 谷歌发布Translatotron语音翻译系统
谷歌发布Translatotron语音翻译系统

今天,谷歌发布Translatotron语音翻译系统,这是第一个可以直接将一个人的声音从一种语言转换成另一种语言,同时保持说话人的声音和节奏的翻译模型。
让说不同语言的人更容易地、直接地相互交流,这是语音到语音的翻译系统(Speech-to-speech translation)的目的,这样的系统在过去几十年里取得了不错的进展。
今天,谷歌发布Translatotron语音翻译系统,这是第一个可以直接将一个人的声音从一种语言转换成另一种语言,同时保持说话人的声音和节奏的翻译模型。
传统上,语音翻译系统通常有3个独立的部分:自动语音识别将源语音转录为文本,机器翻译将转录的文本翻译成目标语言,最后,文本到语音合成(TTS)系统将翻译文本转换成目标语言的语音。
许多商业语音到语音翻译的产品都采用这样的系统,包括Google Translate。但是,这类系统依赖于中间文本,准确率不高,而且效率较低。
谷歌的新工具Translatotron舍弃了将语音翻译为文本再返回语音的步骤,而是采用端到端的技术,直接将说话者的声音翻译成另一种语言。这使它能够快速地翻译,但更重要的是,能够更容易反映说话人的语调和节奏。

在论文《基于序列到序列模型的直接语音到语音翻译》(Direct speech-to-speech translation with a sequence-to-sequence model)中,谷歌的研究人员提出一种基于单个注意力序列到序列模型的直接语音到语音翻译的新实验系统,该系统不依赖于中间文本表示。
这个系统被称为Translatotron,避免了将任务划分为独立的阶段,比级联系统更有优势,包括推理速度快、自然地避免了识别和翻译之间的复合错误,能够在翻译后保留原说话者的声音,以及能够更好地处理不需要翻译的单词(如名称和专有名词)。
Translatotron:不依赖中间文本,直接翻译语音
语音翻译端到端模型的出现始于2016年,当时研究人员证明了使用单个序列到序列模型进行语音到文本翻译的可行性。2017年,我们证明了这种端到端模型可以超越级联模型(cascade models)。
最近有许多工作进一步改进了端到端语音到文本翻译模型的方法,包括同样来自谷歌的利用弱监督数据的工作(https://arxiv.org/abs/1811.02050)。
Translatotron更进一步,证明了单个序列到序列模型可以直接将一种语言的语音翻译成另一种语言的语音,而不需要像级联系统那样依赖于任何一种语言的中间文本表示。
Translatotron基于一个sequence-to-sequence网络,它将源声谱图(spectrograms)作为输入,生成目标语言翻译内容的声谱图。
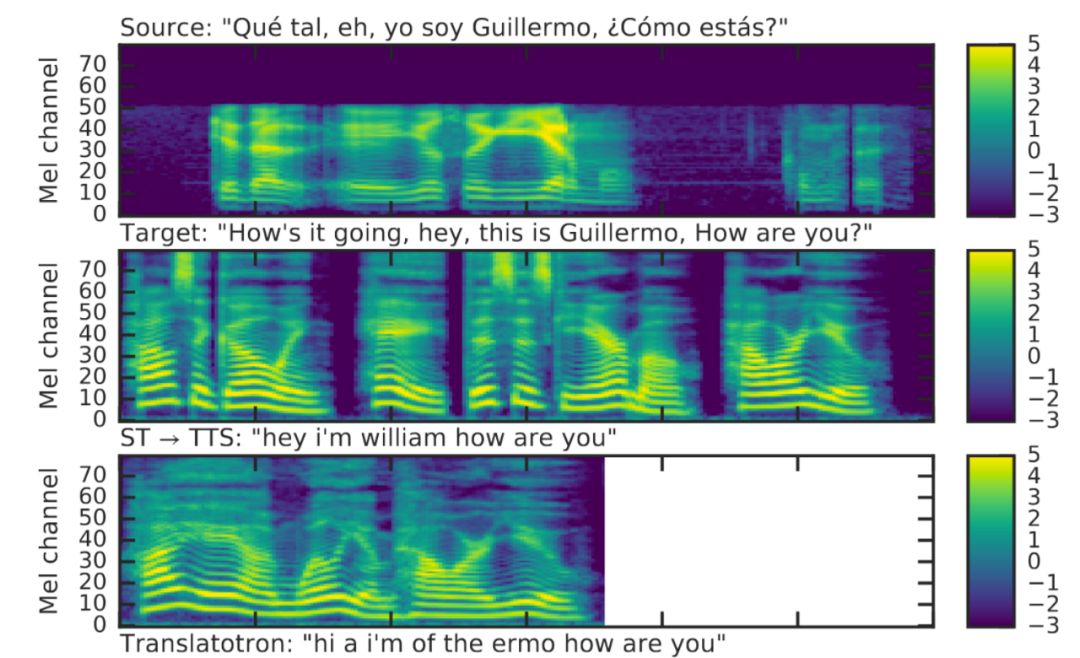
输入和生成的声谱图
此外,Translatotron还使用了另外两个单独训练的组件:一个神经声音编码器(neuralvocoder),可以将输出声谱图转换为时域波形;另外,还可以选择使用一个speaker encoder,用于在合成翻译语音时保持源speaker的语音特征。
在训练过程中,序列到序列模型使用一个多任务目标预测源和目标转录文本,同时生成目标声谱图。然而,推理过程中不需要使用转录文本或其他中间文本表示。
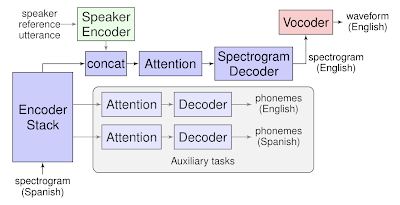
Translatotron的模型结构
性能
谷歌通过测量BLEU分数来验证Translatotron的翻译质量。该分数是通过语音识别系统转录的文本计算的。虽然结果落后于传统的级联系统,但已经证明了端到端直接语音到语音转换的可行性。
对比Translatotron到基线级联方法的直接语音到语音翻译输出,在这种情况下,两个系统都提供合适的翻译并使用相同的规范语音很自然的说话。
保持声音特征
通过结合扬声器编码器网络,Translatotron还能够在翻译的语音中,保留原始说话者的声音特征,这使得翻译的语音听起来更自然,不那么刺耳。
此功能利用了之前针对TTS的演讲者验证和演讲者调整的Google研究。扬声器编码器在演讲者验证任务上进行预训练,学习从简短的示例话语对扬声器特性进行编码。在该编码上调节频谱图解码器,即使内容是在不同的语言中,也可以合成具有类似扬声器特性的语音。
谷歌提供了诸多使用示例,如下面的例子,Translatotron将西班牙语对话转换为英语,下面的音频分别是西班牙语输入、真人参考翻译,以及Translatotron的翻译。
(由于微信智能插入一个音频,请点击原文链接听更多语音。)
Translatotron的翻译:
更多示例:
https://google-research.github.io/lingvo-lab/translatotron/#conversational
在这个例子中,Translatotron提供比基线级联模型更准确的平移,同时能够保留原始说话者的声音特征。保留原始说话者声音的Translatotron输出训练的数据,少于使用规范声音的数据,因此它们产生的翻译略有不同。
结论
谷歌声称,Translatotron是第一个可以直接将一种语言的语音,翻译成另一种语言的语音的端到端模型。它还能够在翻译的语音中保留源说话者的声音。谷歌希望这项工作可以作为未来端到端语音转语音翻译系统研究的起点。
-
编码器
+关注
关注
45文章
4026浏览量
143751 -
谷歌
+关注
关注
27文章
6271浏览量
112197 -
语音
+关注
关注
3文章
408浏览量
40152
原文标题:同声传译被攻陷!谷歌发布Translatotron直接语音翻译系统
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
谷歌发布第八代TPU,训练推理分离,搭载自研CPU

谷歌发布Gemini for Science
谷歌正式发布Gemini Spark
谷歌正抢先布局移动端AI
谷歌发布安卓17+Gemini Intelligence
亮亮视野联合智谱AI推出AR+AI会议翻译系统
谷歌推出TranslateGemma全新开放翻译模型系列

芯知识|语音芯片是如何让机器“开口说话”的?

视美泰发布AI即时翻译机解决方案,硬核配置+多语种覆盖破解跨语言沟通难题

语音识别系统的技术核心:从声音到文字的智能转换
声智科技出席2025年北京市多语种AI语音翻译大赛
广和通发布自研端侧语音识别大模型FiboASR
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程




评论