 Nginx+Keepalived双主架构消除单点故障的最佳实践
Nginx+Keepalived双主架构消除单点故障的最佳实践

Nginx+Keepalived双主架构:消除单点故障的最佳实践
一、概述
1.1 背景介绍
玩负载均衡的都知道,单台 Nginx 就是个定时炸弹。跑得再稳,硬件故障、网络抖动、内核 panic 这些事谁也说不准啥时候来。我见过太多团队,业务量不大的时候单机裸奔,等出了事故才想起来要做高可用,然后手忙脚乱地上线,结果配置没调好又出问题。
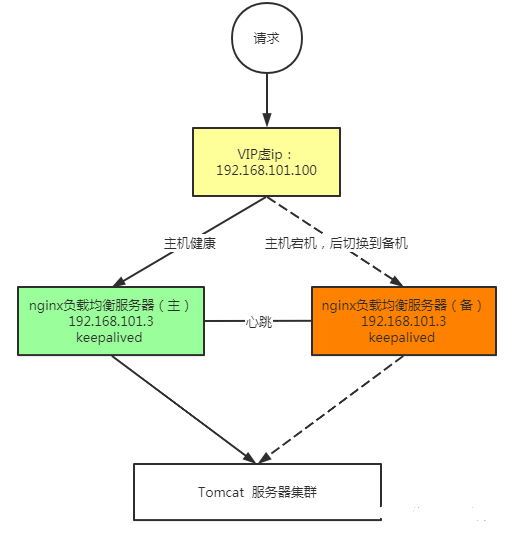
传统的 Nginx + Keepalived 主备模式有个明显缺点:备机资源闲置。一台几万块的服务器放在那里只等着主机挂掉才派上用场,这 ROI 怎么算都不划算。双主架构就是为了解决这个问题——两台机器都在干活,互为备份,任何一台挂了另一台顶上,资源利用率直接翻倍。
我在某金融科技公司就用这套架构抗住了双十一的流量洪峰,两台 16 核 64G 的机器,日常各承担 50% 流量,峰值时任意一台都能扛住全部流量。关键是成本比买专业负载均衡设备便宜太多了。
1.2 技术特点
双主架构的核心思路:
传统主备模式下,VIP(虚拟 IP)只绑在主机上,备机处于等待状态。双主模式的思路是使用两个 VIP,每台机器各持有一个 VIP 作为主,同时作为对方 VIP 的备。
正常状态: VIP1 (192.168.1.100) -> NodeA (主) <- DNS 轮询 VIP2 (192.168.1.101) -> NodeB (主) <- DNS 轮询 NodeA 故障: VIP1 (192.168.1.100) -> NodeB (接管) VIP2 (192.168.1.101) -> NodeB (主) NodeB 故障: VIP1 (192.168.1.100) -> NodeA (主) VIP2 (192.168.1.101) -> NodeA (接管)
技术优势:
资源利用率翻倍:两台服务器都在服务,没有闲置
故障切换快:Keepalived 秒级切换,业务感知弱
扩展性好:后续可以升级为更复杂的集群架构
成本低:用开源软件实现商业级高可用
1.3 适用场景
这套架构适合:
中小型网站,日 PV 在 500 万以下
对成本敏感但又需要高可用的场景
内部系统入口网关
API 网关层
不适合的场景:
超大流量(超过单机极限),建议上 LVS + Keepalived
需要复杂流量调度的场景,建议用专业 ADC 设备
1.4 环境要求
| 组件 | 版本 | 说明 |
|---|---|---|
| 操作系统 | Rocky Linux 9.3 / Ubuntu 24.04 LTS | 本文以 Rocky Linux 为例 |
| Nginx | 1.26.2 (稳定版) / 1.27.3 (主线版) | 建议用稳定版 |
| Keepalived | 2.3.1 | 2025 年最新稳定版 |
| 服务器 | 2 台 | 配置相同,推荐 8核16G 起步 |
| 网卡 | 千兆/万兆 | 双网卡绑定更佳 |
| VIP | 2 个 | 与服务器同网段 |
网络规划示例:
| 节点 | 真实 IP | VIP | 角色 |
|---|---|---|---|
| NodeA | 192.168.1.11 | 192.168.1.100 (主) | Nginx + Keepalived |
| NodeB | 192.168.1.12 | 192.168.1.101 (主) | Nginx + Keepalived |
二、详细步骤
2.1 准备工作
两台服务器都要做的基础配置
关闭 SELinux:
# 临时关闭 setenforce 0 # 永久关闭 sed -i's/SELINUX=enforcing/SELINUX=disabled/'/etc/selinux/config
配置防火墙:
# 开放 Nginx 端口 firewall-cmd --permanent --add-port=80/tcp firewall-cmd --permanent --add-port=443/tcp # 开放 VRRP 协议(Keepalived 通信用) firewall-cmd --permanent --add-rich-rule='rule protocol value="vrrp" accept' # 重载防火墙 firewall-cmd --reload
内核参数优化:
cat > /etc/sysctl.d/99-nginx-keepalived.conf << 'EOF' # 允许绑定非本机 IP(VIP 漂移必须) net.ipv4.ip_nonlocal_bind = 1 # 网络优化 net.core.somaxconn = 65535 net.core.netdev_max_backlog = 65535 net.ipv4.tcp_max_syn_backlog = 65535 net.ipv4.tcp_fin_timeout = 10 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_max_tw_buckets = 1440000 # 文件描述符 fs.file-max = 2097152 EOF sysctl -p /etc/sysctl.d/99-nginx-keepalived.conf
配置 hosts(可选,方便管理):
cat >> /etc/hosts << 'EOF' 192.168.1.11 nginx-node-a 192.168.1.12 nginx-node-b 192.168.1.100 vip1.example.com 192.168.1.101 vip2.example.com EOF
安装 Nginx
方法一:官方仓库安装(推荐)
# 添加 Nginx 官方仓库 cat > /etc/yum.repos.d/nginx.repo << 'EOF' [nginx-stable] name=nginx stable repo baseurl=http://nginx.org/packages/centos/$releasever/$basearch/ gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.key module_hotfixes=true [nginx-mainline] name=nginx mainline repo baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/ gpgcheck=1 enabled=0 gpgkey=https://nginx.org/keys/nginx_signing.key module_hotfixes=true EOF # 安装稳定版 dnf install -y nginx # 或者安装主线版 # dnf config-manager --enable nginx-mainline # dnf install -y nginx
方法二:编译安装(需要特定模块时)
# 安装依赖 dnf install -y gcc make pcre2-devel openssl-devel zlib-devel libxml2-devel libxslt-devel gd-devel GeoIP-devel # 下载源码 cd/usr/local/src wget https://nginx.org/download/nginx-1.26.2.tar.gz tar xzf nginx-1.26.2.tar.gz cdnginx-1.26.2 # 编译配置 ./configure --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/run/nginx.pid --lock-path=/run/nginx.lock --with-threads --with-file-aio --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_gzip_static_module --with-http_stub_status_module --with-stream --with-stream_ssl_module --with-stream_realip_module make -j$(nproc) make install
安装 Keepalived
# Rocky Linux 9 dnf install -y keepalived # 查看版本 keepalived --version # Keepalived v2.3.1 # 如果仓库版本较老,可以编译安装 cd/usr/local/src wget https://www.keepalived.org/software/keepalived-2.3.1.tar.gz tar xzf keepalived-2.3.1.tar.gz cdkeepalived-2.3.1 ./configure --prefix=/usr/local/keepalived make -j$(nproc) make install # 创建软链接 ln -sf /usr/local/keepalived/sbin/keepalived /usr/sbin/keepalived ln -sf /usr/local/keepalived/etc/keepalived /etc/keepalived
2.2 核心配置
Nginx 配置(两台相同)
# /etc/nginx/nginx.conf user nginx; worker_processes auto; worker_cpu_affinity auto; error_log /var/log/nginx/error.log warn; pid /run/nginx.pid; # 工作进程能打开的最大文件数 worker_rlimit_nofile 65535; events { use epoll; worker_connections 65535; multi_accept on; } http { include /etc/nginx/mime.types; default_type application/octet-stream; # 日志格式 - 包含真实客户端 IP log_format main'$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for" ' 'rt=$request_time uct="$upstream_connect_time" ' 'uht="$upstream_header_time" urt="$upstream_response_time"'; access_log /var/log/nginx/access.log main buffer=16k flush=5s; # 基础优化 sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; # Gzip 压缩 gzip on; gzip_min_length 1k; gzip_comp_level 4; gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript; gzip_vary on; # 代理缓冲 proxy_buffer_size 16k; proxy_buffers 4 64k; proxy_busy_buffers_size 128k; # 连接超时 proxy_connect_timeout 5s; proxy_send_timeout 60s; proxy_read_timeout 60s; # 上游服务器组 upstream backend_servers { least_conn; keepalive 100; server 192.168.1.21:8080 weight=100 max_fails=3 fail_timeout=10s; server 192.168.1.22:8080 weight=100 max_fails=3 fail_timeout=10s; server 192.168.1.23:8080 weight=100 max_fails=3 fail_timeout=10s; } # 默认 server - 拒绝未知 Host server { listen 80 default_server; listen 443 ssl default_server; server_name _; ssl_certificate /etc/nginx/certs/default.crt; ssl_certificate_key /etc/nginx/certs/default.key; return444; } # 健康检查端点 - Keepalived 用 server { listen 127.0.0.1:10080; server_name localhost; location /nginx_status { stub_status on; allow 127.0.0.1; deny all; } location /health { return200"OK "; add_header Content-Type text/plain; } } # 业务 server server { listen 80; listen 443 ssl; server_name www.example.com example.com; ssl_certificate /etc/nginx/certs/example.com.crt; ssl_certificate_key /etc/nginx/certs/example.com.key; ssl_protocols TLSv1.2 TLSv1.3; ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256; ssl_prefer_server_ciphers on; ssl_session_cache shared10m; ssl_session_timeout 10m; # HSTS add_header Strict-Transport-Security"max-age=31536000"always; # 静态文件 location ~* .(jpg|jpeg|png|gif|ico|css|js|woff|woff2)$ { root /var/www/static; expires 30d; add_header Cache-Control"public, immutable"; } # 动态请求代理到后端 location / { proxy_pass http://backend_servers; proxy_http_version 1.1; proxy_set_header Connection""; proxy_set_header Host$host; proxy_set_header X-Real-IP$remote_addr; proxy_set_header X-Forwarded-For$proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto$scheme; # 健康检查失败时跳过问题节点 proxy_next_upstream error timeout http_500 http_502 http_503 http_504; proxy_next_upstream_tries 3; proxy_next_upstream_timeout 10s; } } include /etc/nginx/conf.d/*.conf; }
Keepalived 配置 - NodeA
# /etc/keepalived/keepalived.conf (NodeA)
global_defs {
router_id NGINX_HA_NODE_A
# 脚本安全配置
script_user root
enable_script_security
# 邮件告警(可选)
notification_email {
ops@example.com
}
notification_email_from keepalived@nginx-node-a
smtp_server 127.0.0.1
smtp_connect_timeout 30
}
# Nginx 健康检查脚本
vrrp_script check_nginx {
script"/etc/keepalived/scripts/check_nginx.sh"
interval 2 # 检查间隔 2 秒
weight -20 # 检查失败时权重减 20
fall 3 # 连续 3 次失败判定为故障
rise 2 # 连续 2 次成功判定为恢复
}
# VIP1 - NodeA 为主
vrrp_instance VI_1 {
state MASTER # 初始状态为 MASTER
interface eth0 # 绑定的网卡
virtual_router_id 51 # 虚拟路由 ID,同一组内必须相同
priority 150 # 优先级,MASTER 要比 BACKUP 高
advert_int 1 # VRRP 通告间隔
# 认证配置(两节点必须一致)
authentication {
auth_type PASS
auth_pass K33pAl1v3d_VIP1 # 密码最多 8 位
}
# 虚拟 IP 配置
virtual_ipaddress {
192.168.1.100/24 dev eth0 label eth0:vip1
}
# 绑定健康检查脚本
track_script {
check_nginx
}
# 状态变更通知脚本
notify_master"/etc/keepalived/scripts/notify.sh master VI_1"
notify_backup"/etc/keepalived/scripts/notify.sh backup VI_1"
notify_fault"/etc/keepalived/scripts/notify.sh fault VI_1"
}
# VIP2 - NodeA 为备
vrrp_instance VI_2 {
state BACKUP # 初始状态为 BACKUP
interface eth0
virtual_router_id 52 # 注意要和 VI_1 不同
priority 100 # 优先级比 NodeB 低
advert_int 1
authentication {
auth_type PASS
auth_pass K33pAl1v3d_VIP2
}
virtual_ipaddress {
192.168.1.101/24 dev eth0 label eth0:vip2
}
track_script {
check_nginx
}
notify_master"/etc/keepalived/scripts/notify.sh master VI_2"
notify_backup"/etc/keepalived/scripts/notify.sh backup VI_2"
notify_fault"/etc/keepalived/scripts/notify.sh fault VI_2"
}
Keepalived 配置 - NodeB
# /etc/keepalived/keepalived.conf (NodeB)
global_defs {
router_id NGINX_HA_NODE_B
script_user root
enable_script_security
notification_email {
ops@example.com
}
notification_email_from keepalived@nginx-node-b
smtp_server 127.0.0.1
smtp_connect_timeout 30
}
vrrp_script check_nginx {
script"/etc/keepalived/scripts/check_nginx.sh"
interval 2
weight -20
fall 3
rise 2
}
# VIP1 - NodeB 为备
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51 # 和 NodeA 的 VI_1 相同
priority 100 # 比 NodeA 低
advert_int 1
authentication {
auth_type PASS
auth_pass K33pAl1v3d_VIP1 # 密码必须和 NodeA 一致
}
virtual_ipaddress {
192.168.1.100/24 dev eth0 label eth0:vip1
}
track_script {
check_nginx
}
notify_master"/etc/keepalived/scripts/notify.sh master VI_1"
notify_backup"/etc/keepalived/scripts/notify.sh backup VI_1"
notify_fault"/etc/keepalived/scripts/notify.sh fault VI_1"
}
# VIP2 - NodeB 为主
vrrp_instance VI_2 {
state MASTER
interface eth0
virtual_router_id 52
priority 150 # 比 NodeA 高
advert_int 1
authentication {
auth_type PASS
auth_pass K33pAl1v3d_VIP2
}
virtual_ipaddress {
192.168.1.101/24 dev eth0 label eth0:vip2
}
track_script {
check_nginx
}
notify_master"/etc/keepalived/scripts/notify.sh master VI_2"
notify_backup"/etc/keepalived/scripts/notify.sh backup VI_2"
notify_fault"/etc/keepalived/scripts/notify.sh fault VI_2"
}
健康检查脚本
# /etc/keepalived/scripts/check_nginx.sh
#!/bin/bash
# Nginx 健康检查脚本
# 方法1:检查进程是否存在
# pidof nginx > /dev/null 2>&1 || exit 1
# 方法2:检查端口是否监听(更准确)
# ss -tlnp | grep -q ':80 ' || exit 1
# 方法3:HTTP 健康检查(最可靠)
RESPONSE=$(curl -s -o /dev/null -w"%{http_code}"http://127.0.0.1:10080/health 2>/dev/null)
if["$RESPONSE"=="200"];then
exit0
else
exit1
fi
状态通知脚本
# /etc/keepalived/scripts/notify.sh
#!/bin/bash
# Keepalived 状态变更通知脚本
STATE=$1 # master/backup/fault
VRRP_INSTANCE=$2
HOSTNAME=$(hostname)
DATETIME=$(date'+%Y-%m-%d %H:%M:%S')
LOG_FILE="/var/log/keepalived-notify.log"
log_message() {
echo"[$DATETIME]$1">>$LOG_FILE
}
case"$STATE"in
master)
log_message"[$VRRP_INSTANCE] Transition to MASTER on$HOSTNAME"
# 可以在这里发送告警通知
# curl -X POST "https://your-webhook.com/alert" -d "msg=$HOSTNAME became MASTER for $VRRP_INSTANCE"
;;
backup)
log_message"[$VRRP_INSTANCE] Transition to BACKUP on$HOSTNAME"
;;
fault)
log_message"[$VRRP_INSTANCE] Transition to FAULT on$HOSTNAME"
# 故障状态,发送紧急告警
# curl -X POST "https://your-webhook.com/alert" -d "msg=$HOSTNAME FAULT for $VRRP_INSTANCE"
;;
*)
log_message"[$VRRP_INSTANCE] Unknown state:$STATE"
;;
esac
设置脚本权限:
mkdir -p /etc/keepalived/scripts chmod +x /etc/keepalived/scripts/*.sh
2.3 启动和验证
启动服务:
# 两台服务器都执行 # 启动 Nginx systemctlenablenginx systemctl start nginx systemctl status nginx # 启动 Keepalived systemctlenablekeepalived systemctl start keepalived systemctl status keepalived
验证 VIP 绑定:
# NodeA 上查看 ip addr show eth0 | grep -E"inet.*vip" # 应该看到 192.168.1.100 # NodeB 上查看 ip addr show eth0 | grep -E"inet.*vip" # 应该看到 192.168.1.101
验证服务可用性:
# 从客户端测试两个 VIP curl -I http://192.168.1.100/health curl -I http://192.168.1.101/health
测试故障切换:
# 在 NodeA 上停止 Nginx systemctl stop nginx # 等待几秒后检查 VIP 是否漂移到 NodeB # 在 NodeB 上执行 ip addr show eth0 | grep -E"inet.*vip" # 应该看到两个 VIP:192.168.1.100 和 192.168.1.101 # 恢复 NodeA 的 Nginx systemctl start nginx # VIP1 应该漂移回 NodeA(抢占模式)
三、示例代码和配置
3.1 完整配置示例
生产环境配置清单
# 目录结构 /etc/nginx/ ├── nginx.conf ├── conf.d/ │ ├── upstream.conf # 上游服务器配置 │ ├── ssl.conf # SSL 通用配置 │ └── www.example.com.conf # 站点配置 ├── certs/ │ ├── example.com.crt │ └── example.com.key └── snippets/ ├── proxy-params.conf # 代理参数 └── security-headers.conf # 安全头 /etc/keepalived/ ├── keepalived.conf └── scripts/ ├── check_nginx.sh └── notify.sh
upstream.conf
# /etc/nginx/conf.d/upstream.conf
# Web 应用服务器
upstream web_app {
least_conn;
keepalive 100;
keepalive_requests 1000;
keepalive_timeout 60s;
server 10.10.1.11:8080 weight=100 max_fails=3 fail_timeout=10s;
server 10.10.1.12:8080 weight=100 max_fails=3 fail_timeout=10s;
server 10.10.1.13:8080 weight=100 max_fails=3 fail_timeout=10s;
server 10.10.1.14:8080 weight=100 max_fails=3 fail_timeout=10s;
}
# API 服务
upstream api_service {
least_conn;
keepalive 50;
server 10.10.2.11:3000 weight=100;
server 10.10.2.12:3000 weight=100;
}
# WebSocket 服务
upstream websocket_service {
ip_hash; # WebSocket 需要会话保持
server 10.10.3.11:8000;
server 10.10.3.12:8000;
}
proxy-params.conf
# /etc/nginx/snippets/proxy-params.conf proxy_http_version 1.1; proxy_set_header Connection""; proxy_set_header Host$host; proxy_set_header X-Real-IP$remote_addr; proxy_set_header X-Forwarded-For$proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto$scheme; proxy_set_header X-Forwarded-Host$host; proxy_set_header X-Forwarded-Port$server_port; proxy_connect_timeout 5s; proxy_send_timeout 60s; proxy_read_timeout 60s; proxy_buffer_size 16k; proxy_buffers 4 64k; proxy_busy_buffers_size 128k; proxy_next_upstream error timeout http_500 http_502 http_503 http_504; proxy_next_upstream_tries 3; proxy_next_upstream_timeout 10s;
站点配置
# /etc/nginx/conf.d/www.example.com.conf
# HTTP -> HTTPS 重定向
server {
listen 80;
server_name www.example.com example.com;
return301 https://$host$request_uri;
}
# HTTPS 主站
server {
listen 443 ssl http2;
server_name www.example.com example.com;
# SSL 配置
ssl_certificate /etc/nginx/certs/example.com.crt;
ssl_certificate_key /etc/nginx/certs/example.com.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384;
ssl_prefer_server_ciphers on;
ssl_session_cache shared10m;
ssl_session_timeout 1d;
ssl_session_tickets off;
# 安全头
add_header Strict-Transport-Security"max-age=31536000; includeSubDomains"always;
add_header X-Frame-Options"SAMEORIGIN"always;
add_header X-Content-Type-Options"nosniff"always;
add_header X-XSS-Protection"1; mode=block"always;
# 静态文件
location /static/ {
alias/var/www/static/;
expires 30d;
add_header Cache-Control"public, immutable";
# 静态文件直接返回,不走代理
try_files$uri=404;
}
# API 接口
location /api/ {
include /etc/nginx/snippets/proxy-params.conf;
proxy_pass http://api_service;
}
# WebSocket
location /ws/ {
proxy_pass http://websocket_service;
proxy_http_version 1.1;
proxy_set_header Upgrade$http_upgrade;
proxy_set_header Connection"upgrade";
proxy_set_header Host$host;
proxy_set_header X-Real-IP$remote_addr;
# WebSocket 超时要设长一些
proxy_read_timeout 3600s;
proxy_send_timeout 3600s;
}
# 默认走 Web 应用
location / {
include /etc/nginx/snippets/proxy-params.conf;
proxy_pass http://web_app;
}
# 健康检查端点(给上层负载均衡用)
location /health {
access_log off;
return200"OK
";
add_header Content-Type text/plain;
}
}
3.2 实际应用案例
案例一:多站点双主架构
某公司有三个域名需要高可用:
# DNS 配置(两个 VIP 都解析到每个域名) www.site-a.com A 192.168.1.100 www.site-a.com A 192.168.1.101 www.site-b.com A 192.168.1.100 www.site-b.com A 192.168.1.101 api.company.com A 192.168.1.100 api.company.com A 192.168.1.101
Nginx 配置多个 server 块,每个域名对应不同的后端:
# /etc/nginx/conf.d/multi-site.conf
# Site A
server {
listen 80;
server_name www.site-a.com;
location / {
proxy_pass http://site_a_backend;
}
}
# Site B
server {
listen 80;
server_name www.site-b.com;
location / {
proxy_pass http://site_b_backend;
}
}
# API
server {
listen 80;
server_name api.company.com;
location / {
proxy_pass http://api_backend;
}
}
案例二:非抢占式双主
有些场景下不希望 VIP 来回漂移(减少切换带来的抖动),可以配置非抢占模式:
# NodeA - VI_1 配置
vrrp_instance VI_1 {
state BACKUP # 两边都设置为 BACKUP
nopreempt # 关键:禁止抢占
interface eth0
virtual_router_id 51
priority 150 # 优先级高的会先成为 MASTER
advert_int 1
authentication {
auth_type PASS
auth_pass K33pAl1v3d
}
virtual_ipaddress {
192.168.1.100/24
}
track_script {
check_nginx
}
}
# NodeB - VI_1 配置
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass K33pAl1v3d
}
virtual_ipaddress {
192.168.1.100/24
}
track_script {
check_nginx
}
}
这样配置后,即使 NodeA 恢复了,VIP 也不会从 NodeB 抢回来,减少不必要的切换。
案例三:与云厂商 SLB 配合
在云环境下,通常前面还有云厂商的 SLB(如 AWS ALB、阿里云 SLB)。这时候双主架构变成:
SLB (云厂商) ├── NodeA (真实 IP) └── NodeB (真实 IP)
这种场景不需要 Keepalived 做 VIP 漂移,但可以利用其健康检查能力:
# 简化版 keepalived.conf - 只做健康检查
global_defs {
router_id NGINX_HEALTH
}
vrrp_script check_nginx {
script"/etc/keepalived/scripts/check_nginx.sh"
interval 2
weight -20
fall 3
rise 2
}
# 使用单播避免影响云网络
vrrp_instance VI_HEALTH {
state BACKUP
interface eth0
virtual_router_id 99
priority 100
advert_int 1
nopreempt
# 单播配置
unicast_src_ip 10.0.1.11
unicast_peer {
10.0.1.12
}
track_script {
check_nginx
}
notify_master"/etc/keepalived/scripts/notify_slb.sh register"
notify_fault"/etc/keepalived/scripts/notify_slb.sh deregister"
}
notify_slb.sh 脚本通过云 API 来注册/注销节点。
四、最佳实践和注意事项
4.1 最佳实践
1. 健康检查要检查业务,不要只检查进程
我见过很多配置只检查 Nginx 进程是否存在,这是不够的。Nginx 进程在,但后端全挂了,或者配置错误导致返回 500,这种情况进程检查是发现不了的。
# 更完善的健康检查脚本
#!/bin/bash
# 检查 Nginx 进程
if! pidof nginx > /dev/null;then
echo"Nginx process not found"
exit1
fi
# 检查端口监听
if! ss -tlnp | grep -q':80 ';then
echo"Port 80 not listening"
exit1
fi
# 检查 HTTP 响应
HTTP_CODE=$(curl -s -o /dev/null -w"%{http_code}"
--connect-timeout 2
--max-time 5
http://127.0.0.1:10080/health 2>/dev/null)
if["$HTTP_CODE"!="200"];then
echo"Health check returned$HTTP_CODE"
exit1
fi
# 可选:检查后端连通性
BACKEND_STATUS=$(curl -s -o /dev/null -w"%{http_code}"
--connect-timeout 2
--max-time 5
http://127.0.0.1/api/health 2>/dev/null)
if["$BACKEND_STATUS"-ge 500 ];then
echo"Backend unhealthy, status:$BACKEND_STATUS"
exit1
fi
exit0
2. 合理设置优先级差值
优先级差值要大于 weight 的绝对值,否则可能出现脑裂:
# 假设 weight = -20 # NodeA priority = 150 # NodeB priority = 100 # 差值 = 50 > 20,OK # 如果设置成 # NodeA priority = 110 # NodeB priority = 100 # 差值 = 10 < 20 # 当 NodeA 健康检查失败时,priority 变成 90,低于 NodeB 的 100 # VIP 会漂移到 NodeB,但如果此时 NodeA 恢复了 # priority 又变回 110,VIP 又漂移回来 # 导致 VIP 来回跳
3. 配置组播/单播
默认 Keepalived 使用 224.0.0.18 组播地址通信。在某些网络环境下组播不通,需要改用单播:
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 150
advert_int 1
# 本机 IP
unicast_src_ip 192.168.1.11
# 对端 IP
unicast_peer {
192.168.1.12
}
authentication {
auth_type PASS
auth_pass K33pAl1v3d
}
virtual_ipaddress {
192.168.1.100/24
}
}
4. 日志分离
Keepalived 默认日志混在系统日志里,建议单独配置:
# /etc/rsyslog.d/keepalived.conf if$programnamestartswith'Keepalived'then/var/log/keepalived.log & stop
4.2 注意事项
| 问题类型 | 现象 | 原因分析 | 解决方案 |
|---|---|---|---|
| 脑裂 | 两台都持有同一个 VIP | 网络故障导致心跳检测失败 | 1. 检查网络连通性 2. 使用单播替代组播 3. 增加心跳检测网络 |
| VIP 不漂移 | 主机挂了 VIP 不切换 | 1. 防火墙阻止 VRRP 2. virtual_router_id 不一致 | 1. 开放 VRRP 协议 2. 检查配置一致性 |
| VIP 来回跳 | 频繁切换 | 1. 优先级差值设置不当 2. 网络抖动 | 1. 增大优先级差值 2. 增加 fall/rise 次数 |
| 切换后服务不可用 | VIP 切换成功但访问失败 | 1. 连接跟踪残留 2. ARP 缓存 | 1. 切换时清理 conntrack 2. 发送 GARP |
| 健康检查误判 | 服务正常但被判定故障 | 检查脚本超时或逻辑错误 | 1. 增加超时时间 2. 优化检查逻辑 |
踩坑经历:
有一次生产环境出现了诡异的问题——VIP 切换了,但客户端还是连不上。排查发现是上层交换机的 ARP 缓存没有及时更新。解决方案是在 notify 脚本里主动发送免费 ARP:
# 在 notify.sh 的 master 分支里添加 arping -c 3 -A -I eth0 192.168.1.100
五、故障排查和监控
5.1 故障排查
Keepalived 状态检查:
# 查看 Keepalived 进程 ps aux | grep keepalived # 查看 VIP 绑定情况 ip addr show | grep -E"inet.*vip" # 查看 Keepalived 日志 journalctl -u keepalived -f # 或者 tail -f /var/log/keepalived.log # 查看 VRRP 状态 cat /proc/net/netfilter/nf_conntrack | grep vrrp
网络连通性检查:
# 检查两节点间的网络 ping -c 3 192.168.1.12 # 检查 VRRP 组播是否通 tcpdump -i eth0 vrrp -nn # 检查防火墙规则 iptables -L -n | grep vrrp firewall-cmd --list-all
Nginx 状态检查:
# 检查 Nginx 进程 nginx -t systemctl status nginx # 检查端口监听 ss -tlnp | grep nginx # 检查连接数 ss -s # 检查 stub_status curl http://127.0.0.1:10080/nginx_status
手动触发故障切换测试:
# 方法1:停止 Nginx systemctl stop nginx # 方法2:停止 Keepalived systemctl stop keepalived # 方法3:模拟网络故障 iptables -A INPUT -p vrrp -j DROP # 恢复 iptables -D INPUT -p vrrp -j DROP
5.2 性能监控
Nginx 监控指标:
# 使用 nginx-module-vts 或者简单的 stub_status
location /nginx_status {
stub_status on;
allow 127.0.0.1;
deny all;
}
Prometheus + Grafana 监控:
# 安装 nginx-prometheus-exporter docker run -d -p 9113:9113 nginx/nginx-prometheus-exporter:latest -nginx.scrape-uri=http://192.168.1.11:10080/nginx_status
关键监控指标:
# Nginx 指标 nginx_connections_active:当前活跃连接数 nginx_connections_reading:正在读取的连接数 nginx_connections_writing:正在写入的连接数 nginx_connections_waiting:空闲等待的连接数 nginx_http_requests_total:请求总数 # Keepalived 指标(需要自己采集) keepalived_vrrp_state:VRRP状态(1=MASTER,2=BACKUP,3=FAULT) keepalived_vrrp_transitions:状态切换次数 # 报警规则 -活跃连接数超过worker_connections*0.8 -VRRP状态变化 -Nginx进程不存在 -健康检查失败
监控脚本示例:
#!/bin/bash
# /usr/local/bin/nginx-keepalived-monitor.sh
# 采集 Nginx 状态
NGINX_STATUS=$(curl -s http://127.0.0.1:10080/nginx_status)
ACTIVE=$(echo"$NGINX_STATUS"| grep'Active'| awk'{print $3}')
READING=$(echo"$NGINX_STATUS"| grep'Reading'| awk'{print $2}')
WRITING=$(echo"$NGINX_STATUS"| grep'Writing'| awk'{print $4}')
# 采集 Keepalived 状态
VIP1_STATUS="backup"
VIP2_STATUS="backup"
ifip addr show eth0 | grep -q"192.168.1.100";then
VIP1_STATUS="master"
fi
ifip addr show eth0 | grep -q"192.168.1.101";then
VIP2_STATUS="master"
fi
# 输出 Prometheus 格式
echo"# HELP nginx_connections_active Active connections"
echo"# TYPE nginx_connections_active gauge"
echo"nginx_connections_active$ACTIVE"
echo"# HELP keepalived_vip1_is_master VIP1 master status"
echo"# TYPE keepalived_vip1_is_master gauge"
if["$VIP1_STATUS"=="master"];then
echo"keepalived_vip1_is_master 1"
else
echo"keepalived_vip1_is_master 0"
fi
5.3 备份与恢复
配置备份脚本:
#!/bin/bash
# /usr/local/bin/backup-nginx-keepalived.sh
BACKUP_DIR="/backup/nginx-keepalived"
DATE=$(date +%Y%m%d_%H%M%S)
HOSTNAME=$(hostname)
mkdir -p${BACKUP_DIR}
# 备份 Nginx 配置
tar czf${BACKUP_DIR}/${HOSTNAME}_nginx_${DATE}.tar.gz
/etc/nginx/
/etc/sysctl.d/99-nginx-keepalived.conf
# 备份 Keepalived 配置
tar czf${BACKUP_DIR}/${HOSTNAME}_keepalived_${DATE}.tar.gz
/etc/keepalived/
# 备份证书
tar czf${BACKUP_DIR}/${HOSTNAME}_certs_${DATE}.tar.gz
/etc/nginx/certs/
# 保留 30 天
find${BACKUP_DIR}-typef -mtime +30 -delete
echo"Backup completed:${DATE}"
快速恢复流程:
# 1. 安装软件 dnf install -y nginx keepalived # 2. 恢复配置 tar xzf nginx_backup.tar.gz -C / tar xzf keepalived_backup.tar.gz -C / # 3. 验证配置 nginx -t keepalived -t # 4. 应用内核参数 sysctl -p /etc/sysctl.d/99-nginx-keepalived.conf # 5. 启动服务 systemctl start nginx systemctl start keepalived # 6. 验证状态 curl -I http://127.0.0.1/health ip addr show eth0 | grep vip
六、总结
6.1 技术要点回顾
双主架构的核心是两个 VIP,每台机器各持有一个,互为备份
Keepalived 的 priority 差值要大于健康检查的 weight 绝对值
健康检查脚本要检查业务层面,不能只检查进程
非抢占模式可以减少 VIP 来回漂移带来的抖动
在云环境下注意组播可能不通,要改用单播
6.2 进阶学习方向
三节点架构:引入仲裁节点解决脑裂问题
跨机房高可用:BGP + ECMP 实现跨机房流量调度
与 Consul/etcd 集成:实现服务发现和动态配置
Nginx Plus:商业版本提供更强大的健康检查和监控
6.3 参考资料
Nginx 官方文档: https://nginx.org/en/docs/
Keepalived 官方文档: https://www.keepalived.org/manpage.html
Keepalived GitHub: https://github.com/acassen/keepalived
Linux Virtual Server: http://www.linuxvirtualserver.org/
附录
A. 命令速查表
| 命令 | 说明 |
|---|---|
| nginx -t | 检查 Nginx 配置语法 |
| nginx -s reload | 平滑重载配置 |
| systemctl status keepalived | 查看 Keepalived 状态 |
| ip addr show eth0 | 查看 VIP 绑定情况 |
| tcpdump -i eth0 vrrp -nn | 抓取 VRRP 心跳包 |
| journalctl -u keepalived -f | 实时查看 Keepalived 日志 |
|
arping -c 3 -A -I eth0 |
发送免费 ARP |
| ss -tlnp | grep nginx | 查看 Nginx 监听端口 |
| curl http://127.0.0.1:10080/nginx_status | 查看 Nginx 状态 |
B. 配置参数详解
Keepalived 关键参数:
| 参数 | 说明 | 建议值 |
|---|---|---|
| state | 初始状态 | MASTER/BACKUP |
| priority | 优先级 | 1-255,MASTER 要比 BACKUP 高 |
| advert_int | 心跳间隔 | 1 秒 |
| virtual_router_id | 虚拟路由 ID | 1-255,同一组必须相同 |
| nopreempt | 禁止抢占 | 稳定性要求高时启用 |
| weight | 健康检查权重 | 负数,绝对值小于 priority 差值 |
| fall | 失败判定次数 | 2-3 |
| rise | 恢复判定次数 | 2 |
| interval | 检查间隔 | 2 秒 |
Nginx 负载均衡参数:
| 参数 | 说明 | 建议值 |
|---|---|---|
| weight | 权重 | 默认 1 |
| max_fails | 最大失败次数 | 2-3 |
| fail_timeout | 失败后暂停时间 | 10-30s |
| keepalive | 长连接数 | 50-100 |
| keepalive_requests | 单连接最大请求数 | 1000 |
| keepalive_timeout | 长连接超时 | 60s |
C. 术语表
| 术语 | 解释 |
|---|---|
| VIP | Virtual IP,虚拟 IP 地址,用于高可用切换 |
| VRRP | Virtual Router Redundancy Protocol,虚拟路由冗余协议 |
| MASTER | 主节点,持有 VIP 的节点 |
| BACKUP | 备节点,等待接管 VIP 的节点 |
| Priority | 优先级,决定谁成为 MASTER |
| Preempt | 抢占模式,高优先级节点恢复后抢回 VIP |
| Split-Brain | 脑裂,两个节点都认为自己是 MASTER |
| GARP | Gratuitous ARP,免费 ARP,用于通知网络 VIP 漂移 |
| Health Check | 健康检查,检测服务是否正常 |
| Failover | 故障切换,主节点故障时切换到备节点 |
-
内核
+关注
关注
4文章
1474浏览量
43088 -
负载均衡
+关注
关注
0文章
135浏览量
12907 -
nginx
+关注
关注
0文章
193浏览量
13203
原文标题:Nginx+Keepalived双主架构:消除单点故障的最佳实践
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
解析keepalived+nginx实现高可用方案技术
大数据技术ZooKeeper应用——解决分布式系统单点故障
评估残余故障率λRF、传感器、单点故障率λSPF和单点故障度量MSPFM的方法
如何用旁路工具提升网络可用性?
Keepalived工作原理简介
搭建Keepalived+Lvs+Nginx高可用集群负载均衡

Jtti:如何在服务器扩展时避免单点故障?有哪些常见的高可用性策略?
华纳云:服务器扩展中如何避免单点故障
nginx负载均衡配置介绍
确保网站无缝运行:Keepalived高可用与Nginx集成实战
Nginx在企业环境中的调优策略
疆鸿智能PROFIBUS集线器:破解天然气增压站网络单点故障难题




评论