 自然语言生成的演变史
自然语言生成的演变史

摘要:自科幻电影诞生以来,社会一直对人工智能着迷。
每当我们听到“AI”一词时,我们的第一个想法通常是电影中的未来机器人,如终结者和黑客帝国。尽管我们距离可以自己思考的机器人还有几年的时间,但在过去几年中,机器学习和自然语言理解领域已经取得了重大进展。 个人助理(Siri / Alexa),聊天机器人和问答机器人a等应用程序真正彻底改变了我们与机器和开展日常生活的方式。自然语言理解(NLU)和自然语言生成(NLG)是人工智能发展最快的应用之一,因为人们越来越需要理解和从语言中获得意义,其中含有大量含糊不清的结构。 根据Gartner的说法,“到2019年,自然语言生成将成为90%的现代BI和分析平台的标准功能”。 在这篇文章中,我们将讨论NLG成立初期的简短历史,以及它在未来几年的发展方向。
什么是自然语言生成
语言生成的目标是通过预测句子中的下一个单词来传达信息。 可以通过使用语言模型来解决。语言模型是对词序列的概率分布。 语言模型可以在字符级别,短语级别,句子级别甚至段落级别构建。 例如,为了预测“我需要学习如何___”之后出现的下一个单词,模型为下一个可能的单词分配概率,这些单词可以是“写作”,“开车”等。神经网络的最新进展如RNN和LSTM允许处理长句,显着提高语言模型的准确性。
马尔可夫链
马尔可夫链是最早用于语言生成的算法之一。 它通过使用当前单词来预测句子中的下一个单词。 例如,如果模型仅使用以下句子进行训练:“我早上喝咖啡”和“我吃三明治加茶”。 有100%的可能性预测“咖啡”跟随“饮酒”,而“我”有50%的机会跟着“喝”,50%跟随“吃”。 马尔可夫链考虑每个独特单词之间的关系来计算下一个单词的概率。 它们在早期版本的智能手机键盘中使用,为句子中的下一个单词生成建议。
递归神经网络(RNN)
神经网络是受人类大脑运作启发的模型,通过建模输入和输出之间的非线性关系提供另一种计算方法 - 它们用于语言建模被称为神经语言建模。
RNN是一种可以利用输入的顺序性质的神经网络。 它通过前馈网络传递序列的每个项目,并将模型的输出作为序列中下一项的输入,允许存储前面步骤中的信息。 RNN拥有的“记忆”使它们非常适合语言生成,因为它们可以随时记住对话的背景。 RNN与马尔可夫链不同,因为它会查看先前看到的单词来进行预测。
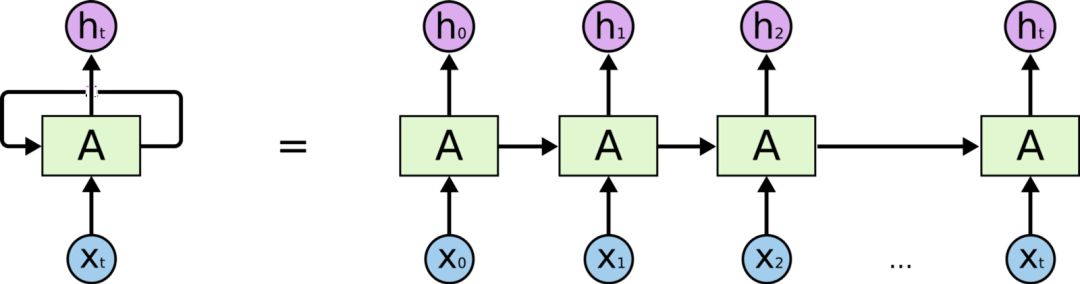
用于语言生成的RNN
在RNN的每次迭代中,模型在其存储器中存储遇到的先前单词并计算下一单词的概率。 例如,如果模型生成了文本“我们需要租用___”,那么它现在必须弄清楚句子中的下一个单词。 对于字典中的每个单词,模型根据它看到的前一个单词分配概率。 在我们的例子中,“house”或“car”这个词比“river”或“dinner”这样的词有更高的概率。 选择具有最高概率的单词并将其存储在存储器中,然后模型继续进行下一次迭代。
RNN受到梯度消失的限制。 随着序列的长度增加,RNN不能存储在句子中远处遇到的单词,并且仅基于最近的单词进行预测。 这限制了RNN用于产生听起来连贯的长句子的应用。
LSTM
基于LSTM的神经网络是RNN的变体,旨在更准确地处理输入序列中的长程依赖性。 LSTM具有与RNN类似的链式结构; 然而,它们包括四层神经网络而不是RNN的单层网络。 LSTM由4个部分组成:单元,输入门,输出门和忘记门。 这些允许RNN通过调节单元的信息流来记住或忘记任意时间间隔的单词。
考虑以下句子作为模型的输入:“我来自西班牙。我精通____。“为了正确预测下一个单词为”西班牙语“,该模型在前面的句子中侧重于”西班牙“一词,并使用单元格的记忆”记住“它。该信息在处理序列时由单元存储,然后在预测下一个字时使用。当遇到句号时,遗忘门意识到句子的上下文可能有变化,并且可以忽略当前的单元状态信息。这允许网络选择性地仅跟踪相关信息,同时还最小化消失的梯度问题,这允许模型在更长的时间段内记住信息。
LSTM及其变体似乎是消除渐变以产生连贯句子的问题的答案。然而,由于仍存在从先前单元到当前单元的复杂顺序路径,因此可以节省多少信息存在限制。这将LSTM记忆的序列长度限制为几百个单词。另一个缺陷是LSTM由于高计算要求而非常难以训练。由于它们的顺序性,它们难以并行化,限制了它们利用诸如GPU和TPU之类的现代计算设备的能力。
Transformer
Transformer最初是在2017年Google论文“Attention is all you need”中引入的,它提出了一种称为“自注意力机制”的新方法。变形金刚目前正在各种NLP任务中使用,例如语言建模,机器翻译和文本生成。变换器由一堆编码器组成,用于处理任意长度的输入和另一堆解码器,以输出生成的句子。
与LSTM相比,Transformer仅执行小的,恒定数量的步骤,同时应用自注意力机制,该机制直接模拟句子中所有单词之间的关系,而不管它们各自的位置如何。当模型处理输入序列中的每个单词时,自注意力允许模型查看输入序列的其他相关部分以更好地编码单词。它使用多个注意头,扩展了模型聚焦在不同位置的能力,无论它们在序列中的距离如何。
最近,对普通Transformer架构进行了一些改进,显着提高了它们的速度和精度。在2018年,谷歌发布了一篇关于变形金刚双向编码器表示的论文(BERT),该论文为各种NLP任务提供了最先进的结果。同样,在2019年,OpenAI发布了一个基于变换器的语言模型,其中包含大约15亿个参数,只需几行输入文本即可生成长篇连贯的文章。
用于语言生成的Transformer
最近,Transformer也被用于语言生成。 用于语言生成的Transformer最着名的例子之一是OpenAI,他们的GPT-2语言模型。 该模型通过使用注意力集中于先前在模型中看到的与预测下一个单词相关的单词来学习预测句子中的下一个单词。
使用变形金刚生成文本的基础与机器翻译所遵循的结构类似。如果我们采用一个例句“她的礼服有粉红色,白色和___点。”该模型将预测蓝色,通过使用自注意力分析列表中的前一个单词作为颜色(白色和粉红色)并理解期望的词也需要是一种颜色。自我关注允许模型选择性地关注每个单词的句子的不同部分,而不是仅仅记住循环块(在RNN和LSTM中)的一些特征,这些特征通常不会用于几个块。这有助于模型回忆起前一句的更多特征,并导致更准确和连贯的预测。与以前的模型不同,Transformer可以在上下文中使用所有单词的表示,而无需将所有信息压缩为单个固定长度表示。这种架构允许变换器在更长的句子中保留信息,而不会显着增加计算要求。它们在跨域的性能也优于以前的模型,无需特定领域的修改。
语言生成的未来
在这篇博客中,我们看到了语言生成的演变,从使用简单的马尔可夫链生成句子到使用自我注意模型生成更长距离的连贯文本。然而,我们正处于生成语言建模的曙光,而变形金刚只是向真正自主文本生成方向迈出的一步。还针对其他类型的内容(例如图像,视频和音频)开发了生成模型。这开启了将这些模型与生成文本模型集成的可能性,以开发具有音频/视觉界面的高级个人助理。
然而,作为一个社会,我们需要谨慎对待生成模型的应用,因为它们为生成假新闻,虚假评论和在线冒充人们开辟了多种可能性。 OpenAI决定拒绝发布他们的GPT-2语言模型,因为它可能被误用,这证明了我们现在已经进入了一个语言模型足够引起关注的时代。
生成模型有可能改变我们的生活;然而,它们是一把双刃剑。通过对这些模型进行适当的审查,无论是通过研究界还是政府法规,未来几年在这一领域肯定会取得更多进展。无论结果如何,都应该有激动人心的时刻!
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
-
AI
+关注
关注
91文章
41103浏览量
302585 -
人工智能
+关注
关注
1820文章
50324浏览量
266932 -
机器
+关注
关注
0文章
800浏览量
41938
原文标题:自然语言生成的演变史
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Moku:Delta输入带宽扩展至 6 GHz,多仪器并行模式支持更多插槽更高采样率

融合多场耦合效应:生成式人工智能技术演进及其在航空发动机复杂工程系统中的赋能机制研究

自然语言处理NLP的概念和工作原理

openDACS 2025 开源EDA与芯片赛项 赛题七:基于大模型的生成式原理图设计
云知声论文入选自然语言处理顶会EMNLP 2025

不只有AI协作编程(Vibe Coding):生成式系统级芯片(GenSoC)将如何把生成式设计推向硬件层面
HarmonyOSAI编程自然语言代码生成
北斗生态环境监测站:读懂自然的 “语言”

HarmonyOSAI编程页面生成
【HZ-T536开发板免费体验】5- 无需死记 Linux 命令!用 CangjieMagic 在 HZ-T536 开发板上搭建 MCP 服务器,自然语言轻松控板
HarmonyOSAI编程编辑区代码生成
HarmonyOS AI辅助编程工具(CodeGenie)页面生成
各大厂商与新兴企业推出的 EDA Copilot 工具
云知声四篇论文入选自然语言处理顶会ACL 2025

小白学大模型:从零实现 LLM语言模型




评论