 用PaddleNLP在4060单卡上实践大模型预训练技术
用PaddleNLP在4060单卡上实践大模型预训练技术

作者:算力魔方创始人/英特尔创新大使刘力
之前我们分享了《从零开始训练一个大语言模型需要投资多少钱》,其中高昂的预训练费用让许多对大模型预训练技术感兴趣的朋友望而却步。
应广大读者的需求,本文将手把手教您如何在单张消费级显卡上,利用PaddleNLP实践OpenAI的GPT-2模型的预训练。GPT-2的预训练关键技术与流程与GPT-4等大参数模型如出一辙,通过亲手实践GPT-2的预训练过程,您就能对GPT-4的预训练技术有更深入的了解。
视频链接如下:
[零基础]:用PaddleNLP在4060单卡上实践大模型预训练技术 (qq.com)
一,GPT-2模型简介
GPT-2(Generative Pre-trained Transformer 2)是由OpenAI在2019年发布的第二代生成式预训练语言模型,通过无监督学习的方式进行预训练,能够在多个自然语言处理任务上取得显著的效果,如文本生成、阅读理解、机器翻译等。
GPT-2 奠定的技术基础为 GPT-3、GPT-4 的发展提供了方向,后续版本在此基础上不断改进和创新。
GPT-2有4个参数版本:124M、355M、774M和1.5B。为方便大家使用单卡实践预训练技术,本文选用124M版本。
二,PaddleNLP简介
PaddleNLP是一款基于飞桨的开源大语言模型(LLM)开发套件,支持在多种硬件上进行高效的大模型训练、无损压缩以及高性能推理。PaddleNLP具备简单易用和性能极致的特点,致力于助力开发者实现高效的大模型产业级应用。
代码仓:https://github.com/PaddlePaddle/PaddleNLP

三,预训练环境准备
本文的软硬件环境如下:
操作系统:Ubuntu 24.04 LTS
GPU:NVIDIA RTX-4060
代码编辑器:VS Code
Python虚拟环境管理器:Anaconda
大语言模型训练工具:PaddleNLP
大语言模型:GPT-2
在Ubuntu 24.04上安装RTX-4060驱动和Anaconda请参见这里;若您习惯在Windows上从事日常工作,请先配置《在Windows用远程桌面访问Ubuntu 24.04.1 LTS》。
四,安装PaddleNLP
首先,请用Anaconda创建虚拟环境“gpt2”:
# 创建名为my_paddlenlp的环境,指定Python版本为3.9或3.10 conda create -n gpt2 python=3.10 # 激活环境 conda activate gpt2
然后,克隆PaddleNLP代码仓到本地,切换到“develop”分支后安装PaddleNLP。
# 克隆PaddleNLP代码仓到本地 git clone https://github.com/PaddlePaddle/PaddleNLP.git cd PaddleNLP # 切换到”develop”分支 git checkout develop # 安装飞桨框架 pip install paddlepaddle-gpu # 安装PaddleNLP pip setup.py install
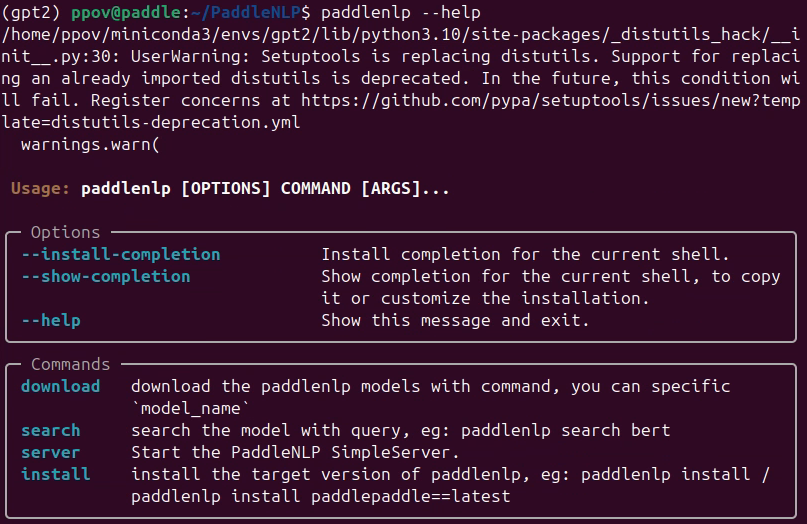
输入命令:“paddlenlp --help”,出现下图,说明PaddleNLP安装成功!
五,下载预训练数据集
为了方便读者运行快速体验预训练过程,PaddleNLP提供了处理好的100K条openweb数据集的训练样本。该训练数据集虽然不够预训练的数据量要求(模型参数量的十倍以上),但足够让读者观察到启动预训练后,随机初始化权重的GPT-2模型的Loss值从11.x左右下降到5.x左右。
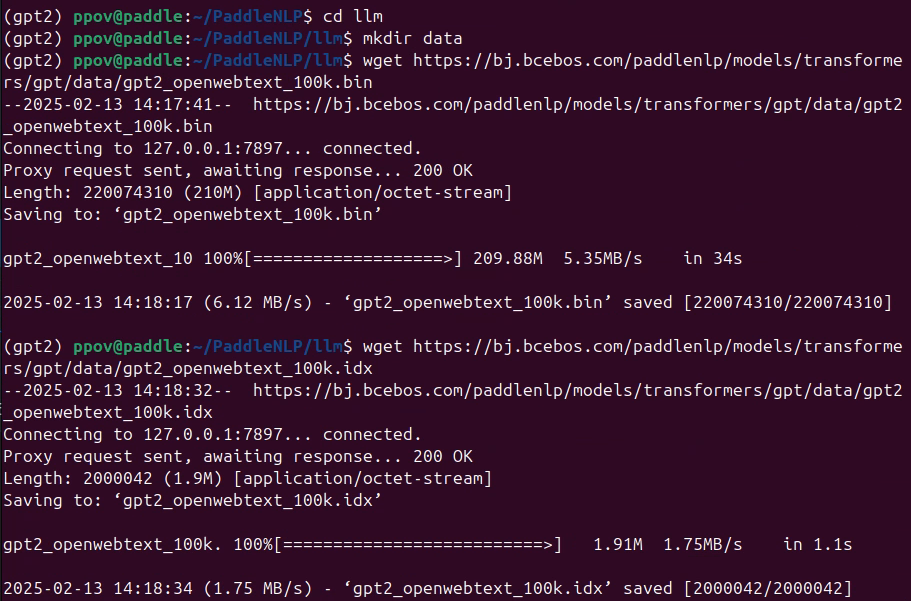
用命令将100K条openweb数据集的训练样本下载到PaddleNLP/llm/data文件夹:
cd PaddleNLP/llm mkdir data wget https://bj.bcebos.com/paddlenlp/models/transformers/gpt/data/gpt2_openwebtext_100k.bin wget https://bj.bcebos.com/paddlenlp/models/transformers/gpt/data/gpt2_openwebtext_100k.idx mv gpt2_openwebtext_100k.bin ./data mv gpt2_openwebtext_100k.idx ./data
六,下载GPT-2模型和分词器到本地
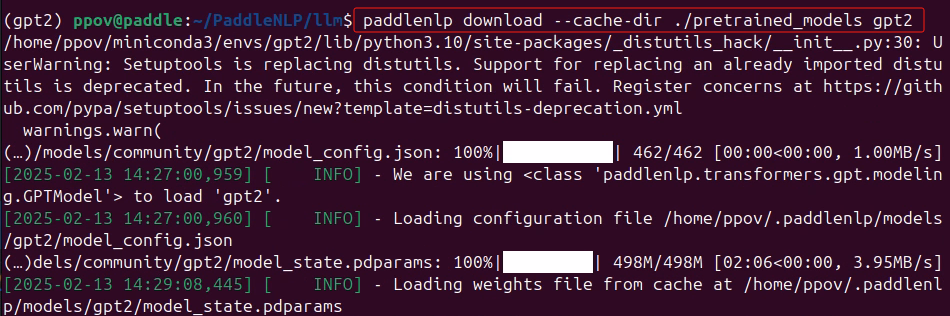
在/llm路径下,输入命令下载GPT-2模型和分词器到本地:
paddlenlp download --cache-dir ./pretrained_models gpt2
然后,打开llm/config/gpt3/pretrain_argument.json文件,按照下图修改:
"model_name_or_path": "./pretrained_models/gpt2"
"tokenizer_name_or_path": "./pretrained_models/gpt2"
七,启动GPT-2模型的预训练
在/llm路径下,输入命令:
python -u -m paddle.distributed.launch --gpus "0" run_pretrain.py
./config/gpt-3/pretrain_argument.json
--use_flash_attention False
--continue_training 0
训练结果如下图所示:
八,总结
使用PaddleNLP,可以在单张4060显卡上实践OpenAI的GPT-2模型的预训练,让自己对GPT-4的预训练技术有更深入的了解!
更多大模型训练技术,
请参看:https://paddlenlp.readthedocs.io/
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
-
数据集
+关注
关注
4文章
1242浏览量
26323 -
大模型
+关注
关注
2文章
3895浏览量
5322 -
LLM
+关注
关注
1文章
352浏览量
1432
发布评论请先 登录
【大语言模型:原理与工程实践】核心技术综述
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】大语言模型的预训练
为什么要使用预训练模型?8种优秀预训练模型大盘点

Multilingual多语言预训练语言模型的套路
如何更高效地使用预训练语言模型
利用视觉语言模型对检测器进行预训练
预训练数据大小对于预训练模型的影响
预训练模型的基本原理和应用
用PaddleNLP为GPT-2模型制作FineWeb二进制预训练数据集




评论