(c)可见,图像中的人脸尺寸大小不一,RefineDet对于检测背景中小尺寸人脸存在明显缺陷,不能有效检测,而本文方法可以在一张图片上同时检测不同尺度人脸。图4(b)和图4(d)相比,在人脸较小且密集的情景下,RefineDet漏检而本文方法在检测小尺寸人脸上有明显优势。

3 结论
本文建立了一种基于RefineDet多层特征融合的多尺度人脸检测方法,网络结构为两级级联模式,第一级ARM模块对人脸检测框进行粗略回归,第二级ODM模块经与底层特征融合后再对人脸检测框完成精确回归。检测网络在6层不同的特征图上进行,能有效检测16×16的小尺寸人脸区域,以及520×520较大的人脸区域,对比其他人脸检测方法,本文方法能更好地处理人脸尺寸众多且密集的情况,特别是小尺寸人脸检测精度有明显提高。
参考文献
[1] 霍芋霖,符意德.基于Zynq的人脸检测设计[J].计算机科学,2016,43(10):322-325.
[2] 李小薪,梁荣华.有遮挡人脸识别综述:从子空间回归到深度学习[J].计算机学报,2018,41(1):177-207.
[3] GAO Y,MA J,YUILLE A L,et al.Semi-supervised sparse representation based classification for face recognition with insufficient labeled samples[J].IEEE Transactions on Image Processing,2017,26(5):2545-2560.
[4] MAJUMDAR A,SINGH R,VATS M,et al.Face verification via class sparsity based supervised encoding[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1273-1280.
[5] KHAN M H,MCDONAGH J,TZIMIROPOULOS G,et al.Synergy between face alignment and tracking via discriminative global consensus optimization[C].International Conference on Computer Vision.IEEE,2017:3811-3819.
[6] VIOLA P A,JONES M.Robust real-time face detection[C].Proceedings of IEEE Conference on Computer Vision.IEEE,2001:747.
[7] 黄友文,万超伦.基于深度学习的人体行为识别算法[J].电子技术应用,2018,44(10):1-5.
[8] 周进凡,张荣芬,马治楠,等.基于深度学习的胸部X光影像分析系统[J].电子技术应用,2018,44(11):29-32.
[9] REN S,HE K,GIRSHICK R B,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[10] JIANG H,LEARNEDMILLER E G.Face detection with the faster R-CNN[C].IEEE International Conference on Automatic Face Gesture Recognition.IEEE,2017:650-657.
[11] ZHANG K,ZHANG Z,LI Z,et al.Joint face detection and alignment using multitask cascaded convolutional networks[J].IEEE Signal Processing Letters,2016,23(10):1499-1503.
[12] HU P,RAMANAN D.Finding tiny faces[J].Computer Vision and Pattern Recognition,Hawaii,USA,2017:1522-1530.
[13] ZHANG S,WEN L,BIAN X,et al.Single-shot refinement neural network for object detection[C].IEEE Conference on Computer Vision and Pattern Recognition,2018:4203-4212.
[14] LIN T,DOLLAR P,GIRSHICK R B,et al.Feature pyramid networks for object detection[C].IEEE Conference on Computer Vision and Pattern Recognition,2017:936-944.
[15] LIN T,GOYAL P,GIRSHICK R B,et al.Focal loss for dense object detection[C].International Conference on Computer Vision.IEEE,2017:2999-3007.
[16] LIU W,ANGUELOY D,ERHAN D,et al.SSD:single shot multibox detector[C].European Conference on Computer Vision,Amsterdam,Netherlands,2016:21-37.
[17] SIMONYAN K,ZISSERMAN.A very deep convolutional networks for large-scale image recognition[C].International Conference on Learning Representations,2015.
[18] LUO W,LI Y,URTASUN R,et al.Understanding the effective receptive field in deep convolutional neural networks[C].29th Conference on Neural Information Processing Systems,Barcelona,Spain,2016:4898-4906.
[19] DAI J,LI Y,HE K,et al.R-FCN:object detection via region-based fully convolutional networks[C]. 29th Conference on Neural Information Processing Systems,2016:379-387.
[20] YANG S,XIONG Y,LOY C C,et al.Face detection through scale-friendly deep convolutional networks[J].arXiv:Computer Vision and Pattern Recognition,2017.
[21] YANG S,LUO P,LOY C C,et al.Wider face: a face detection benchmark[C].IEEE Conference on Computer Vision and Pattern Recognition,2016:5525-5533.
-
图像
+关注
关注
2文章
1096浏览量
42438 -
人脸识别
+关注
关注
77文章
4132浏览量
88761 -
神经元
+关注
关注
1文章
369浏览量
19196
原文标题:【学术论文】一种改进的RefineDet多尺度人脸检测方法
文章出处:【微信号:ChinaAET,微信公众号:电子技术应用ChinaAET】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
共聚焦显微镜在晶圆检测中的应用


瑞芯微(EASY EAI)RV1126B 人脸识别使用

瑞芯微(EASY EAI)RV1126B 人脸检测使用
如何通过地址生成器实现神经网络特征图的padding?
一种新的无刷直流电机反电动势检测方法
一种新的无刷直流电机反电动势检测方法
一种带通滤波器在无位置传感器转子检测中的应用
【Milk-V Duo S 开发板免费体验】人脸检测
芯片制造中的膜厚检测 | 多层膜厚及表面轮廓的高精度测量

【EASY EAI Orin Nano开发板试用体验】人脸识别提升
人脸识别门禁终端的一般故障排查方法




评论