 Facebook发布全卷积神经网络语音识别模型,开源语音处理深度学习工具包
Facebook发布全卷积神经网络语音识别模型,开源语音处理深度学习工具包

在语音识别领域先进的神经网络一般使用rnn来构建声学或者语言模型,并基于特征抽取的方式来进行抽取梅尔滤波器特征或者倒谱系数。但在最近的研究工作中,Facebook的研究人员提出了完全基于卷积神经网络的全卷积语音识别模型,充分利用了在声学模型和语言模型方面的最新进展。这一全卷积神经网络通过端到端的训练可以直接从原始波形预测出语言字符,移除了特征抽取的过程。同时利用一个外部的卷积语言模型来进行单词解码。这一模型在多个数据集上都取得了优异的表现。
模型
整个模型由四部分组成,分别是卷积前端、声学模型、语言模型和集束搜索的解码器(Beam-search)组成,如下图所示。
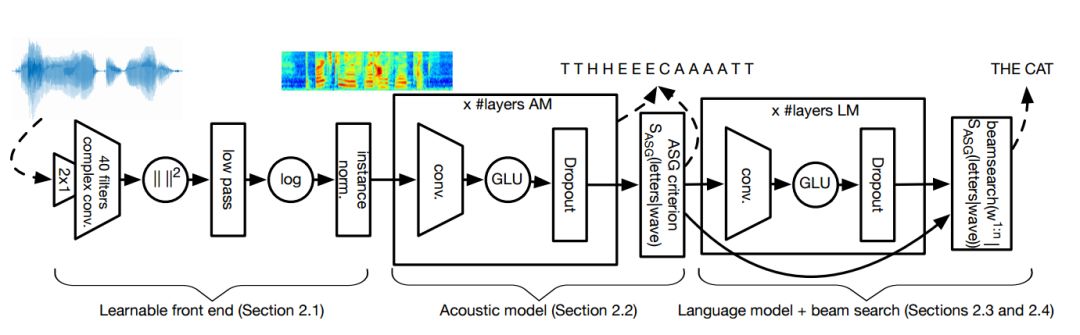
在可学习的前端中,原始音频首先输入到一个宽度为2的卷积中,用于模仿梅尔滤波器特征中的前处理步骤。随后应用了宽度为25ms的k复卷积滤波器。随后利用平方取绝对值并通过低通滤波器,其宽度为25ms步长为10ms。最后利用对数压缩,并对每个通道进行了均方归一化。紧随其后的是声学模型,包含了线性门的卷积神经网络,同时使用了dropout来实现正则化。这一模型的目的在于直接预测出字母。在随后的语言模型中,研究人员利用了GCNN-14B,其中包含了14个卷积残差模块和逐渐增长的通道数,并利用了线性门控单元作为激活函数。语言模型的主要目的在于为备选的句子输出打分,这一模型允许更大的上下文。最后,基于集束搜索的解码器用于生成最合适的句子输出。
其工作的过程在于最大化上面的表达式。
工具
这一模型的实现使用了Facebook最新开源的两个工具:其中使用了wav2letter建立声学模型,fairseq建立了语言模型。
fairseq 原理图
同时推出的升级版深度学习自动语音识别工具框架wav2letter++,在之前wav2letter的基础上进行和很多的改进和优化。

wav2letter++ 工具包架构
这一版的工具箱由C++实现,并利用了ArrayFire张量库来提高了运算效率。研究团队表示,在某些情况下wav2letter++在训练端到端的语音识别神经网络时将提速2倍。

wav2letter++ 与其他语言工具的性能比较
端到端的语音识别使得其在多语言上的大规模应用变得可行。同时直接从原始音频上进行学习可以充分发挥高质量音频的效果。端到端的算法加上高效的工具框架,将有效促进这一领域的研究,希望全卷积神经网络的语音识别和wav2letter工具为小伙伴们的研究带来新的帮助。
-
神经网络
+关注
关注
42文章
4842浏览量
108188 -
Facebook
+关注
关注
3文章
1432浏览量
59361 -
深度学习
+关注
关注
73文章
5608浏览量
124637
原文标题:新模型、新工具,Facebook在语音识别领域的新动作!
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
卷积神经网络如何让自动驾驶识别障碍物?

面向嵌入式部署的神经网络优化:模型压缩深度解析

【新品发布】艾为重磅发布端侧AI高性能NPU语音芯片,打造智能语音体验新标杆


自动驾驶中常提的卷积神经网络是个啥?

CNN卷积神经网络设计原理及在MCU200T上仿真测试
构建CNN网络模型并优化的一般化建议
CICC2033神经网络部署相关操作
如何在机器视觉中部署深度学习神经网络

基于开源鸿蒙的语音识别及语音合成应用开发样例
广和通发布自研端侧语音识别大模型FiboASR
明远智睿SSD2351开发板:语音机器人领域的变革力量
AI神经网络降噪算法在语音通话产品中的应用优势与前景分析




评论