 实测2778MB/s,AMP核间通信“快如闪电”,瑞芯微RK3576
实测2778MB/s,AMP核间通信“快如闪电”,瑞芯微RK3576

在多核异构SoC处理器中,核间数据的传输带宽直接决定了系统整体性能。传统通信方案存在数据“拷贝开销大”、“带宽受限”等瓶颈,高效的核间通信一直是开发者面临的挑战。
今天带大家看看RK3576的AMP核间通信——共享内存方案,具有“零拷贝”、“高带宽”的显著优势,直接解决用户痛点,下面用实测数据说话!

▍共享内存方案优势
零拷贝“共享内存方案”能够让不同核心直接访问同一块物理内存,实现了真正的零拷贝传输,大幅降低了数据传输延迟。
数据量大“共享内存方案”的共享内存区域大小,可根据实际需求灵活配置,从几十MB到几百MB都可以,能够满足各种大数据量传输需求。
配合RPMsgMaster Core与Remote Core在完成共享内存的读写操作后,可通过RPMsg通知对方进行数据处理,实现了高效、可靠的核间通信。RK3576处理器A72、A53与M0核间通信中的RPMsg消息包的发送耗时与时延,实测可做到2us,详见下图:

▍实测带宽确实惊人
为了验证共享内存方案的实际性能表现,我们针对“用户内存空间↔共享内存空间”的读写场景,分别测试了DMA、NEON、CPU三种主流内存拷贝方式的读写带宽。

可以从上面看到:
DMA方式读写带宽性能最优,实测读带宽高达2778MB/s,写带宽2760MB/s,表现稳定。
NEON和CPU方式在写带宽上表现出色,但读带宽就偏低。这是由于写操作依托“写合并(Write-Combining)”机制,能将多个小写操作合并为单次、大数据传输,减少总线事务切换,因此写带宽表现亮眼。而读操作无法合并,每次读取需等待内存响应,导致读带宽显著偏低。
▍拷贝方式怎么选
DMA、NEON、CPU这3种拷贝方式各有优劣,实际开发中无需盲目追求“最高带宽”,应根据使用场景、资源占用情况进行选择,这才是最优解。DMA:性能王者,CPU零负担当传输数据量大、对带宽要求高时,DMA是最佳选择。它由专用硬件控制器执行数据搬运,不占用CPU资源。NEON:无DMA时的备选,CPU同样零负担一般处理器的DMA控制器资源有限,可能早已被占用。在没有多余DMA控制器时,NEON方式是另一个不错的选择,它是CPU的辅助核,同样不占用CPU资源,利用CPU的单指令多数据流技术,实现并行数据搬运。CPU:实现最简单,但需消耗CPU资源对于小数据量传输,或者在对性能要求不高的简单应用中,标准的CPU拷贝是最直接的选择。它实现简单,不需额外的硬件资源支持,适合轻量级任务。但由于它会占用CPU资源,因此复杂应用时不见得是最适合的方案。
审核编辑 黄宇
-
瑞芯微
+关注
关注
27文章
909浏览量
54753 -
Amp
+关注
关注
0文章
103浏览量
48699
发布评论请先 登录
维护成本直降!RK3576核心板/开发板OTA升级功能详解,触觉智能瑞芯微RK方案商

AI硬件选型必看!瑞芯微RV1126B/RK3562/RK3576/RK3588之NPU性能实测对比

瑞芯微RK3576基于Linux平台CUPS架构标准打印机适配实战教程

RK3576开发板OpenGL性能大起底,这数据我真的服了

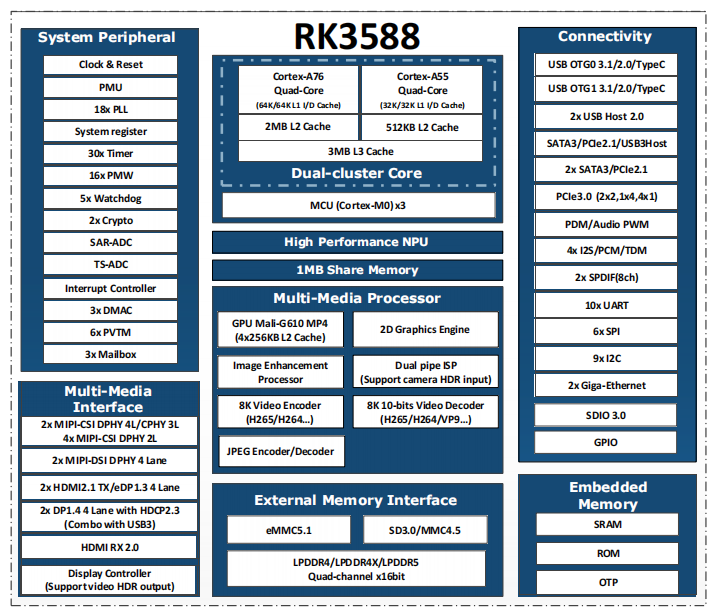
瑞芯微RK3588与RK3576技术参数详解
瑞芯微RK3576平台FFmpeg硬件编解码移植及性能测试实战攻略 触觉智能RK3576开发板演示

基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
瑞芯微RK3576与RK3576S有什么区别,性能参数配置与型号差异解析

RK这2款旗舰芯片RK3588 PK RK3576,谁是最优选
全国产!瑞芯微 RK3576 ARM 八核 2.2GHz 工业开发板—Linux应用开发手册
全国产!瑞芯微 RK3576 ARM 八核 2.2GHz 工业开发板—Linux开发环境搭建

全国产!瑞芯微 RK3576 ARM 八核 2.2GHz 工业开发板—Linux系统使用手册
全国产!瑞芯微 RK3576 ARM 八核 2.2GHz 工业开发板—LVGL应用开发案例



评论