 如何用OpenVINO™部署PP-StructureV3到Intel GPU上
如何用OpenVINO™部署PP-StructureV3到Intel GPU上

一,RapidDoc系统概述
RapidDoc是一个轻量级、专注于文档解析的开源框架,支持OCR、版面分析、公式识别、表格识别和阅读顺序恢复等多种功能。框架基于 Mineru 二次开发,移除 VLM,专注于 Pipeline 产线下的高效文档解析,在 CPU 上也能保持不错的解析速度。本文章所使用的核心模型主要来源于 PaddleOCR 的 PP-StructureV3 系列(OCR、版面分析、公式识别、阅读顺序恢复,以及部分表格识别模型),并已全部转换为 ONNX 格式,支持在 CPU/GPU 上高效推理。

![]()
二,开始部署
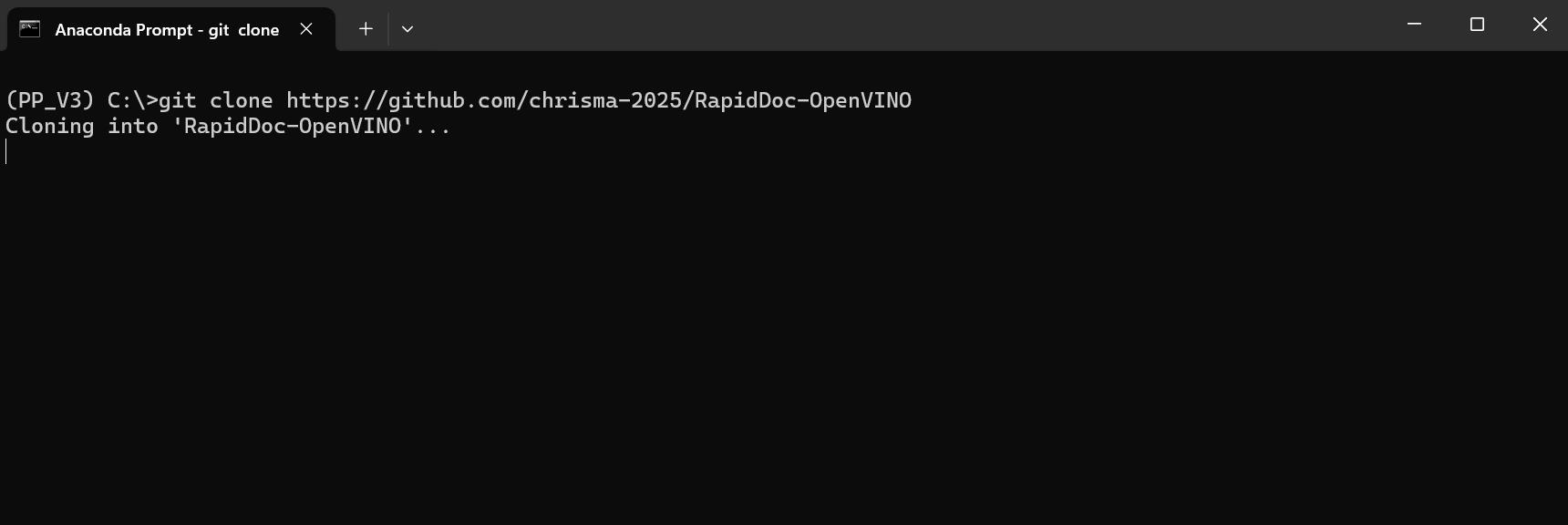
首先,在命令提示行执行命令下载源文件。
git clone https://github.com/chrisma-2025/RapidDoc-OpenVINO
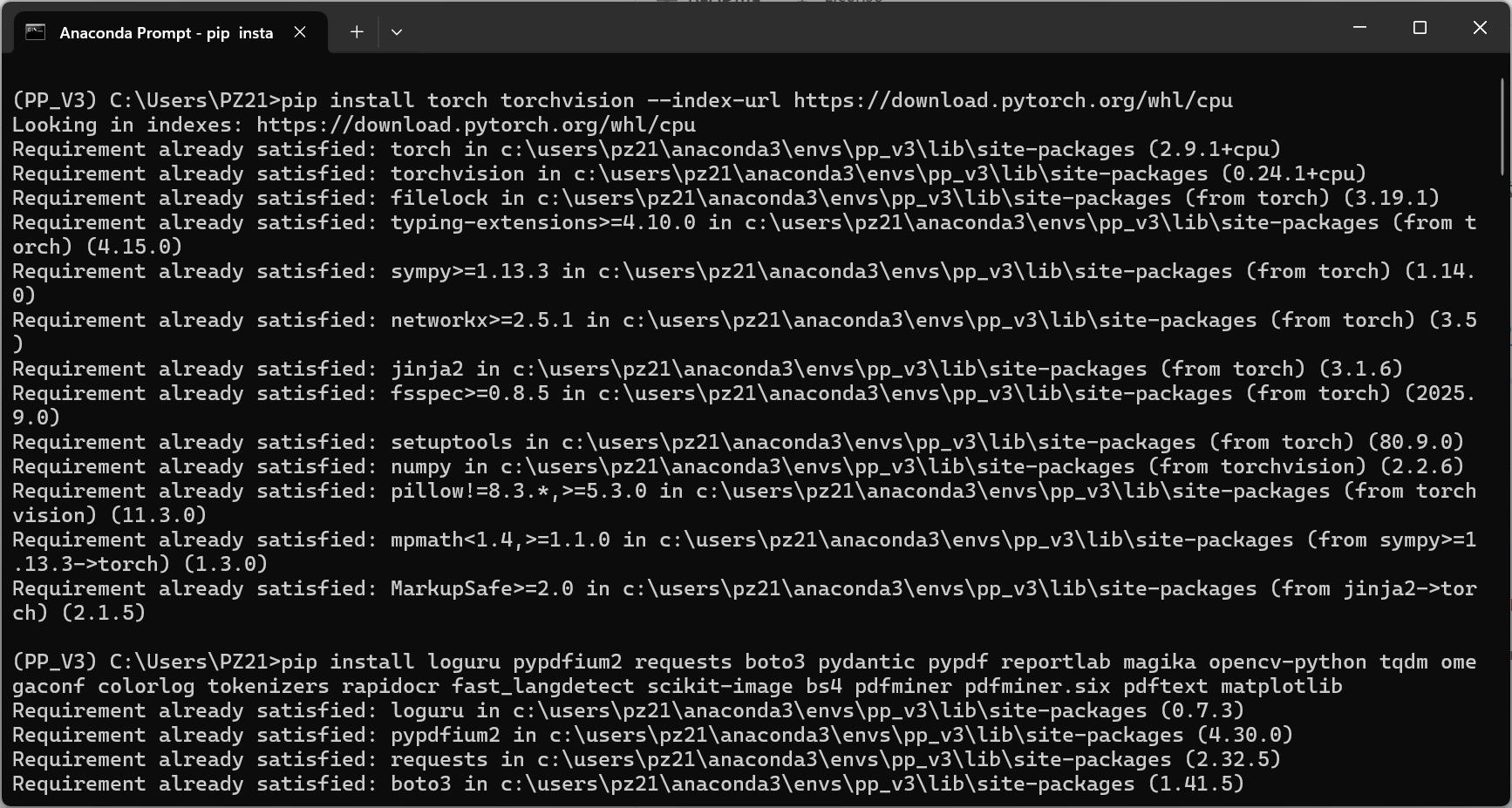
然后再执行命令,安装python依赖包
pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu
pip install loguru pypdfium2 requests boto3 pydantic pypdf reportlab magika opencv-python tqdm omegaconf colorlog tokenizers rapidocr fast_langdetect scikit-image bs4 pdfminer pdfminer.six pdftext matplotlib
pip install onnxruntime-openvino onnxruntime
pip install --pre openvino --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
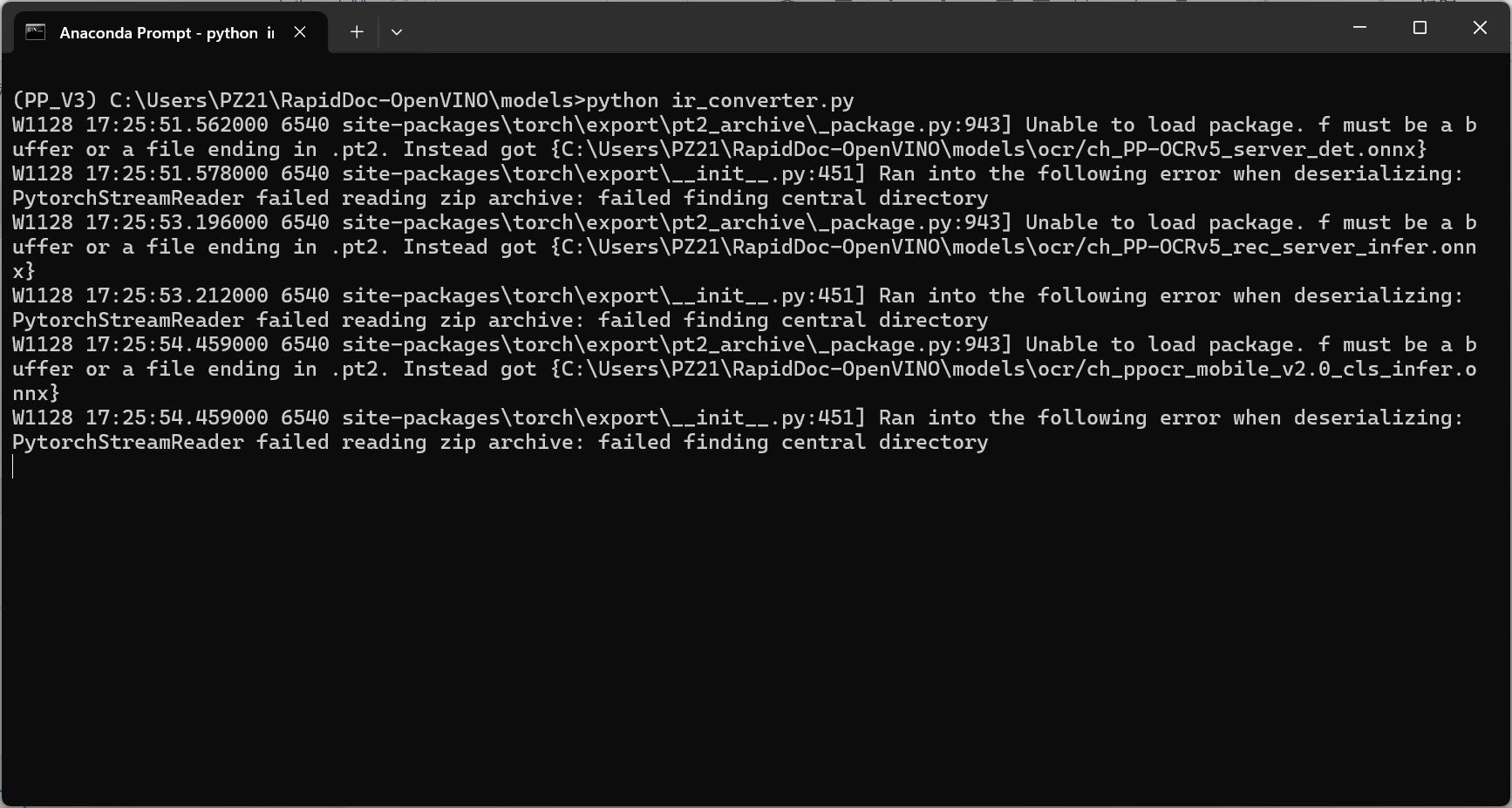
下载OCR模型并使用指令将模型转换为OpenVINO™支持的IR文件
cd RapidDoc-OpenVINO/models
wget https://www.modelscope.cn/models/RapidAI/RapidOCR/resolve/master/onnx/PP-OCRv5/det/ch_PP-OCRv5_server_det.onnx -P ocr
wget https://www.modelscope.cn/models/RapidAI/RapidOCR/resolve/master/onnx/PP-OCRv5/rec/ch_PP-OCRv5_rec_server_infer.onnx -P ocr
wget https://www.modelscope.cn/models/RapidAI/RapidOCR/resolve/master/onnx/PP-OCRv4/cls/ch_ppocr_mobile_v2.0_cls_infer.onnx -P ocr
下载完成后运行:python ir_converter.py
三,运行Demo
执行命令返回文件根目
cd ..
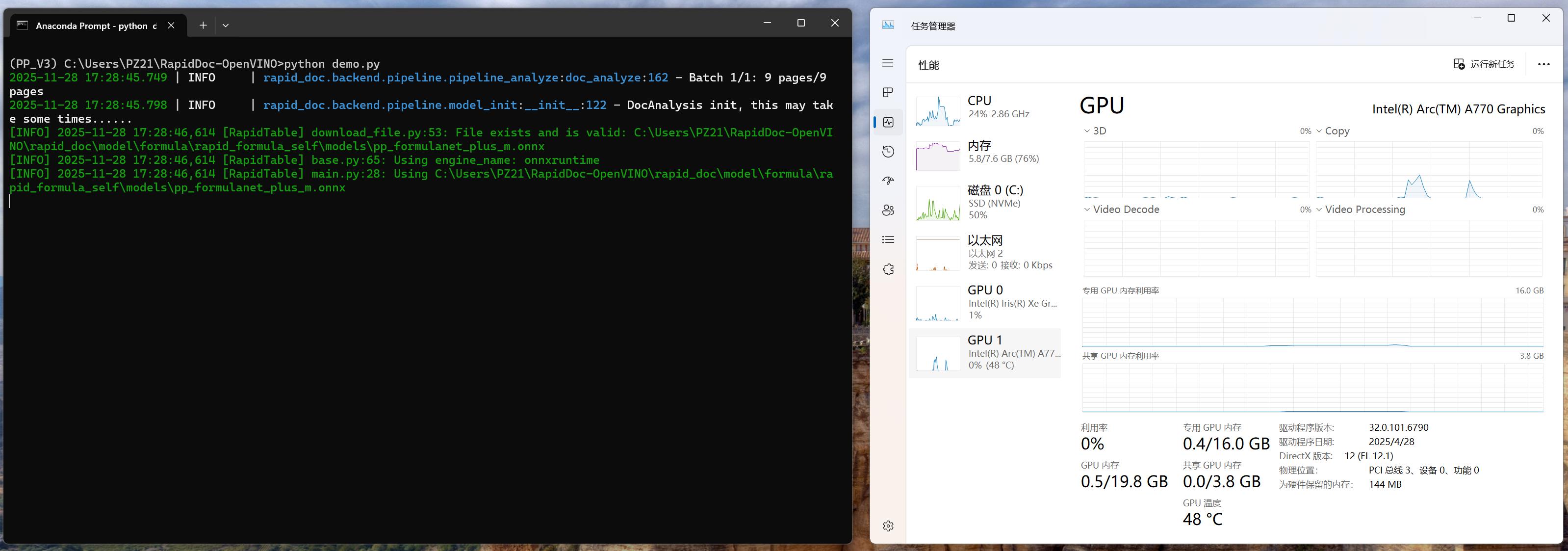
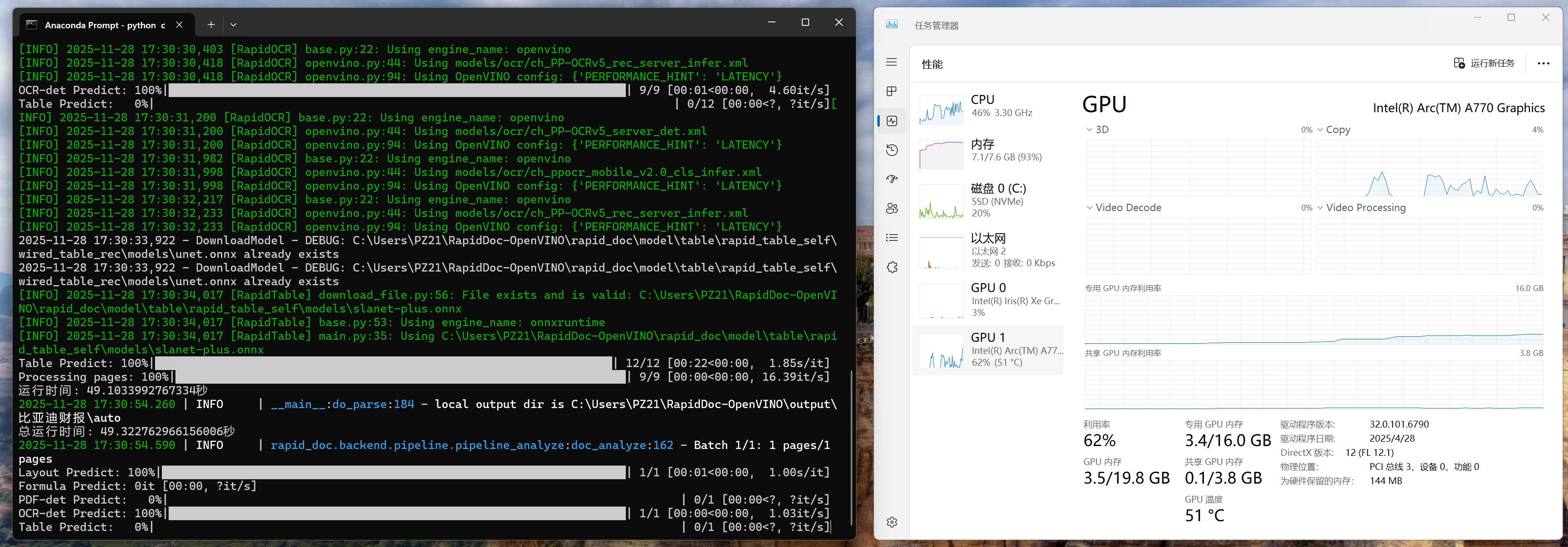
Python demo.py
四,总结
本文完整演示了基于RapidDoc 框架的文档解析工具落地流程:先克隆源码、安装 PyTorch/OpenVINO 等依赖,再下载 PP-OCRv5 系列 ONNX 模型并尝试转换为 IR 文件,最后通过demo.py验证部署效果。
实际运行中,Intel GPU(Arc A770、Iris Xe Graphics)可正常调用,稳定完成多页面文档的 OCR、版面分析等任务,此次部署既验证了 RapidDoc 框架在轻量化工单解析场景的实用性,也证实了 OpenVINO™ 对 Inte GPU 的适配性,为后续工业、金融等领域的文档智能解析需求提供了可复用的技术方案。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
intel
+关注
关注
19文章
3514浏览量
191814 -
OpenVINO
+关注
关注
0文章
118浏览量
829
发布评论请先 登录
相关推荐
热点推荐
Intel OpenVINO™ Day0 实现阿里通义 Qwen3 快速部署
本文将以 Qwen3-8B 为例,介绍如何利用 OpenVINO 的 Python API 在英特尔平台(GPU, NPU)Qwen3 系列模型。
基于C#和OpenVINO™在英特尔独立显卡上部署PP-TinyPose模型
和 OpenVINO,将 PP-TinyPose 模型部署在英特尔独立显卡上。 1.1 PP-TinyPose 模型简介
如何使用OpenVINO C++ API部署FastSAM模型
FastSAM 模型 | 开发者实战》,在该文章中我们向大家展示了基于 OpenVINO Python API 的基本部署流程。在实际部署过程中会考虑到由效率问题,使得我们可能更倾向
使用OpenVINO C# API轻松部署飞桨PP-OCRv4模型
?本文从零开始详细介绍整个过程。 一,什么是PP-OCRv4模型? PP-OCRv4是 PaddleOCR工具库 的PP-OCR系列模型中,当前性能最优的一个。它在前代模型(PP-OCRv
用ROCm部署PP-StructureV3到AMD GPU上
作者:AVNET 李鑫杰 我们在上一篇文章中介绍了ROCm+PP-OCRv5,为实现在AMD计算平台上完成复杂文档的端到端智能解析,本文基于ROCm软件栈,提供一套完整的PP-StructureV3
OpenVINO™检测到GPU,但网络无法加载到GPU插件,为什么?
OpenVINO™安装在旧的 Windows 10 版本 Windows® 10 (RS1) 上。
已安装 GPU 驱动程序版本 25.20.100.6373,检测到 GPU,但网络
发表于 03-05 06:01
是否可以使用OpenVINO™部署管理器在部署机器上运行Python应用程序?
使用 OpenVINO™部署管理器创建运行时软件包。
将运行时包转移到部署机器中。
无法确定是否可以在部署机器上运行 Python 应用程
发表于 03-05 08:16
如何部署OpenVINO™工具套件应用程序?
编写代码并测试 OpenVINO™ 工具套件应用程序后,必须将应用程序安装或部署到生产环境中的目标设备。
OpenVINO™部署管理器指南包
发表于 03-06 08:23
无法在GPU上运行ONNX模型的Benchmark_app怎么解决?
在 CPU 和 GPU 上运行OpenVINO™ 2023.0 Benchmark_app推断的 ONNX 模型。
在 CPU 上推理成功,但在
发表于 03-06 08:02
为什么无法在GPU上使用INT8 和 INT4量化模型获得输出?
安装OpenVINO™ 2024.0 版本。
使用 optimum-intel 程序包将 whisper-large-v3 模型转换为 int 4 和 int8,并在 GPU
发表于 06-23 07:11
无法使用OpenVINO™在 GPU 设备上运行稳定扩散文本到图像的原因?
在OpenVINO™ GPU 设备上使用图像大小 (1024X576) 运行稳定扩散文本到图像,并收到错误消息:
RuntimeError: Exception from
发表于 06-25 06:36
【大联大世平Intel®神经计算棒NCS2试用申请】在树莓派上联合调试Intel®神经计算棒NCS2部署OpenVINO
项目名称:在树莓派上联合调试Intel®神经计算棒NCS2部署OpenVINO试用计划:1, 我是树莓派资深开发者,有好几个树莓派,2,精通Ubuntu 16.04.3 LTS(64位
发表于 06-30 16:06
GPU上OpenVINO基准测试的推断模型的默认参数与CPU上的参数不同是为什么?
在 CPU 和 GPU 上推断出具有 OpenVINO™ 基准的相同模型:
benchmark_app.exe -m model.xml -d CPU
benchmark_app.exe -m
发表于 08-15 06:43
使用OpenVINO™ 部署PaddleSeg模型库中的DeepLabV3+模型
下的DeepLabV3+路面语义分割模型转换为OpenVINO 工具套件的IR模型并且部署到CPU上。 为了使本文拥有更广的受众面,

使用OpenVINO Model Server在哪吒开发板上部署模型
OpenVINO Model Server(OVMS)是一个高性能的模型部署系统,使用C++实现,并在Intel架构上的部署进行了优化,使用



评论