 电子发烧友App
电子发烧友App


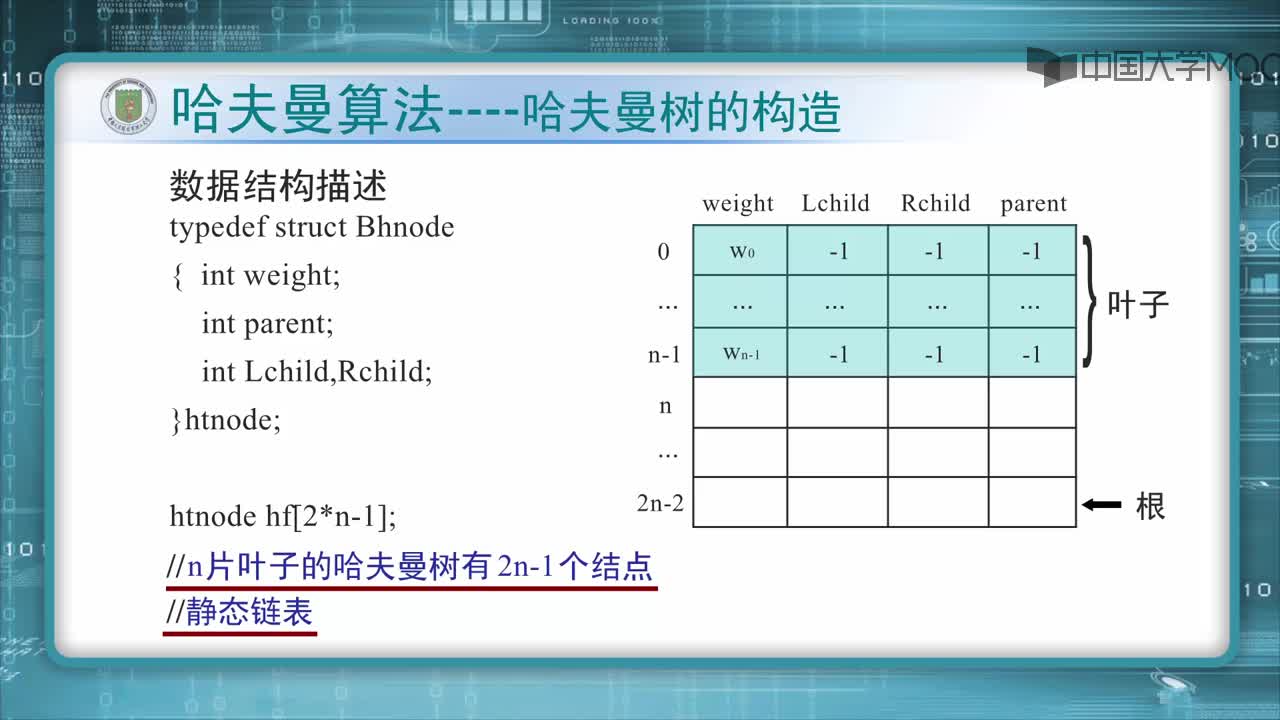
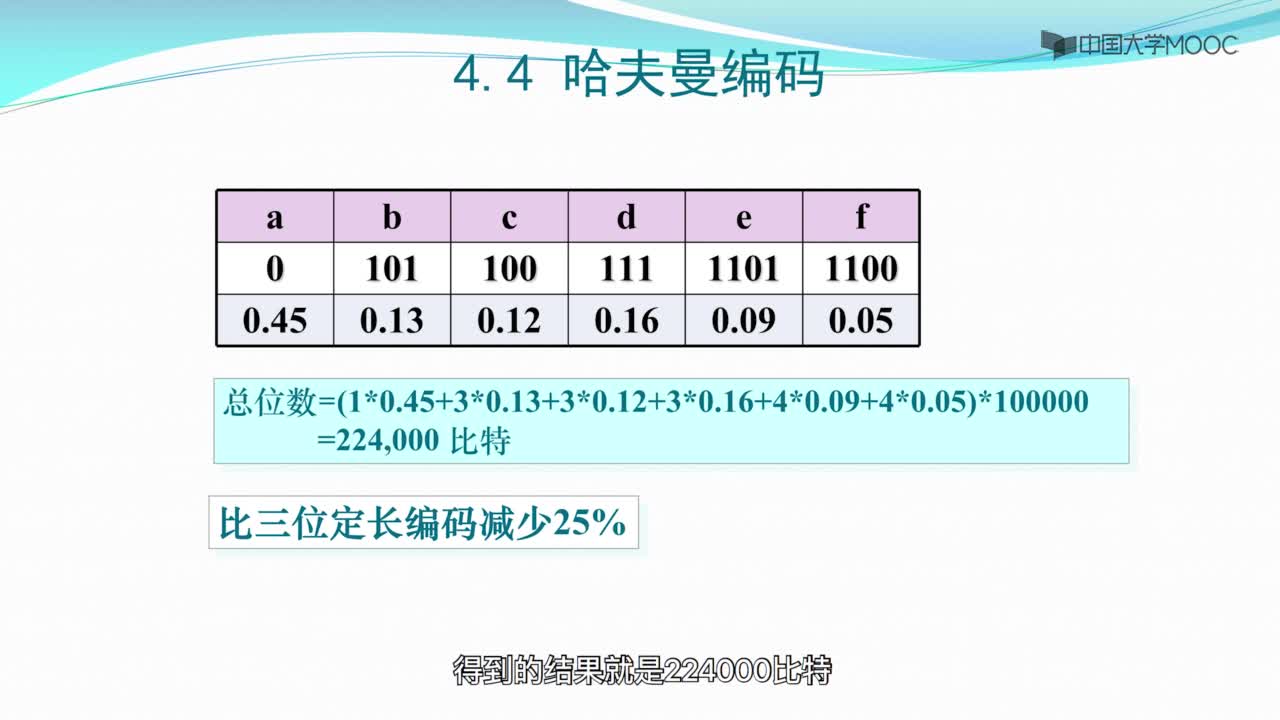
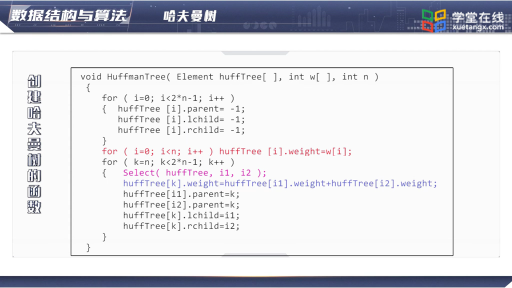
哈夫曼算法原理
1952年, David A. Huffman提出了一个不同的算法,这个算法可以为任何的可能性提供出一个理想的树。香农-范诺编码(Shanno-Fano)是从树的根节点到叶子节点所进行的的编码,哈夫曼编码算法却是从相反的方向,暨从叶子节点到根节点的方向编码的。
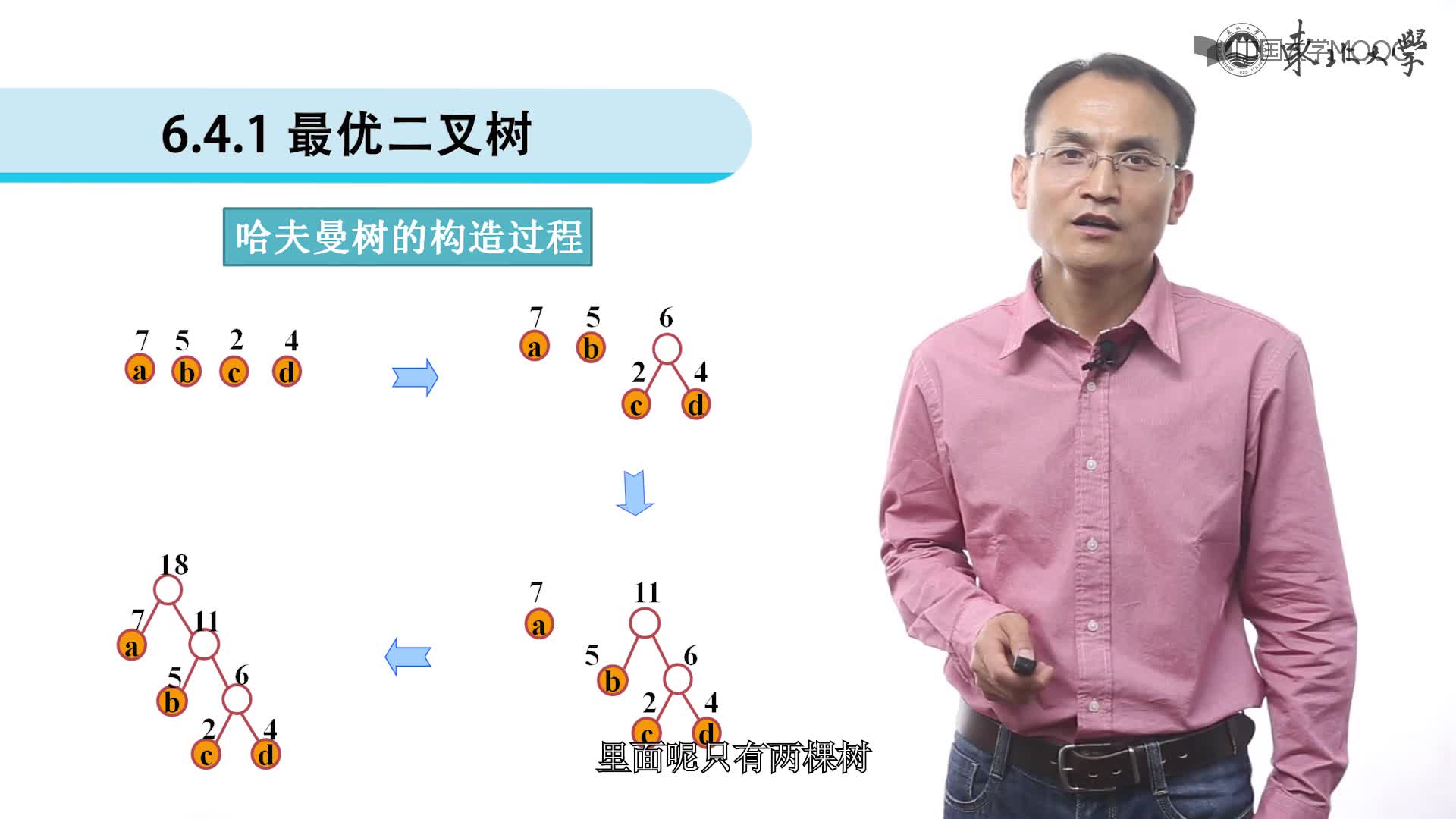
1.为每个符号建立一个叶子节点,并加上其相应的发生频率
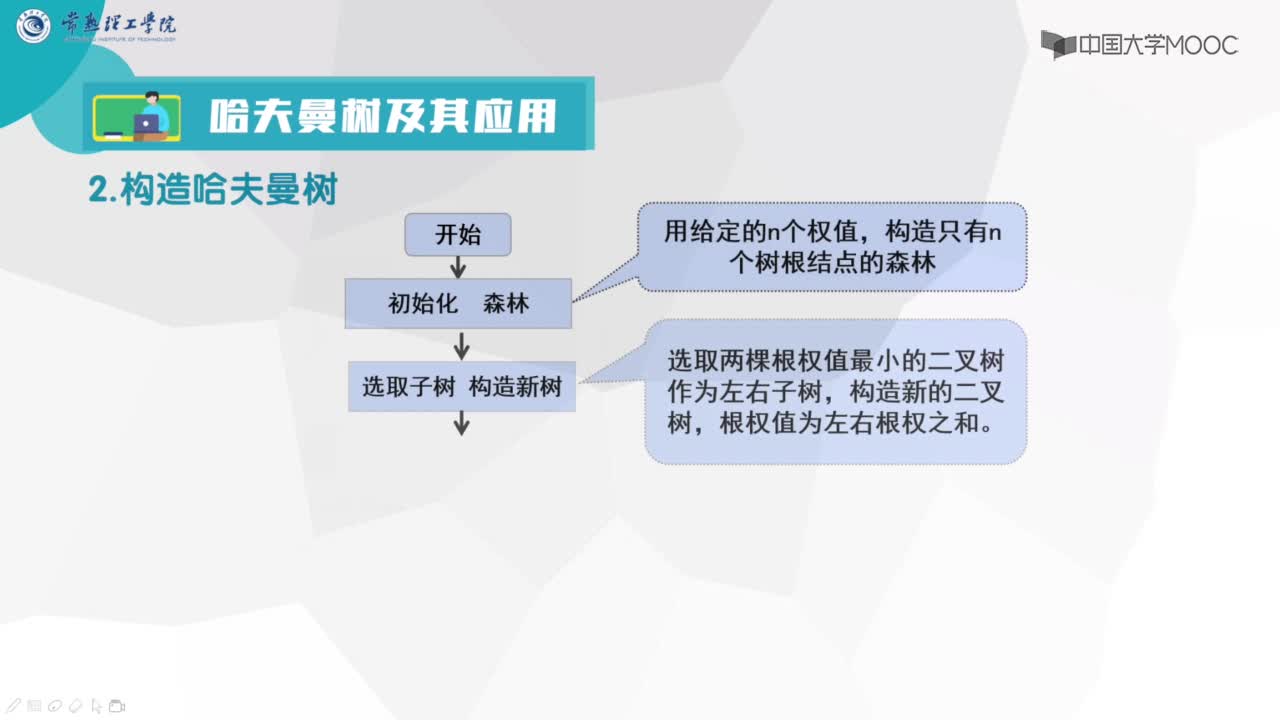
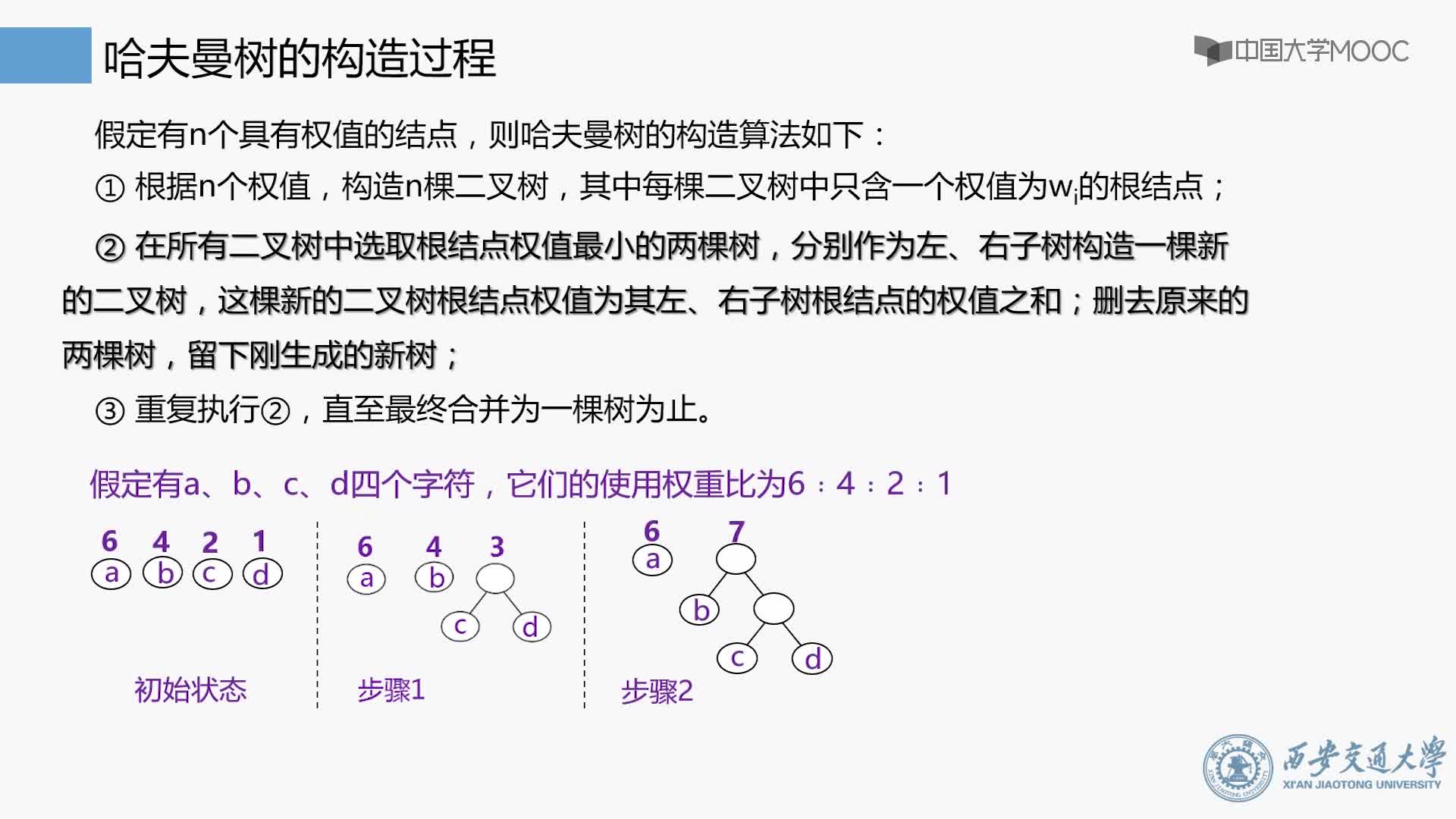
2.当有一个以上的节点存在时,进行下列循环:
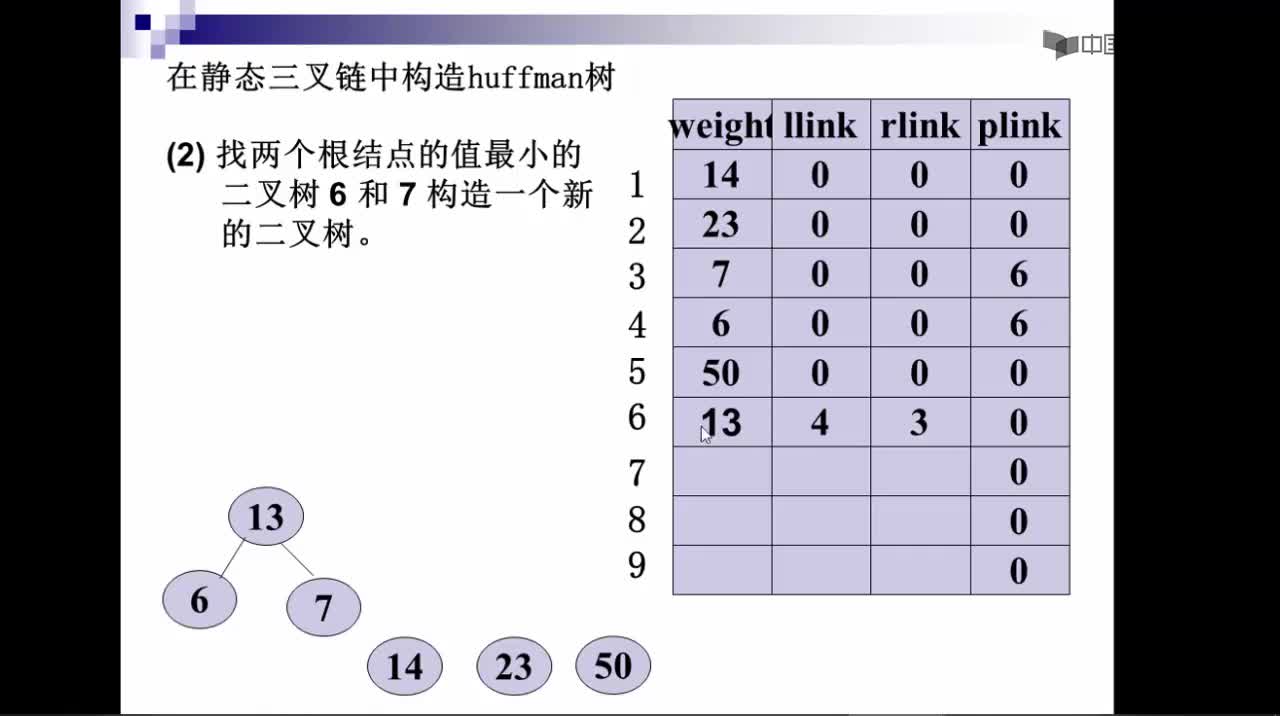
1)把这些节点作为带权值的二叉树的根节点,左右子树为空
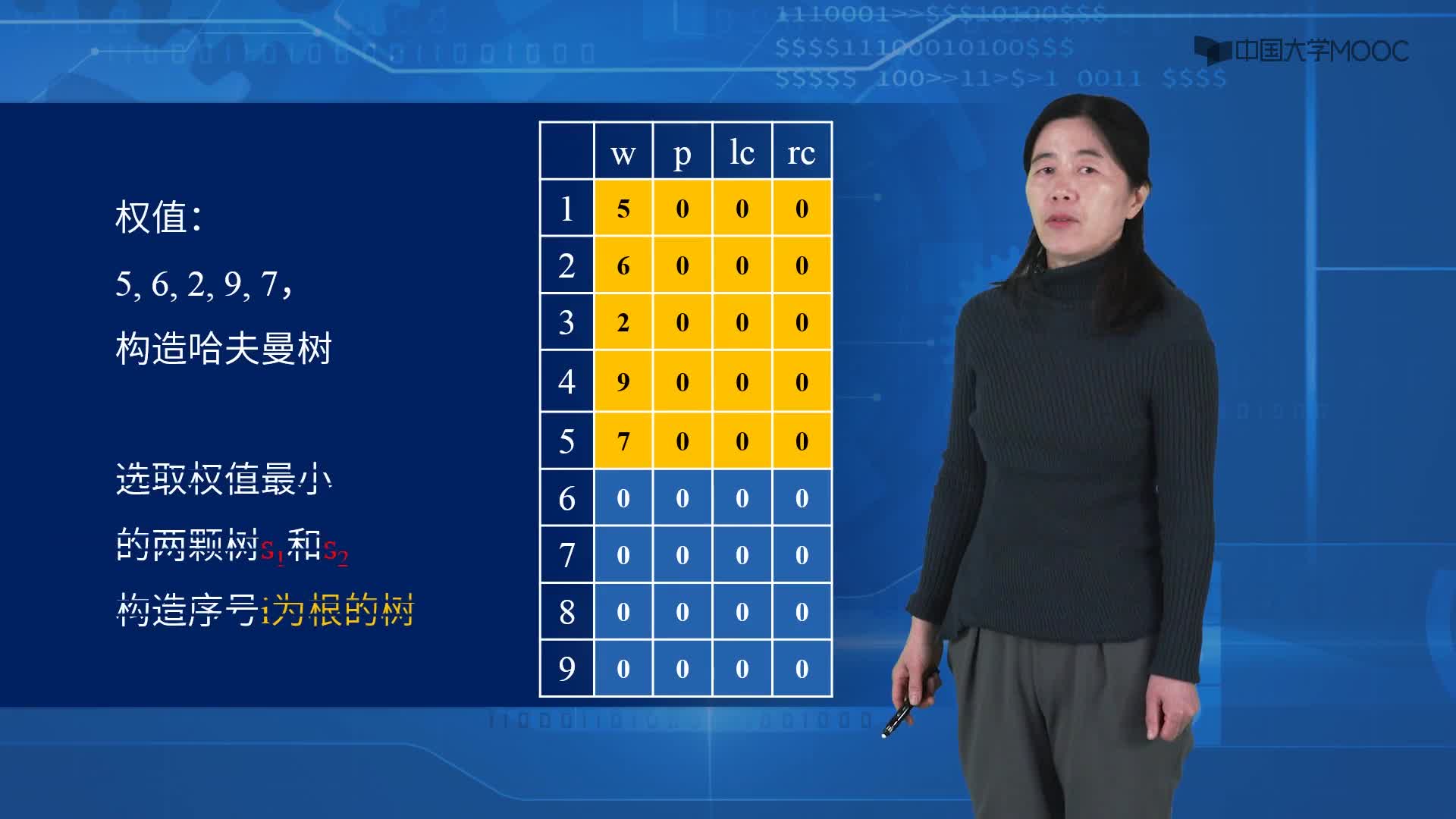
2)选择两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且至新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
3)把权值最小的两个根节点移除
4)将新的二叉树加入队列中。
5)最后剩下的节点暨为根节点,此时二叉树已经完成。
哈夫曼树的应用
哈夫曼编码:
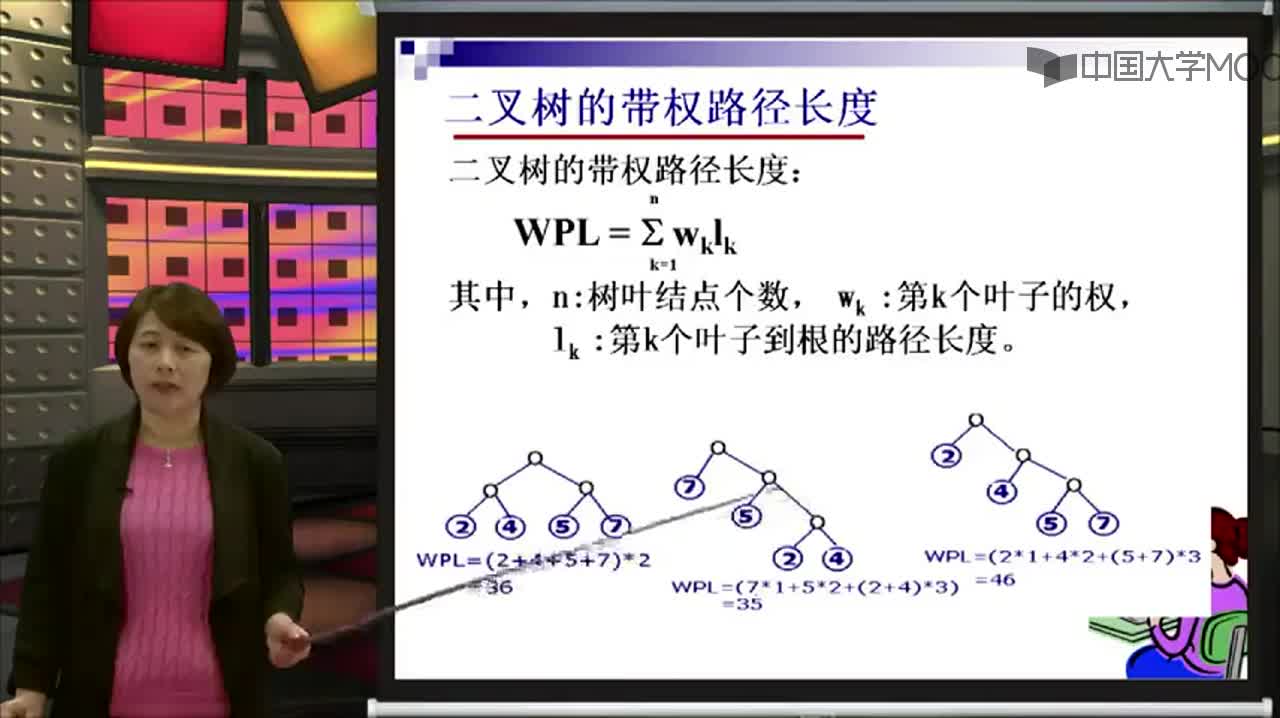
哈夫曼树可以直接应用于通信及数据传送中的二进制编码。设: D={d1,d2,d3…dn}为需要编码的字符集合。
W={w1,w2,w3,…wn}为D中各字符出现的频率。 现要对D中的字符进行二进制编码,使得:
(1) 按给出的编码传输文件时,通信编码的总长最短。
(2) 若di不等于dj,则di的编码不可能是dj的编码的开始部分(前缀)。
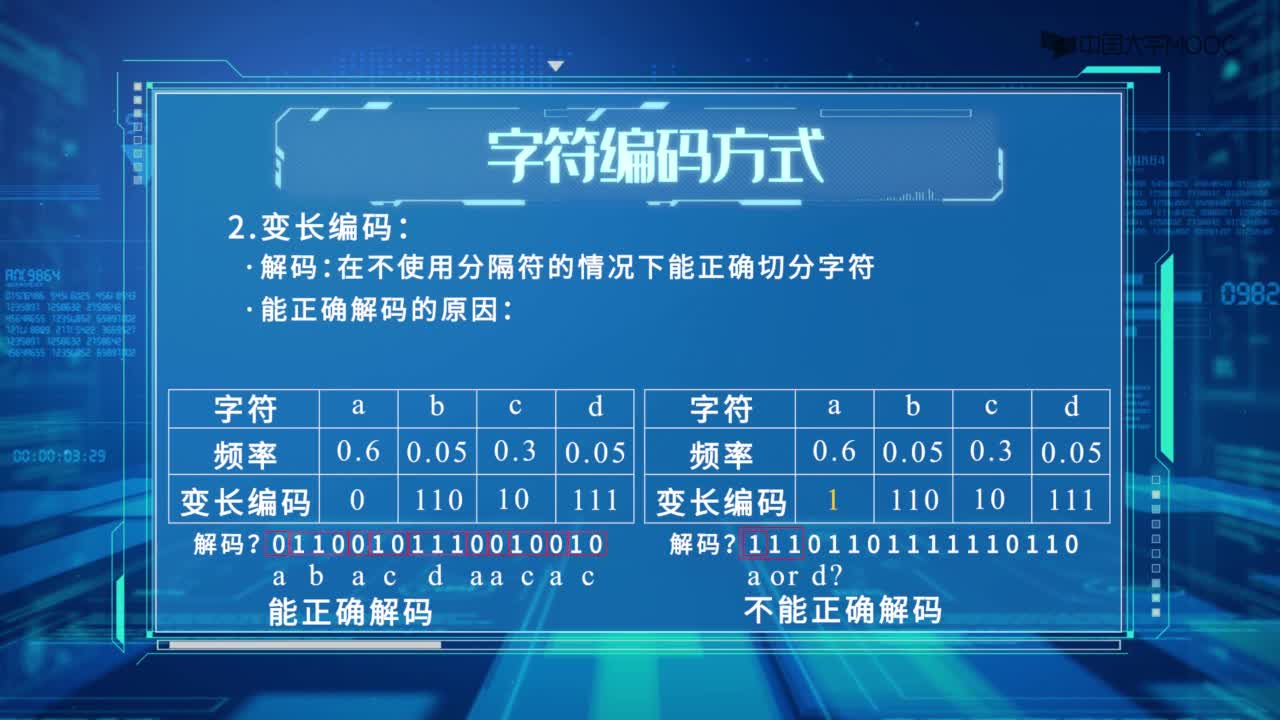
满足上述要求的二进制编码称为最优前缀编码。 上述要求的第一条是为了提高传输的速度,第二条是为了保证传输的信息在译码时无二性,所以在字符的编码中间不需要添加任意的分割符。
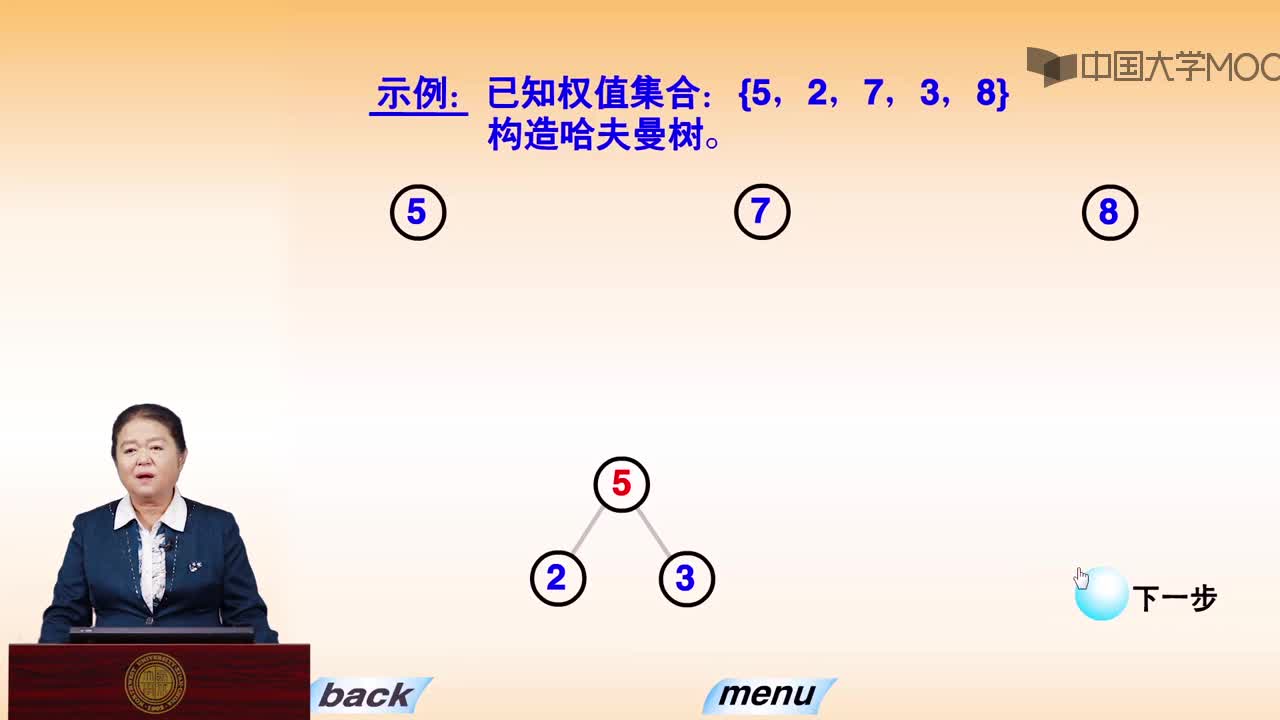
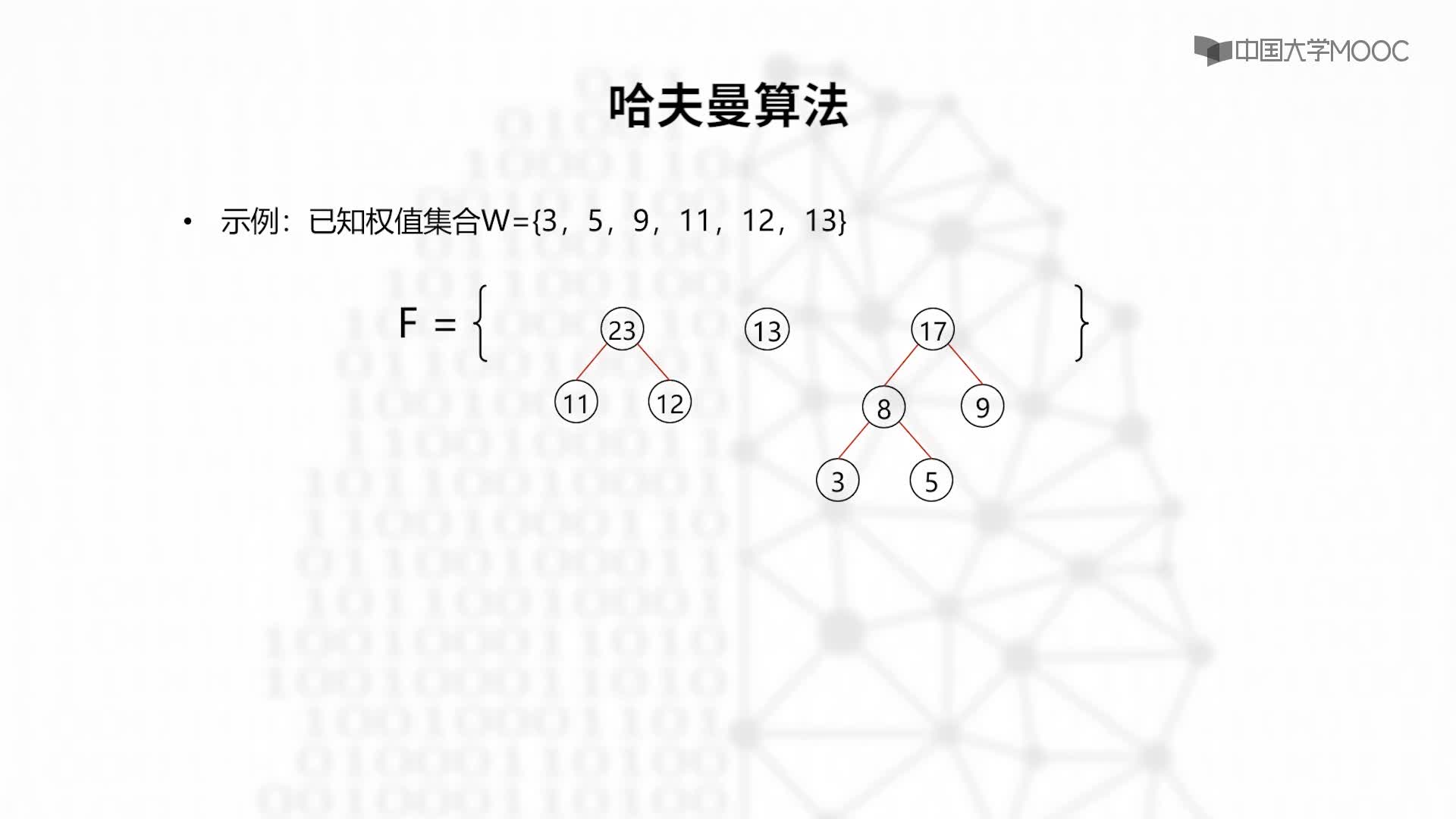
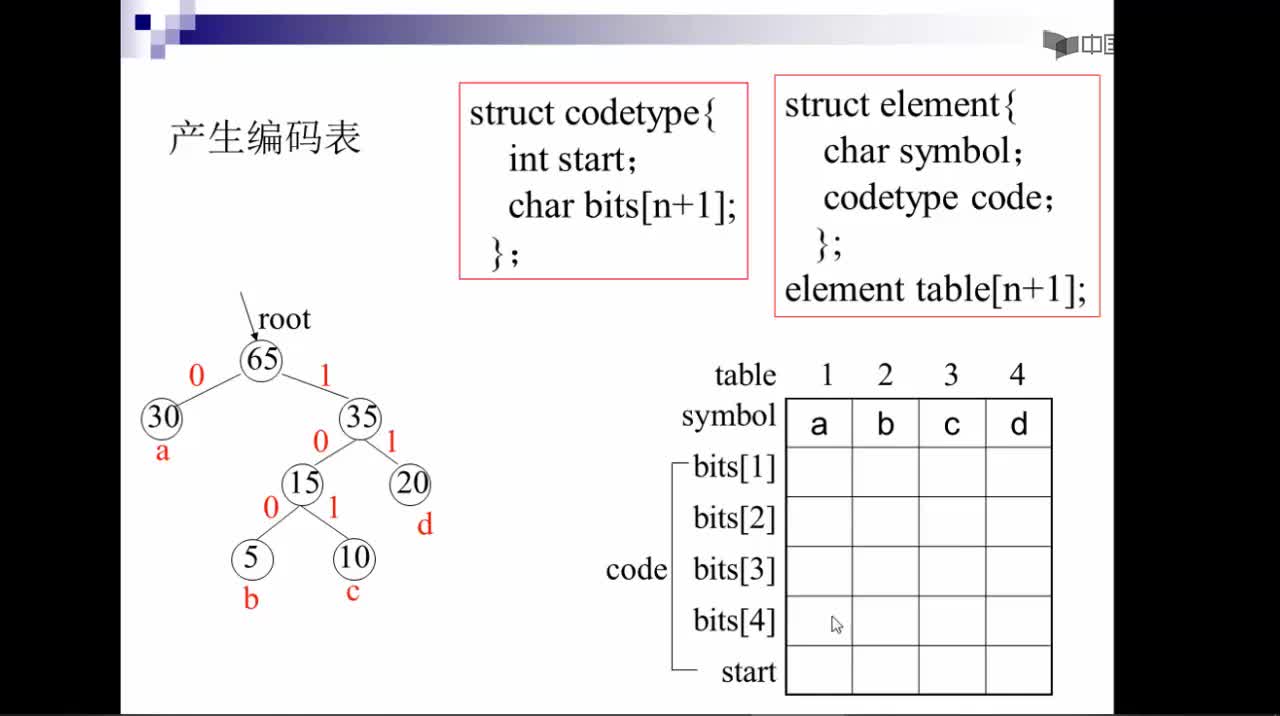
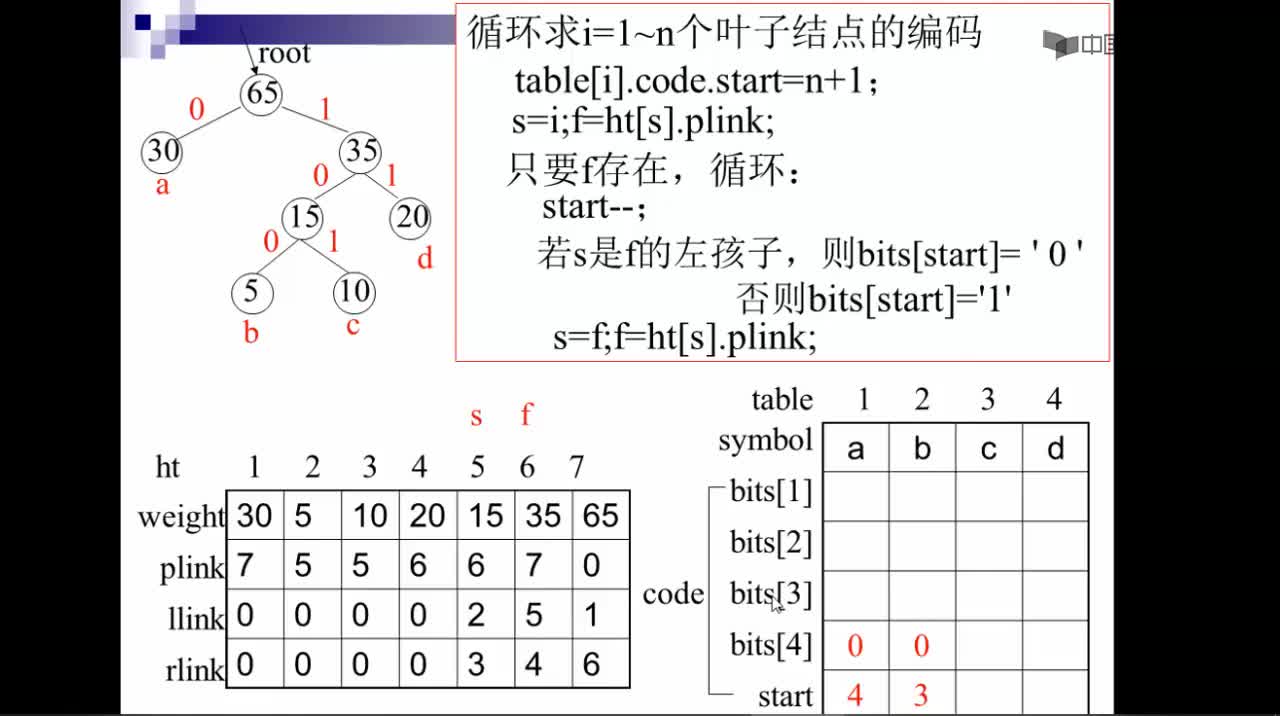
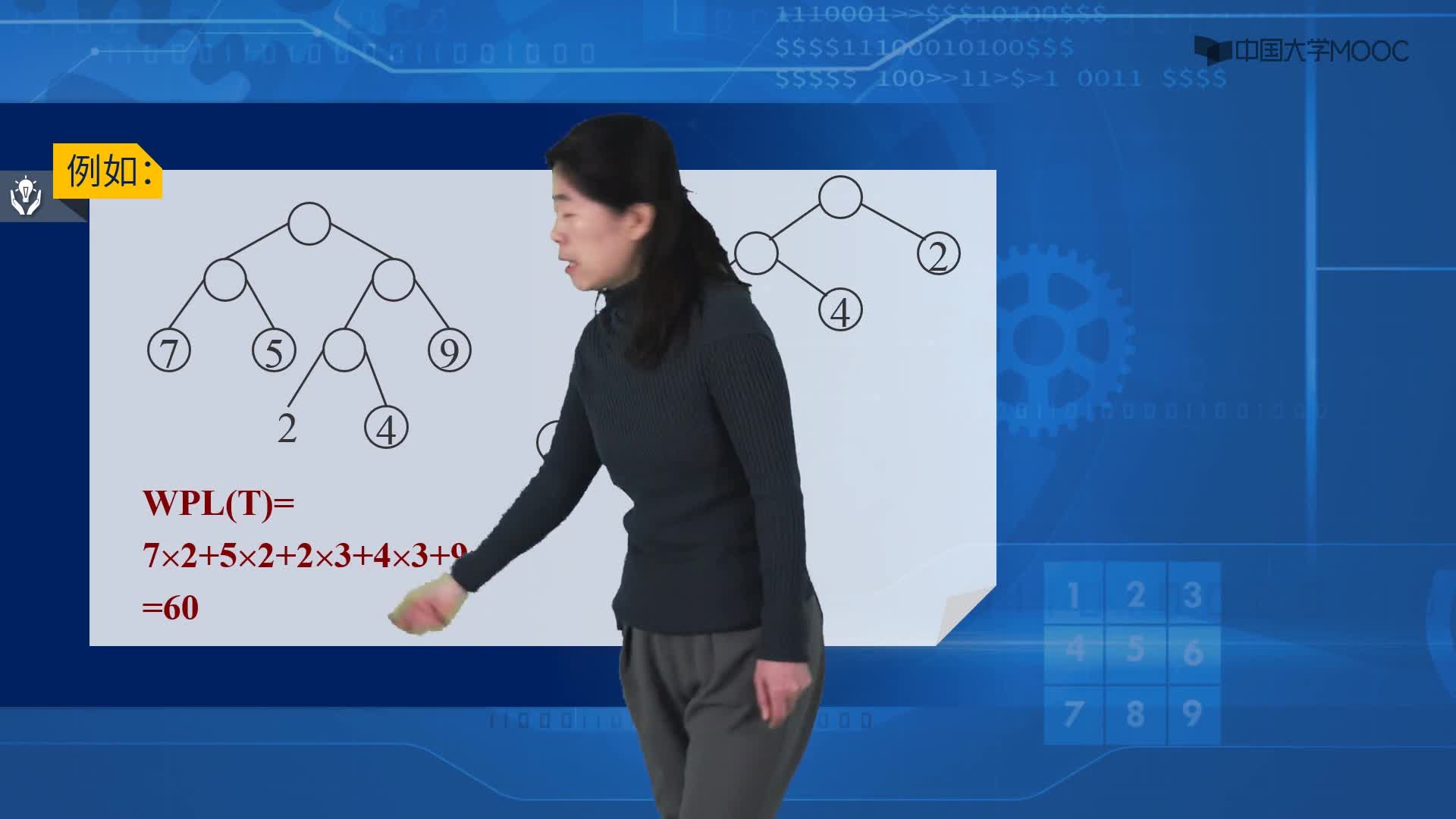
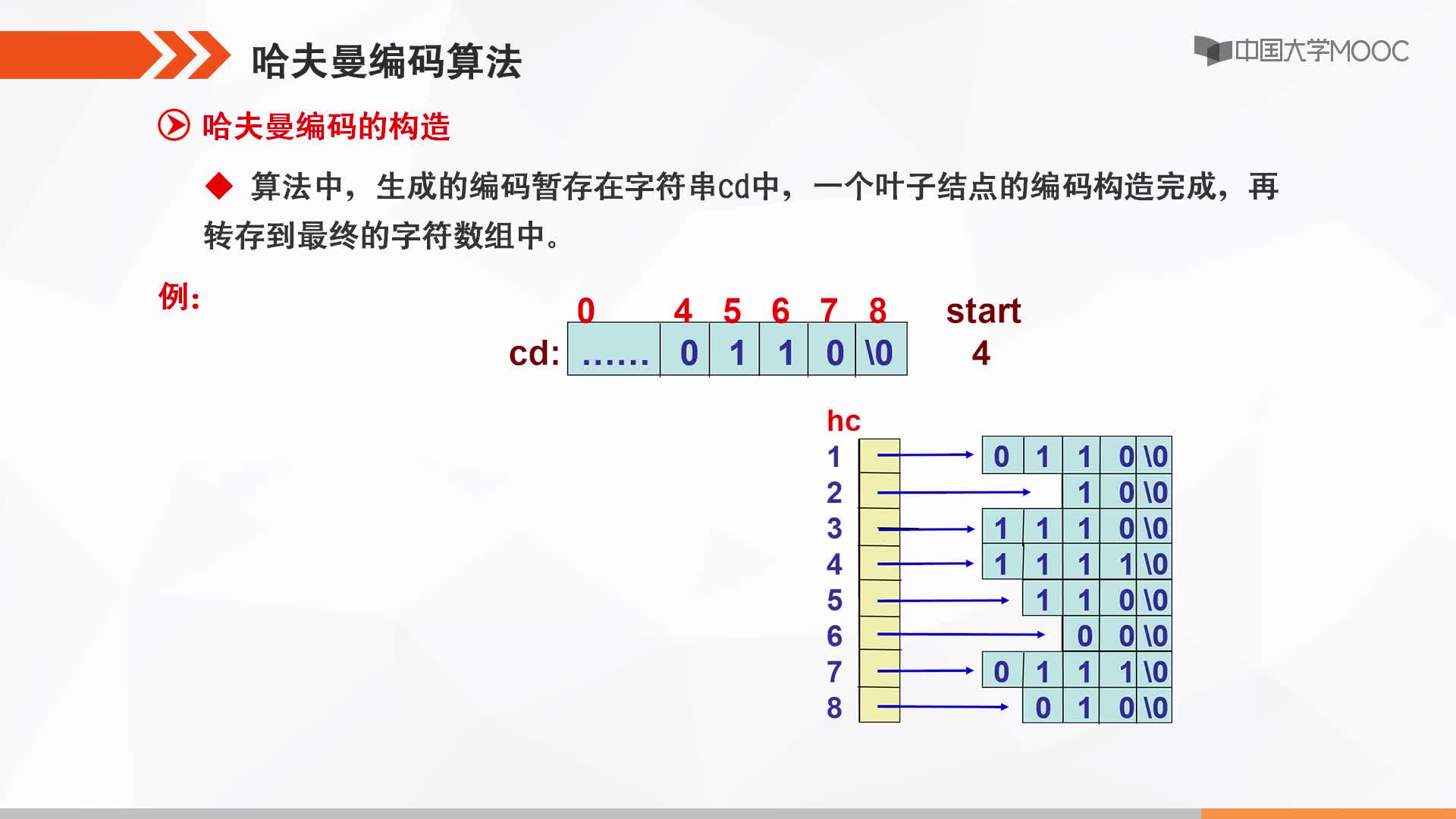
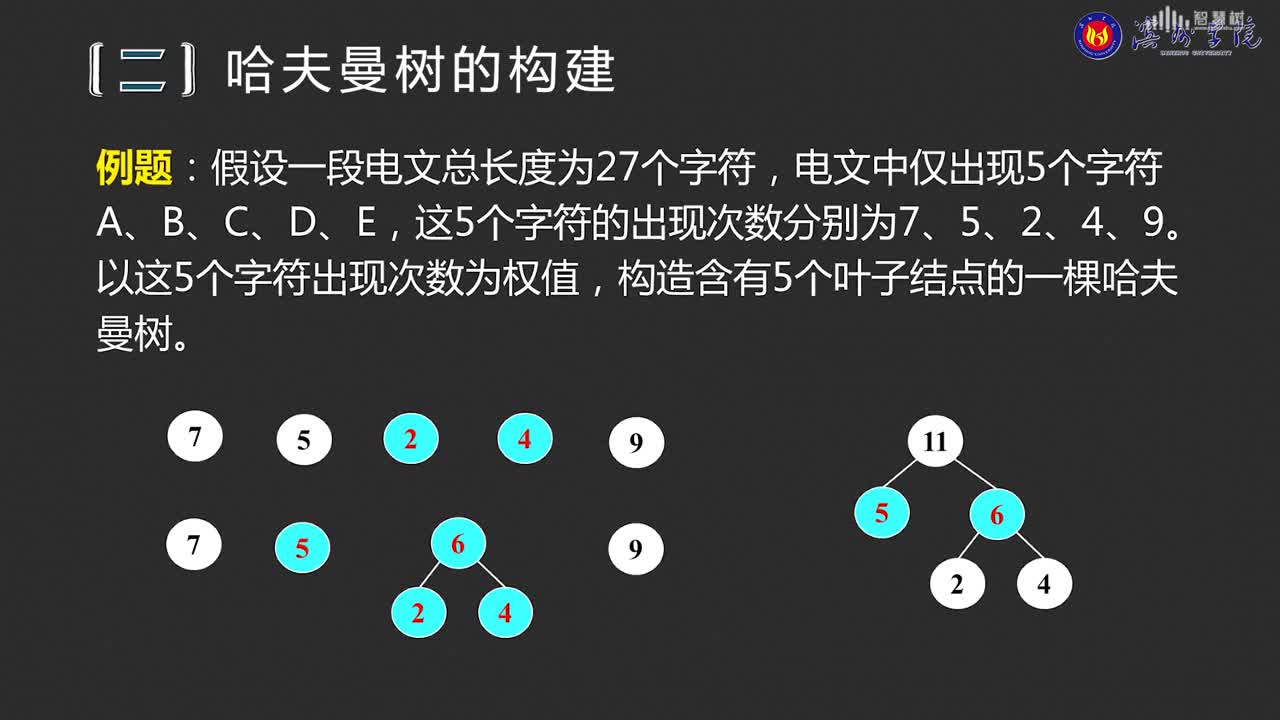
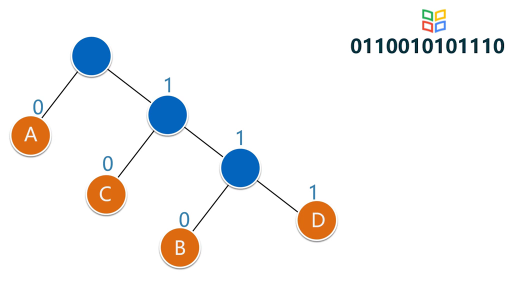
对于这个问题,可以利用哈夫曼树加以解决:用d1,d2,d3…dn作为外部结点,用w1,w2,w3…wn作为外部结点的权,构造哈夫曼树。在哈夫曼树中把从每个结点引向其左子结点的边标上二进制数“0”,把从每个结点引向右子节点的边标上二进制数“1”,从根到每个叶结点的路径上的二进制数连接起来,就是这个叶结点所代表字符的最优前缀编码。通常把这种编码称为哈夫曼编码。例如:
D={d1,d2,d3,d4,d5,d6,d7,d8,d9,d10,d11,d12,d13} W={2,3,5,7,11,13,17,19,23,29,31,37,41} 利用哈夫曼算法构造出如下图所示的哈夫曼树:
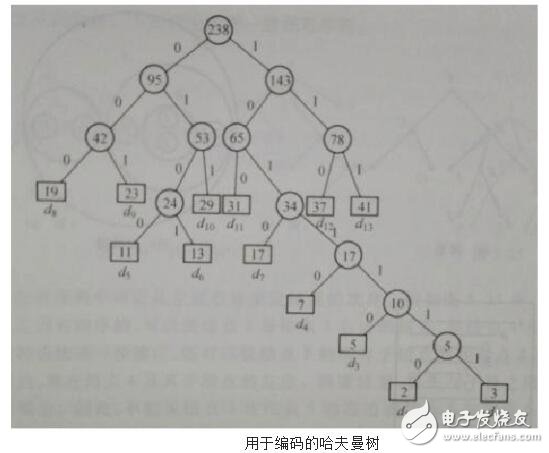
从而得到各字符的编码为:
d1:1011110 d2:1011111
d3:101110 d4:10110
d5:0100 d6:0101
d7:1010 d8:000
d9:001 d10:011
d11:100 d12:110
d13:111
编码的结果是,出现频率大的字符其编码较短,出现频率较小的字符其编码较长。























































 工商网监
工商网监
评论