 Linux服务器磁盘管理机制和清理策略
Linux服务器磁盘管理机制和清理策略

背景与问题
磁盘空间耗尽是服务器运维中最常见的问题之一。当磁盘写满后,应用无法写入日志、无法创建新文件、无法写入数据、数据库无法完成刷盘、SSH 可能无法建立新连接。表现为:写入文件报 "No space left on device"、日志停止写入、服务开始报无法连接、SSH 登录后无法执行命令。
磁盘满的问题排查难度在于:空间被谁占用是不直观的,特别是当日志文件被删除但进程仍持有文件描述符时。清理磁盘空间也不是简单地删除文件,需要理解哪些文件可以删、哪些正在被使用、删除后影响是什么。
本文以 RHEL 9、AlmaLinux 9、Ubuntu 22.04 LTS 为测试环境,系统讲解 Linux 磁盘管理机制、空间占用分析方法、常见占用来源、清理策略、以及预防措施。涵盖文件系统和 LVM 两个维度,覆盖日志文件、数据库文件、临时文件、缓存文件等常见场景。
1. 磁盘空间基础概念
1.1 磁盘空间相关概念
Linux 中与磁盘空间相关的几个关键概念:
文件系统空间(Filesystem level):文件系统层面的可用空间,通过 df 命令查看。这是应用能直接使用的空间。
逻辑卷空间( LVM level ):如果使用 LVM 管理磁盘,逻辑卷的空间可能小于物理卷,或者逻辑卷已经扩展但文件系统未扩展。
物理磁盘空间(Physical disk level):硬盘分区的实际大小,与分区表和 RAID 配置相关。
inode 数量:文件系统不仅限制空间使用,还限制 inode 数量。inode 是存储文件元数据的结构,inode 耗尽时即使有空间也无法创建新文件。
block 大小:文件系统的最小分配单元,通常是 4KB。写入 1 字节的文件也会占用 4KB 空间,这是小文件多时磁盘占用虚高的原因之一。
1.2 查看磁盘空间状态
# 查看所有文件系统的空间使用情况
df -h
# 查看 inode 使用情况
df -i
# 以 inode 和空间占用排序
df -i
df -h
# 查看特定目录的磁盘使用(逐层深入)
du -sh /var/*
du -h --max-depth=1 /var
# 找出大文件
find / -typef -size +100M -execls -lh {} ;
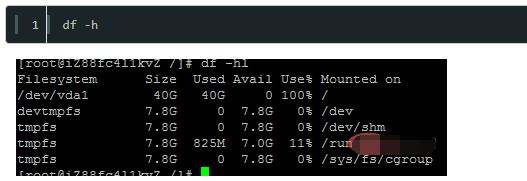
1.3 理解 df -h 输出
$ df -h Filesystem Size Used Avail Use% Mounted on tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 100G 45G 55G 45% / /dev/mapper/vg-root 200G 180G 20G 90% /data
Size:文件系统总大小
Used:已使用空间
Avail:可用空间
**Use%**:使用率
Mounted on:挂载点
当 Use% 达到 90% 以上时应该引起警惕,达到 95% 以上时必须立即处理。Avail 显示的可用空间是 root 和普通用户的可用空间之和,对所有用户一致。
2. 快速定位占用来源
2.1 分层排查法
磁盘空间占用的排查应该分层进行,从大到小逐步定位:
# 第一层:确定哪个挂载点满了 df -h # 第二层:确定哪个目录占用最多 du -sh /* du -h --max-depth=1 / | sort -hr | head -10 # 第三层:进入占用最多的目录继续排查 du -h --max-depth=1 /var du -h --max-depth=1 /var/log
2.2 快速定位大文件
当磁盘使用率达到 95% 以上时,需要快速找到可以清理的大文件:
# 查找大于 500MB 的文件
find / -typef -size +500M -execls -lh {} ; 2>/dev/null
# 查找特定目录下大于 100MB 的文件
find /var -typef -size +100M -execls -lh {} ; 2>/dev/null
# 按大小排序查看目录内容
du -ah /var | sort -rh | head -20
# 只看文件不看目录
du -ah /var | grep -v'/$'| sort -rh | head -20
2.3 查找被删除但仍被进程占用的文件
这是最容易被忽视的问题:文件被删除但进程仍持有文件描述符,导致空间无法释放:
# 方法一:查看已删除但未释放的空间 lsof +L1 # 方法二:查看所有打开文件的进程 lsof | grep deleted # 方法三:查看特定进程的打开文件 ps aux | grep process_name ls -la /proc/PID/fd | grep deleted
为什么会这样:当进程打开一个文件时,内核会为该文件分配一个文件描述符。即使在文件系统层面删除了文件,只要进程仍持有该文件描述符,文件占用的空间就不会被释放。这种情况在日志文件被 logrotate 切割后常见:logrotate 移动了日志文件,但 Nginx 或应用程序仍然写入到旧的 FD。
解决方法:重启持有文件描述符的进程;或者向进程发送 SIGUSR1(对于支持重新打开日志的进程如 Nginx)或 SIGHUP 信号。
# 对于 Nginx,重新打开日志 nginx -s reopen # 或者向 master 进程发送信号 kill-USR1 $(cat /var/run/nginx.pid) # 查看哪些文件描述符被标记为 deleted 但仍被占用 lsof +L1 | grep -v"memfd"
3. 日志文件排查与清理
3.1 日志文件空间占用分析
日志是磁盘空间消耗的大户。排查日志占用:
# 查看 /var/log 目录总大小 du -sh /var/log # 查看 /var/log 下各子目录的大小 du -h /var/log| sort -rh | head -20 # 查看具体的日志文件大小 ls -lhS /var/log/*.log # 统计各日志文件的行数 wc -l /var/log/*.log
3.2 常见日志文件说明
Linux 系统和常用服务的日志文件:
| 路径 | 内容 | 风险 |
|---|---|---|
| /var/log/messages | 系统核心日志 | 正常情况下不会过大 |
| /var/log/secure | 安全和认证日志 | 可能因 SSH 暴力破解变很大 |
| /var/log/maillog | 邮件服务日志 | 取决于邮件量 |
| /var/log/yum.log | yum 操作日志 | 通常很小 |
| /var/log/cron | 定时任务日志 | 通常很小 |
| /var/log/dmesg | 启动时的内核日志 | 由 ring buffer 决定大小 |
| /var/log/nginx/access.log | Nginx 访问日志 | 可非常大 |
| /var/log/nginx/error.log | Nginx 错误日志 | 通常不大,除非有持续错误 |
| /var/log/mysql/error.log | MySQL 错误日志 | 通常不大 |
| /var/log/mysqld.log | MySQL 通用日志 | 开启后可能很大 |
| /var/log/postgresql/postgresql-*.log | PostgreSQL 日志 | 取决于日志级别 |
| /var/log/httpd/ 或 /var/log/apache2/ | Apache 日志 | 可非常大 |
| /var/log/kern.log | 内核日志 | 通常不大 |
3.3 安全清理日志文件
清理日志文件时,不能直接用 rm 删除正在写入的文件,否则会导致进程继续占用已删除文件的空间(如前所述)。正确做法:
对于支持信号刷新日志的进程:
# Nginx:通知重新打开日志文件 nginx -s reopen # 或者发送信号 kill-USR1 $(cat /var/run/nginx.pid) # 然后删除旧日志文件 rm /var/log/nginx/access.log.1
对于不支持的进程,使用 truncate 命令清空文件内容而不删除文件:
# 清空文件内容但保留文件描述符 truncate -s 0 /var/log/nginx/access.log # 或者使用 : > 语法 : > /var/log/nginx/access.log
对于可以安全删除的文件(如已切割的旧日志):
# 删除旧的日志文件 rm /var/log/nginx/access.log.2026-04-*.gz # 删除 7 天前的日志 find /var/log-name"*.gz"-mtime +7 -delete # 删除 30 天前的日志 find /var/log-name"*.log.*"-mtime +30 -delete
3.4 日志切割配置检查
检查 logrotate 配置确保日志被正确切割:
# 查看 logrotate 配置
cat /etc/logrotate.conf
cat /etc/logrotate.d/nginx
# 示例配置
/var/log/nginx/*.log{
daily
missingok
rotate 14
compress
delaycompress
notifempty
create 0640 nginx nginx
postrotate
[ -f /var/run/nginx.pid ] &&kill-USR1 `cat /var/run/nginx.pid`
endscript
}
关键参数:
daily/weekly/monthly:切割频率
rotate N:保留 N 份历史日志
compress:压缩旧日志
delaycompress:延迟压缩,保留最近一份不压缩
notifempty:空文件不切割
postrotate/endscript:切割后执行的命令,通常是通知进程重新打开日志
手动执行 logrotate 调试:
# 强制执行一次 logrotate(加 -f 强制) logrotate -f /etc/logrotate.conf # 查看 logrotate 状态 cat /var/lib/logrotate/status # 测试配置是否正确 logrotate -d /etc/logrotate.d/nginx
4. 数据库文件空间管理
4.1 MySQL/MariaDB 空间分析
# 登录 MySQL 查看各数据库大小 mysql -e"SELECT table_schema AS 'Database', ROUND(SUM(data_length + index_length) / 1024 / 1024, 2) AS 'Size (MB)' FROM information_schema.tables GROUP BY table_schema;" # 查看各表的详细大小 mysql -e"SELECT table_schema, table_name, ROUND(data_length / 1024 / 1024, 2) AS data_mb, ROUND(index_length / 1024 / 1024, 2) AS index_mb FROM information_schema.tables ORDER BY data_length DESC LIMIT 20;" # 查看 binlog 占用空间 mysql -e"SHOW BINARY LOGS;" # 查看 innodb 文件大小 ls -lh /var/lib/mysql/*.ibd
4.2 MySQL binlog 清理
MySQL binlog 记录所有数据变更,是复制和恢复的基础,但会占用大量空间:
# 查看当前的 binlog 配置 mysql -e"SHOW VARIABLES LIKE 'expire_logs_days';" mysql -e"SHOW VARIABLES LIKE 'max_binlog_size';" # 手动删除 binlog(指定到某个 binlog 文件) mysql -e"PURGE BINARY LOGS TO 'mysql-bin.000123';" # 删除某个时间之前的 binlog mysql -e"PURGE BINARY LOGS BEFORE '2026-04-01 0000';"
重要:删除 binlog 前必须确认从库已经接收完毕,否则会导致复制中断。如果使用的是主从复制,应该在主库执行。
设置自动清理:
# 在 my.cnf 中设置 expire_logs_days = 7 max_binlog_size = 100M
4.3 PostgreSQL 空间分析
# 查看各数据库大小 psql -c"SELECT pg_database.datname, pg_size_pretty(pg_database_size(pg_database.datname)) FROM pg_database ORDER BY pg_database_size(pg_database.datname) DESC;" # 查看各表大小 psql -c"SELECT schemaname, tablename, pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) FROM pg_catalog.pg_statio_user_tables ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC LIMIT 20;" # 查看 WAL 文件占用 ls -lh$PGDATA/pg_wal/ du -sh$PGDATA/pg_wal/
4.4 PostgreSQL WAL 清理
PostgreSQL 的 WAL(Write-Ahead Log)文件是数据恢复的关键,同样会占用大量空间:
# 检查 wal 保留配置 psql -c"SHOW wal_keep_size;" psql -c"SHOW max_wal_size;" # 手动 checkpoint 并清理 WAL psql -c"CHECKPOINT;" # 设置 WAL 保留大小(在 postgresql.conf 中) wal_keep_size = 1GB max_wal_size = 2GB # 查看归档状态 psql -c"SELECT * FROM pg_stat_archiver;"
4.5 MongoDB 空间分析
# 查看数据库列表及大小
mongosh --quiet --eval"db.adminCommand('listDatabases')"| grep -E"name|sizeOnDisk"
# 查看集合大小
mongosh --quiet --eval"db.getCollectionNames().forEach(function(c){ var s=db[c].stats(); print(c + ': ' + (s.size/1024/1024).toFixed(2) + ' MB'); });"
# 查看 oplog 大小
mongosh --quiet --eval"db.oplog.rs.stats().maxSize / 1024 / 1024"
5. 临时文件和缓存清理
5.1 /tmp 目录清理
Linux 系统重启时 /tmp 通常会被清空,但长时间运行的服务器上 /tmp 可能积累大量文件:
# 查看 /tmp 大小
du -sh /tmp
# 查看 /tmp 中最占用空间的文件和目录
find /tmp -typef -execls -lh {} ; | sort -k5 -rh | head -20
# 查找过于老旧的文件(30 天未访问)
find /tmp -atime +30 -typef -ls
# 查找临时文件(按大小排序)
find /tmp -typef -printf"%s %p
"| sort -rn | head -20
5.2 系统缓存清理
Linux 会使用空闲内存做文件缓存,这些内存在需要时会被释放。不应该直接清理 pagecache,但可以 sync 确保数据落盘后手动 drop cache:
# 查看内存和缓存使用 free -h # 同步文件系统确保数据落盘 sync # 谨慎操作:手动释放 pagecache echo3 > /proc/sys/vm/drop_caches
警告:在生产环境中执行 drop_caches 可能导致性能抖动,通常只在排查问题时使用。
5.3 Yarn/NPM/Maven 等包管理器缓存
开发环境和构建服务器上,包管理器缓存可能占用大量空间:
# Yarn 缓存 yarn cache dir yarn cache clean # NPM 缓存 npm cache ls npm cache clean --force # Maven 缓存 du -sh ~/.m2/repository rm -rf ~/.m2/repository/* # PIP 缓存 du -sh ~/.cache/pip rm -rf ~/.cache/pip
5.4 Docker 资源清理
Docker 存储占用往往是最大的磁盘杀手之一:
# 查看 Docker 磁盘使用 docker system df # 详细分析各类资源 docker system df -v # 清理未使用的资源 docker system prune -a # 删除所有未使用的镜像、容器、网络 docker container prune # 删除已停止的容器 docker image prune -a # 删除未使用的镜像 docker volume prune # 删除未使用的卷 docker network prune # 删除未使用的网络 # 清理特定时间之前的资源 docker system prune --filter"until=168h"# 删除 7 天前的资源
5.5 旧内核和已卸载包清理
系统更新后旧内核会保留,可能占用数百 MB:
# 查看已安装的内核 dpkg --list | grep linux-image rpm -qa | grep kernel # Ubuntu/Debian 清理旧内核 apt-get autoremove -y # 或者使用 purge-old-kernels(如果安装了 byobu) purge-old-kernels --keep 2 # RHEL/CentOS 清理旧内核 dnf remove $(dnf repoquery --installonly --latest-limit=-2 -q) # 或者 package-cleanup --oldkernels --count=2
6. inode 耗尽问题
6.1 inode 概念
inode 是文件系统中存储文件元数据的结构,每个文件对应一个 inode。inode 耗尽时,即使磁盘有空间也无法创建新文件。
# 查看 inode 使用情况 df -i # 查看特定文件系统的 inode 数量 df -i / # 查看 inode 使用最多的目录 find / -xdev -printf'%h '| sort | uniq -c | sort -rn | head -10
6.2 大量小文件导致 inode 耗尽
常见原因:邮件队列(/var/spool/mail/)、缓存文件、Nginx 访问日志被切割成大量小文件。
# 统计目录下文件数量
find /var/spool -typef | wc -l
# 查看某个目录的文件数量分布
fordirin/var/*;doecho-n"$dir: "; ls -1A"$dir"2>/dev/null | wc -l;done
# 查找 inode 占用最高的目录
find / -xdev -typed -execsh -c'echo "$(ls -1A "$1" 2>/dev/null | wc -l) $1"'_ {} ; | sort -rn | head -10
6.3 解决 inode 耗尽
如果是邮件队列导致的:
# 查看邮件队列大小 ls -lh /var/spool/mail/ # 清理旧邮件(需要确认) find /var/spool/mail -typef -name"*"-mtime +30 -delete
创建文件系统时可以指定 inode 密度:
# 创建时指定 mkfs.ext4 -i 8192 /dev/sdb1 # 每 8KB 一个 inode
7. LVM 环境下的问题
7.1 LVM 概念回顾
LVM(Logical Volume Manager)将物理磁盘抽象为卷组(VG)和逻辑卷(LV),提供更灵活的空间管理:
PV(Physical Volume):物理卷,对应分区或整个磁盘
VG(Volume Group):卷组,多个 PV 组成
LV(Logical Volume):逻辑卷,从 VG 中划分
7.2 LVM 空间问题排查
# 查看卷组空间使用 vgdisplay # 查看逻辑卷信息 lvdisplay # 查看每个 LV 的空间使用 lvs -o lv_name,lv_size,data_percent,metadata_percent # 查看 PV 使用情况 pvs pvdisplay
7.3 扩展逻辑卷
当文件系统空间不足但 VG 有剩余空间时:
# 扩展逻辑卷 lvextend -L +10G /dev/mapper/vg-root # 扩展文件系统(ext4) resize2fs /dev/mapper/vg-root # 扩展文件系统(xfs) xfs_growfs /data
7.4 扩展卷组
当 VG 本身空间不足时,需要添加新物理卷:
# 创建新分区或磁盘 # 创建物理卷 pvcreate /dev/sdb1 # 将新 PV 加入 VG vgextend vg_name /dev/sdb1 # 扩展 LV lvextend -L +50G /dev/mapper/vg-root # 扩展文件系统 resize2fs /dev/mapper/vg-root
7.5 缩小逻辑卷(谨慎操作)
缩小逻辑卷需要先卸载文件系统,风险极高,不推荐在生产环境操作。如果必须操作:
# 卸载文件系统 umount /data # 检查文件系统 e2fsck -f /dev/mapper/vg-data # 缩小文件系统 resize2fs /dev/mapper/vg-data 50G # 缩小 LV lvreduce -L 50G /dev/mapper/vg-data # 重新挂载 mount /dev/mapper/vg-data /data
8. 分区表和文件系统修复
8.1 检查文件系统错误
在清理磁盘前,应该检查文件系统是否有错误:
# 检查文件系统(必须先卸载) umount /data e2fsck -f /dev/mapper/vg-data # 检查并修复(自动修复模式) e2fsck -p /dev/mapper/vg-data
注意:不要在已挂载的文件系统上运行 e2fsck(除非使用只读模式)。生产环境应该使用 fsck -n 预览问题。
8.2 修复损坏的 inode
如果 inode 表损坏导致空间统计不准:
# 显示 inode 使用情况 dumpe2fs /dev/sda1 | grep -E"Inode size|Inode count|Inode blocks per group|Inodes per group" # 检查损坏的 inode badblocks /dev/sda1
8.3 修复 LVM 配置损坏
如果 LVM 配置损坏导致无法访问数据:
# 扫描物理卷 pvscan # 激活所有卷组 vgchange -ay # 查看 LVM 状态 lvs -a
9. 紧急处理流程
当磁盘已满导致服务不可用时,按以下顺序处理:
第一步:登录服务器
如果 SSH 已经无法登录,尝试:
# 使用密钥登录 ssh -i ~/.ssh/id_rsa user@server # 如果是 SSH 会话仍然活跃但无法执行命令 # 尝试执行简单命令 df -h / # 如果是根目录满,需要先清理 ls -la /tmp
第二步:定位最紧急的占用
# 查看磁盘使用情况
df -h
# 查找大文件
find / -xdev -typef -size +100M -execls -lh {} ; 2>/dev/null
# 查看已删除但未释放的文件
lsof +L1
第三步:立即清理
# 清理临时文件 rm -rf /tmp/* rm -rf /var/tmp/* # 清理旧日志(如果进程支持) : > /var/log/messages : > /var/log/secure # 清理包管理器缓存 yum clean all apt-get clean all # 清理 Docker(谨慎) docker system prune -f
第四步:通知相关服务
清理完成后,应该通知相关人员日志被清空,并重启相关服务确保日志正常写入:
# 重启日志服务 systemctl restart rsyslog systemctl restart systemd-journald # 重启应用(如果需要) systemctl restart nginx systemctl restart myapp
10. 预防措施
10.1 磁盘空间监控告警
部署监控是预防磁盘满的最有效手段:
# Prometheus 告警规则示例
groups:
- name: disk
rules:
- alert: DiskSpaceUsageHigh
expr: (node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_avail_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary:"Disk space usage is above 85%"
- alert: DiskSpaceUsageCritical
expr: (node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_avail_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100 > 95
for: 1m
labels:
severity: critical
annotations:
summary:"Disk space usage is above 95%, immediate action required"
Zabbix 监控模板也推荐部署 LLD(Low Level Discovery)自动发现挂载点并监控。
10.2 日志空间限制
通过配置限制日志目录的最大空间:
# 使用 logrotate 自动管理 # 确保配置文件存在且正确 # 对于 Nginx,可以限制 access_log 缓冲 access_log /var/log/nginx/access.log combined buffer=32k flush=5s;
10.3 独立分区策略
关键目录使用独立分区,防止单一目录占满根分区:
/var/log 独立分区
/tmp 独立分区(使用 tmpfs 可以获得更好性能)
/home 独立分区
/data 或 /opt 独立分区
# /etc/fstab 示例 tmpfs /tmp tmpfs defaults,noexec,nosuid,size=2G 0 0 tmpfs /var/tmp tmpfs defaults,noexec,nosuid,size=1G 0 0
10.4 数据库数据目录独立
数据库数据目录应该放在独立分区或 LVM:
# 创建独立 LV 给 MySQL lvcreate -L 100G -n mysql vg mkfs.xfs /dev/mapper/vg-mysql mount /dev/mapper/vg-mysql /var/lib/mysql
10.5 定期检查脚本
部署定时任务定期检查磁盘空间:
# /etc/cron.daily/disk-check
#!/bin/bash
THRESHOLD=85
df -h | grep -vE'^Filesystem|tmpfs|cdrom'| awk -v threshold=$THRESHOLD'{if ($5+0 >= threshold) print $1 " " $5 " is above threshold"}'| mail -s"[Alert] Disk space warning"admin@example.com
11. 常见场景处理
场景一:/var/log 目录占满
# 查看 /var/log 各文件大小 du -sh /var/log/* ls -lhS /var/log/*.log # 如果是 messages 文件过大 : > /var/log/messages # 然后重启 rsyslog systemctl restart rsyslog # 如果是 secure 文件过大(SSH 暴力破解) : > /var/log/secure # 清理已切割的旧日志 find /var/log-name"*.gz"-mtime +7 -delete find /var/log-name"*.log.*"-mtime +7 -delete
场景二:/ 分区满但 /home 有空间
# 查看根分区占用分布 du -h --max-depth=1 / | sort -hr # 常见可疑目录 du -sh /var/* du -sh /tmp du -sh /.snapshots # Snapper 快照 # 如果 /var/lib/docker 占用过大,清理 Docker docker system prune -af
场景三:LVM VG 没有剩余空间
# 查看 VG 状态 vgdisplay vg_name | grep -E"Free PE|Total PE" # 如果有未使用的 PV,可以移除释放空间 vgreduce vg_name /dev/sdc1 # 或者扩展 VG(添加新磁盘) pvcreate /dev/sdd vgextend vg_name /dev/sdd # 或者缩小某个不常用的 LV # 先备份/卸载 umount /mnt/backup e2fsck -f /dev/mapper/vg-backup resize2fs /dev/mapper/vg-backup 50G lvreduce -L 50G /dev/mapper/vg-backup
场景四:Nginx 写入失败但日志文件被删除
# 检查是否有进程持有已删除文件的 FD lsof +L1 # 如果是 Nginx nginx -s reopen # 查看 Nginx 错误日志 tail -f /var/log/nginx/error.log # 如果 Nginx 仍无法写入,可能是权限问题 ls -la /var/log/nginx/ chown nginx:nginx /var/log/nginx/
12. 总结
磁盘空间问题排查的核心是分层定位:从 df 确定哪个挂载点,到 du 确定哪个目录,再 find 确定具体文件。
最容易被忽视的问题是已删除但仍被进程占用的文件,用 lsof +L1 可以快速定位。
清理磁盘空间时,必须区分可以立即删除的文件(如旧日志、临时文件)和需要先处理的文件(如正在写入的日志)。对正在写入的文件使用 truncate 清空内容而不是 rm 删除。
LVM 环境下的空间调整比普通分区更灵活,可以在线扩展。生产环境推荐使用 LVM 管理磁盘。
预防比排查更重要:完善的监控告警可以提前发现空间紧张,定期的清理任务可以防止空间耗尽。
-
Linux
+关注
关注
88文章
11888浏览量
220165 -
服务器
+关注
关注
14文章
10487浏览量
91960 -
磁盘
+关注
关注
1文章
403浏览量
26648
原文标题:服务器磁盘满了怎么办?一次讲透 Linux 磁盘排查思路
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
安卓应用商店和APP市场管理机制
Linux系统的性能优化策略
命令终端的常用操作有哪些?软件包管理机制是什么
播出服务器磁盘I/O与缓存性能分析
一种基于信息流策略的组密钥管理机制

嵌入式系统内存管理机制详解
浅析物理内存与虚拟内存的关系及其管理机制
华纳云服务器Linux系统电源管理与节能优化配置方法
Linux磁盘管理指令合集:从查看、分区到修复




评论