 端到端下半场,如何做好高保真虚拟数据集的构建与感知?
端到端下半场,如何做好高保真虚拟数据集的构建与感知?

01 前言
随着自动驾驶技术的日益升级,以UniAD、FSD V12为代表的“端到端”架构正重构行业格局。这一架构试图通过单一神经网络直接建立从传感器输入到车辆控制的映射,从而突破传统模块化累积误差的局限。
然而端到端模型对数据分布的广度与深度均有着高要求,尤其是对缺乏归纳偏置的Transformer架构而言,“数据规模”与“场景覆盖度”可谓直接决定了模型上限。
现实路测数据面临极端的长尾工况数据局限,如实车采集“采不到、标不准、测不起、太危险”。在此背景下,“虚拟数据集”成为了大家关注的热点,通过构建涵盖极端天气、复杂交互及事故场景的高保真虚拟数据,我们不仅能够以低成本、高效率的方式生成海量带标签的样本,更能为端到端模型提供闭环训练环境。虚拟数据集已不再是现实数据的简单补充,而是训练高阶端到端模型不可或缺的一环。
为满足自动驾驶算法对高质量数据资产的迫切需求,并有效应对真实路测的局限,本文将全面阐述高保真虚拟数据集SimData的构建方法。我们将深入解析aiSim2nuScenes工具链如何实现从物理级虚拟数据生成、标准化格式转换,直至最终数据集评测与验证的全流程闭环。
 图1:虚拟数据集SimData样本示例
图1:虚拟数据集SimData样本示例02 SimData数据集概述
面对自动驾驶算法对高质量数据的需求,传统真实路测正面临着巨大压力,一是资金密集型的车队运营与指数级增长的维护成本,导致其缺乏规模效应,难以支撑感知模型的数据吞吐;二是人工3D标注在恶劣天气与远距视角下的主观偏差及真值缺失,直接限制模型精度的上限;三是海量低价值的数据稀释训练价值,导致“长尾”场景捕获效率极低;最后法律与伦理的红线,更致使缺少关键的“事故临界态”数据。
在此背景下,虚拟仿真凭借数字化优势成为直面以上压力的关键角色。它不仅能通过边际成本递减打破资金壁垒,还能利用自动化真值生成彻底消除了人工噪声,实现了像素级精确标注。此外虚拟仿真更能够实现全要素可控,进而可自由重构复杂交通流与极端工况。
对此,基于aiSim高保真仿真器,本文给大家介绍SimData虚拟数据集,以便能够针对感知算法痛点进行攻关。以下是该数据集的简要介绍与获取方式:(更多介绍可阅读SimData深度解析:高保真虚拟数据集的构建与评测)
①规模与密度:数据集包含15张高精度地图和45个独立场景,单传感器数据量级突破18,000帧,总样本量(Samples)达到215,472帧,目标实例(Instances)超过64,000个;
②场景多样性:覆盖高速公路(Highway)、城市峡谷(Urban)和立体停车场(Parking)三大核心ODD。特别是针对真实路测中难以捕捉的施工区域、高速匝道汇入、无保护路口以及光照剧烈变化的室内车库进行了重点建模;
③类别均衡性:针对真实数据集中“类别不平衡”的问题,SimData在保证Car、Pedestrian等基础类别密度的同时,增加了Trailer(拖车)、Barricade(路障)、Traffic Cone(交通锥)、Van(面包车)等稀缺类别的样本比例。这种人为干预的数据分布优化,直接提升了模型对异形障碍物的检出能力。
 图2:Highway(左)、Urban(中)、Parking(右)
图2:Highway(左)、Urban(中)、Parking(右)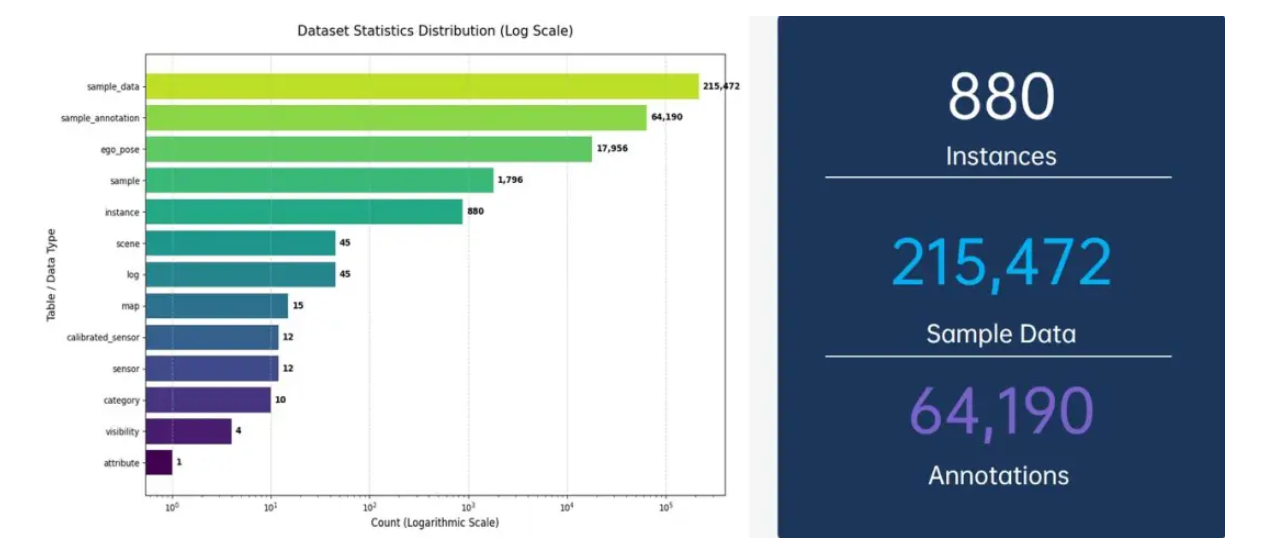 图3:数据集数据的分布统计,数据集包含了880个实例(Instances),215,472个关键帧数据(Sample Data)以及64,190个标注信息(Annotations)
图3:数据集数据的分布统计,数据集包含了880个实例(Instances),215,472个关键帧数据(Sample Data)以及64,190个标注信息(Annotations)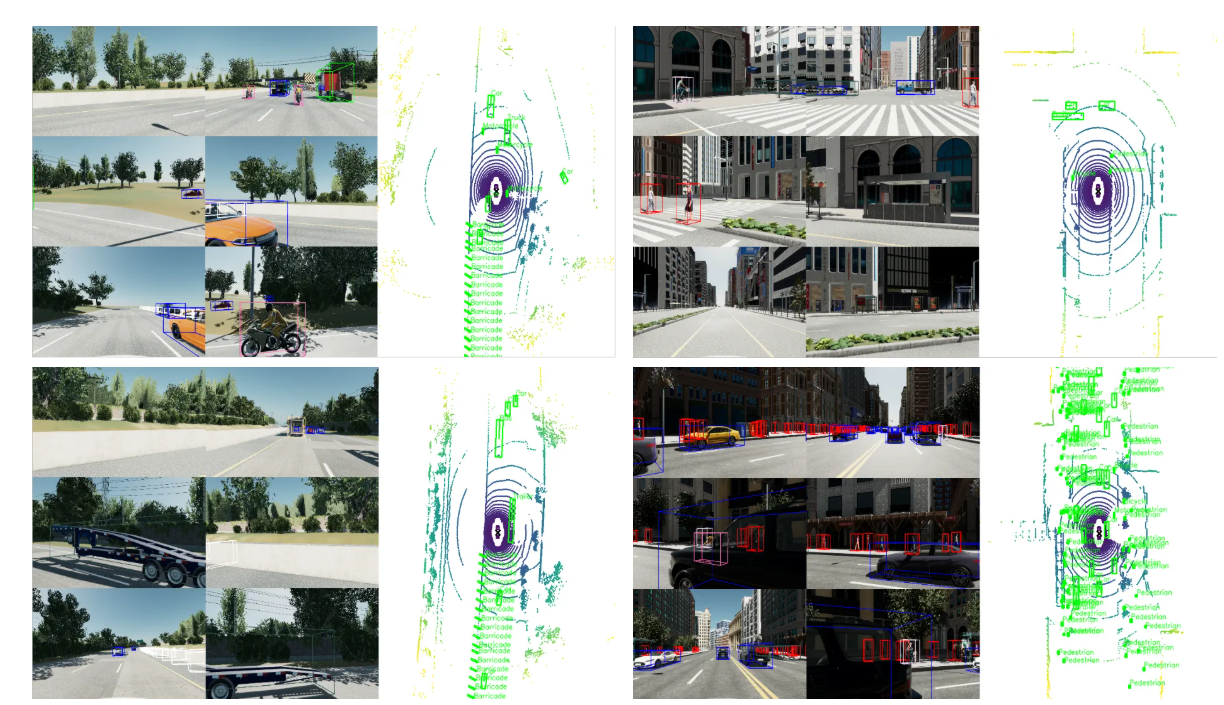 图4:simData标注真值在6环视相机以及bev视角下的可视化
图4:simData标注真值在6环视相机以及bev视角下的可视化目前,虚拟合成数据集SimData-V1已正式开源,可以通过以下链接直接获取:
完整版:https://huggingface.co/datasets/Keymotek/simData-Dataset
mini版:https://huggingface.co/datasets/Keymotek/simData_mini-Dataset
03 自动化工具链:aiSim2nuScenes
在自动驾驶从研发迈向落地的关键阶段,如何高效、标准化地将虚拟仿真环境转化为算法可直接摄取的高价值数据资产,已成为决定工程化成败的核心挑战。对此,本文介绍的aiSim2nuScenes 工具链,其并非单纯的数据转换接口,而是一套构建了从虚拟世界到算法应用标准桥梁的端到端合成数据生产与闭环评测体系。
该工具链以流水线作业的形式,无缝串联起高保真数据合成、标准化格式迁移以及自动化闭环测评三大关键环节。它不仅能基于物理引擎批量生成包含多模态传感器信息的原始数据,并能将其自动化映射为通用的 nuScenes 标准格式,彻底消除仿真平台与主流训练框架间的“隔阂”。
无缝集成的生态兼容性
为了降低工程团队的迁移成本,aiSim2nuScenes实现了对行业标准nuScenes-devkit的原生级支持。该工具链提供脚本(Script)批处理与图形化界面(GUI)双模式,能够自动解析aiSim导出的原始数据,并将其重构为nuScenes标准文件结构:
①视觉数据:自动完成从无损TGA格式到JPG的转换,并智能抽帧(默认每10帧提取关键帧),非关键帧自动归档至sweeps,保留了时序信息的完整性;
②点云数据:实现LiDAR数据从LAS到BIN、Radar数据从JSON到PCD的格式清洗与转换;
③元数据自动化:自动生成category.json(类别定义)、ego_pose.json(自车位姿)、calibrated_sensor.json(传感器外参)及sample_annotation.json(真值标注),彻底消除了人工标注引入的认知偏差与随机误差,实现了“生成即真值”。
微秒级多传感器时空同步
多模态融合算法对时间同步的敏感度极高。SimData数据集配置了经典的L2+传感器布局:6路环视相机(360° FOV)+ 1个顶置高线束LiDAR + 5个周视毫米波Radar。aiSim2nuScenes在数据生成阶段,通过确定性的仿真时钟,保证了所有传感器数据在同一时间戳下的严格对齐,同步精度达到微秒级,完美满足BEV算法对时空一致性的严苛要求。
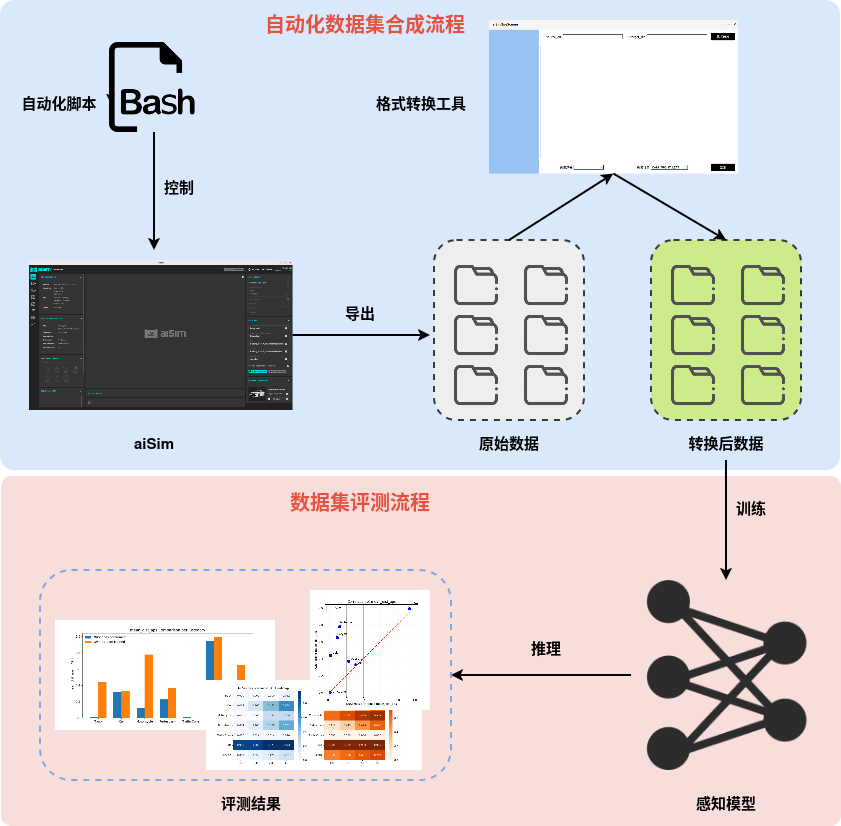 图5:从aiSim场景配置、仿真运行,到数据导出、自动化格式转换,再到最终感知模型训练的完整闭环
图5:从aiSim场景配置、仿真运行,到数据导出、自动化格式转换,再到最终感知模型训练的完整闭环04 算法实证:性能跨越与鲁棒性验证
“仿真数据能否训练出在真实世界可用的模型?”这是所有算法工程师关注的问题。为此,本文基于BEVFormer-tiny,设计了严谨的定量评测实验,用数据回答了关于收敛性、一致性与迁移能力的质疑。
良好的收敛性
在纯虚拟数据集上进行的训练实验显示,模型在30个Epoch内迅速收敛,最终mAP达到0.446,NDS(nuScenes Detection Score)达到0.428。特别是在Bus(AP 0.989)、Motorcycle(AP 0.778)等大尺寸目标上,检测精度极高。这证明aiSim生成的数据在统计分布和特征维度上是良构的,能够被深度神经网络有效拟合。
虚实一致性
为了探究模型“学到了什么”,本文对比了“SimData训练模型”与“nuScenes官方预训练模型”在SimData测试集上的表现。
①AP相关性分析:两者在不同类别上的AP值呈现显著正相关(Pearson系数接近1);
②Attention Heatmap分析:检测热力图显示,两个模型在距离感知和空间关注点上高度重合。无论是近处车辆的纹理特征,还是远处行人的轮廓信息,虚拟数据训练的模型展现出了与真实数据模型一致的注意力机制。这从可解释性角度有力证明了aiSim数据的高保真度。
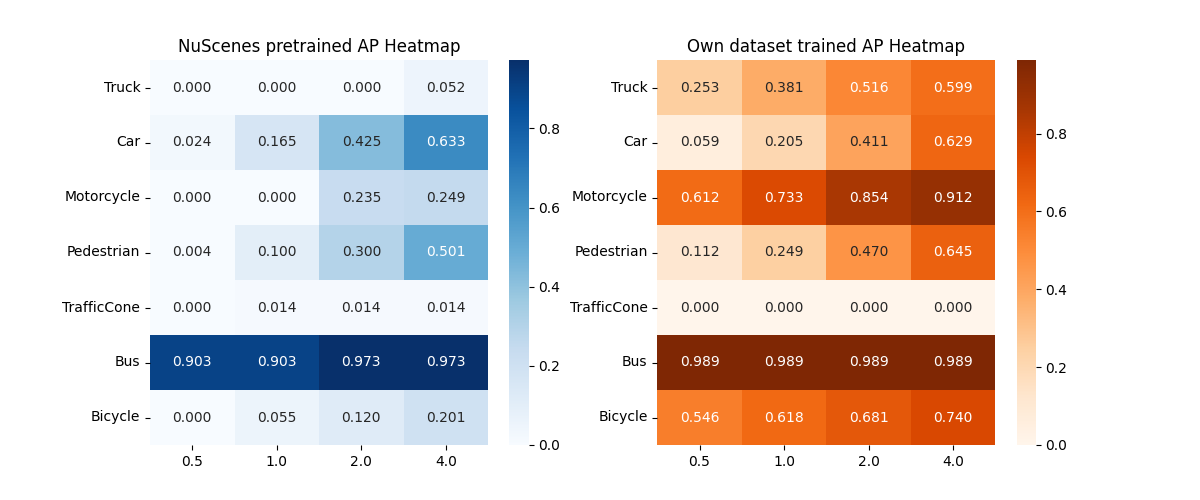 图6:热力图显示,SimData训练的模型(右)与真实数据模型(左)在空间关注模式上高度一致,证明了两者在特征提取层面的同源性。
图6:热力图显示,SimData训练的模型(右)与真实数据模型(左)在空间关注模式上高度一致,证明了两者在特征提取层面的同源性。迁移学习
最具工程价值的发现来自于域适应实验。本文实验对比了三种策略:(1) 仅SimData训练,(2) 仅nuScenes训练,(3) nuScenes预训练 + SimData微调(Pre-train + Fine-tune)。
结果显示,“Pre-train + Fine-tune”策略在绝大多数类别上实现了性能的全面超越;比如在Pedestrian(行人)、Trailer(拖车)、Barricade(路障)等长尾类别上,微调后的模型检测精度均有显著提升。
因此可证明虚拟数据并非真实数据的简单替代,而是其完美的互补。“真实先验 + 仿真多样性”的组合,能够有效抑制过拟合,帮助模型学习到更具泛化能力的特征表示,从而显著提升模型在面对真实世界未见场景时的鲁棒性。
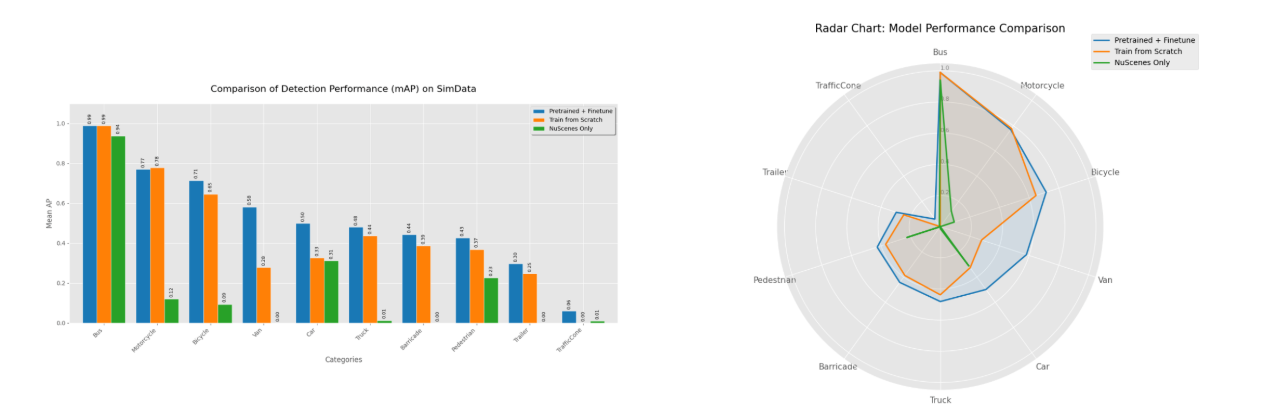 图7:实验数据显示,“Pre-train + Fine-tune”方案在几乎所有类别上包围了对比方案,证明了高保真合成数据在提升模型泛化能力方面的巨大潜力
图7:实验数据显示,“Pre-train + Fine-tune”方案在几乎所有类别上包围了对比方案,证明了高保真合成数据在提升模型泛化能力方面的巨大潜力验证结论
总结来看,以上实验结果表明,aiSim生成的数据在统计分布与特征维度上具备高度的良构性,不仅支持深度神经网络在纯虚拟环境下的迅速收敛与高精度检测,更在注意力机制展现了与真实世界模型高度一致的特征同源性。这证明了高质量的仿真数据能够让算法“学会”与现实世界通用的感知逻辑。
在域适应实验中,“真实先验 + 仿真多样性”的混合训练策略展现了超越单一数据源的SOTA性能。虚拟数据并未止步于对真实数据的简单替代,而是凭借其对长尾场景(如路障、特殊车辆)的覆盖能力,成为了真实数据的完美互补。这种组合有效抑制了过拟合,显著增强了模型在面对未知场景时的泛化能力与鲁棒性。
高质量虚拟数据集的核心在于对真实物理世界的准确建模能力。只有当仿真数据在成像机理与信号生成层面具备确定性和一致性,才能真正服务于自动驾驶算法训练。
具体分析本文采用的aiSim仿真器,其基于自研渲染引擎,在底层架构上实现了对真实物理过程的系统化映射。此外采用融合式渲染架构,将光栅化的高效性、光线追踪的物理精度以及神经渲染在细节表达上的优势相结合,在复杂光照变化及雨、雾、雪等极端环境下,仍可保持像素级物理一致性,为感知模型提供高置信度输入。
在此基础上,aiSim又进一步实现了从像素级到信号级的确定性建模。无论是相机中的成像噪声、景深与运动模糊,还是激光雷达与毫米波雷达中的光束发散、多径效应与材质反射特性,均基于物理机理进行建模,使生成数据在统计特性与分布形态上高度接近真实传感器输出。
因此可以说,aiSim为大规模、高真实性虚拟数据集合成提供了可靠基础,有效支撑感知算法在复杂场景下的快速迭代与验证。
05 结语
总结来看,自动驾驶的下半场,本质上是数据规模与数据质量的角逐。在摩尔定律失效、Scaling Laws主导的今天,高保真仿真技术已成为打破数据瓶颈的最优解。
康谋通过aiSim仿真平台、aiSim2nuScenes自动化工具链以及SimData数据集的扎实落地,向行业展示了一条清晰的技术路径:通过引入物理级高保真的虚拟数据,不仅能够大幅降低数据采集与标注的边际成本,规避极端工况测试的道德与安全风险,更能通过“虚实结合”的训练策略,显著提升感知模型在复杂现实世界中的表现。
随着端到端大模型与世界模型的兴起,对高质量合成数据的需求将呈指数级增长。可以看到,aiSim提供的高保真虚拟世界,正在成为连接算法代码与物理现实的坚实桥梁,加速自动驾驶从“有限场景”迈向“全域通达”!
-
数据采集
+关注
关注
42文章
8456浏览量
121567 -
仿真
+关注
关注
55文章
4581浏览量
138978 -
数据集
+关注
关注
4文章
1243浏览量
26346 -
端到端
+关注
关注
0文章
53浏览量
10887 -
自动驾驶
+关注
关注
795文章
15102浏览量
182281
发布评论请先 登录
高阶智驾下半场,谁主沉浮?
SimData:基于aiSim的高保真虚拟数据集生成方案

企业拿什么迎战互联网下半场
如何做好高复杂PCB与PCBA?
2018年互联网下半场即将迎来的三大聚焦点
“IPTV下半场该如何顺势而为”多维度探讨
云数据库之战下半场,腾讯云数据库打的更有侵略性
当前自动驾驶技术发展是否进入到“下半场”
自动驾驶下半场竞争的关键技术

免费获取 | SimData高保真虚拟数据集开源发布,兼容nuScenes,开箱即用!
SimData深度解析:高保真虚拟数据集的构建与评测



评论