 架构/算力/软件/应用全面突破,安谋科技Arm China用“周易”X3破局端侧AI
架构/算力/软件/应用全面突破,安谋科技Arm China用“周易”X3破局端侧AI

电子发烧友网报道(文/吴子鹏)当前,全球端侧AI市场正呈现爆发式增长。根据弗若斯特沙利文的统计数据,全球端侧AI市场规模预计将从2024年的3219亿元增长至2029年的12230亿元,复合年增长率高达39.6%。然而,当大模型从云端向端侧渗透,算力瓶颈、能效矛盾、开发门槛成为制约端侧AI行业前进的三重枷锁。
为帮助行业破解这一难题,国内领先的芯片IP设计与服务提供商安谋科技(中国)有限公司(以下简称“安谋科技Arm China”)于近日正式发布了新一代NPU IP——“周易”X3。该产品采用专为大模型打造的最新DSP+DSA架构,不仅聚焦硬件性能的飞跃,更通过软硬协同与生态开放,重新定义了端侧AI计算效率,为基础设施、智能汽车、移动终端、智能物联网四大领域带来前所未有的AI计算体验。

安谋科技Arm China产品研发副总裁刘浩表示:“在‘All in AI’产品战略的指引下,我们将持续加大投入,以前瞻性视野整合顶尖研发资源,秉持开放合作理念,为生态伙伴提供业界领先的从硬件、软件到服务的端到端解决方案,全力赋能伙伴的产品创新和商业化落地。”

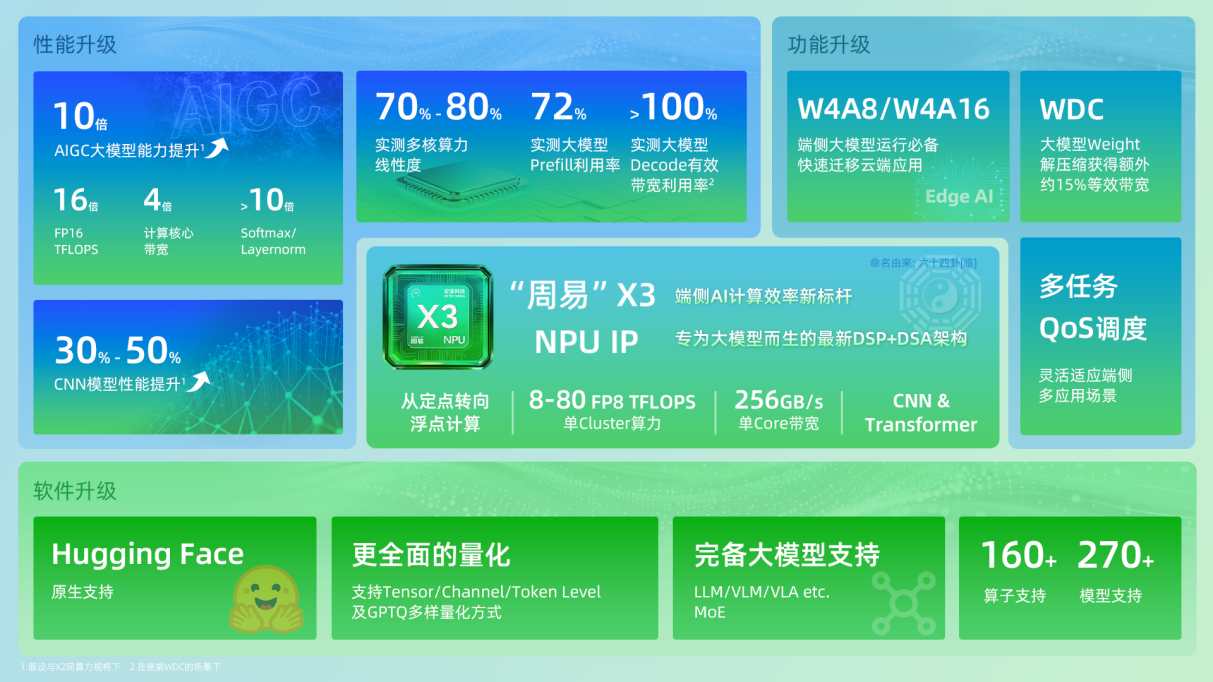
为解决这些产业难题,“周易”X3 NPU IP应运而生,旨在打造端侧AI计算效率的新标杆。“周易”X3采用专为大模型打造的DSP+DSA融合架构,突破了传统NPU架构的局限——纯DSA架构虽能高效处理固定算法,但面对大模型的灵活迭代易陷入“硬管道”困境,而DSP的加入有效弥补了通用计算的短板。同时,“周易”X3的架构也兼顾了CNN与Transformer的通用架构,支持全算力类型并增强浮点运算FLOPS,助力实现从定点到浮点计算的关键转变。
在架构创新方面,“周易”X3还集成了自研解压硬件WDC,通过软件无损压缩+硬件解压的方式,可额外获得15%-20%的等效带宽;配合W4A8/W4A16计算加速模式,有效破解了端侧大模型的带宽消耗难题;通过集成AI专属硬件引擎AIFF(AI Fixed-Function)与专用硬化调度器,将CPU负载压低至0.5%,确保多任务场景下的低延迟响应;支持int4/int8/int16/int32/fp4/fp8/fp16/bf16/fp32多精度融合计算及强浮点计算,可灵活适配智能手机边缘部署、AI PC推理、智能汽车等从传统CNN到前沿大模型的数据类型需求,实现性能与能效的平衡。
谈及W4A8/W4A16计算加速模式创新,安谋科技Arm China产品总监鲍敏祺形象地比喻道:“W4A8/W4A16是混合量化策略,旨在平衡模型精度与计算效率,通过降低权重的比特数来减少显存占用,同时保持激活值较高的精度以最小化推理误差。如果W4A16计算是1秒输出,那么到了W4A8就可能是600毫秒输出。因为在保证精度的前提下,‘A’(即Activation,激活值)的数值降低了,就相当于算力翻倍。当然,端侧需优先定义可用模型,再解决系统问题——早期端侧聚焦1B-3B模型,但7B模型才具备实用价值。当端侧要承载更大参数规模的AI模型(比如从3B扩大到7B),‘W’(即Weight,权重)也要随之降低,安谋科技Arm China也在协同合作伙伴着力优化W2A8,以支持7B模型在手机等终端部署,而保证精度是前提。”

这些创新为“周易”X3带来了显著的性能提升:“周易”X3单Cluster支持8-80 FP8 TFLOPS算力灵活配置,单Core带宽高达256GB/s。相较于“周易”X2产品,“周易”X3的CNN模型性能提升30%~50%,多核算力线性度达到70%~80%;在同算力规格下,AIGC大模型能力较上一代产品实现10倍增长。实测数据显示,在Llama2 7B大模型中,Prefill阶段算力利用率达72%,Decode阶段在自研解压硬件WDC加持下,有效带宽利用率超100%。
对此,鲍敏祺指出:“‘周易’X3遵循‘软硬协同、全周期服务与成就客户’的产品准则,提供从硬件、软件到售后服务的全链路支持,以前瞻性设计、专业团队交付与深度服务投入,全面助力客户产品成功与商业化落地。”
Compass AI软件平台实现了从模型导入到部署的端到端支持,兼容TensorFlow、ONNX、PyTorch等主流AI框架,覆盖超160种算子与270多种模型,提供开箱即用的Model Zoo。其创新的Hugging Face模型“一键部署”功能,让开发者无需复杂适配即可实现大模型的端侧落地,大幅缩短开发周期。
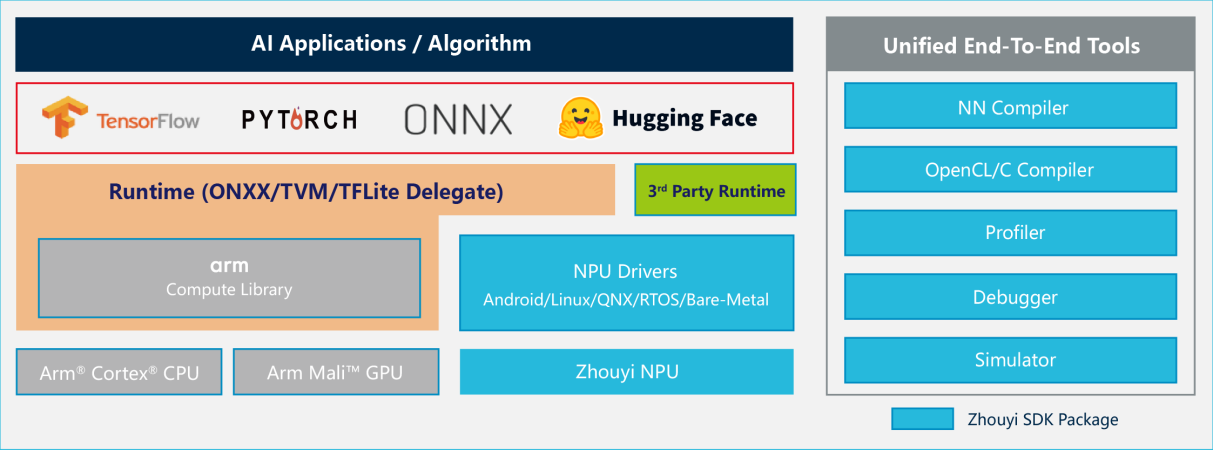
针对大模型的动态特性,Compass AI平台具备业界领先的动态Shape支持能力,可高效处理任意长度输入序列;同时支持GPTQ等主流量化方案及Tensor/Channel/Token Level多样量化方式,配合Bit精度软件仿真平台,让开发者在平衡性能与精度时更具灵活性。丰富的调试工具与白盒部署能力,更满足了深度开发场景下的定制需求。
同时,安谋科技Arm China深知生态的核心在于“开放”,已将Compass AI平台的Parser、Optimizer、Linux Driver等核心组件开放,成为行业内少数开放量化能力的厂商。通过支持DSL算子编程语言,客户可自主开发自定义算子或打造专属模型编译器,实现差异化创新。这种“开放”的策略,既降低了中小开发者的入门门槛,也为大客户提供了深度定制的空间。
安谋科技Arm China NPU产品线负责人兼首席架构师舒浩博士总结道:“‘周易’X3的产品优势,源于通用、灵活、高效且软硬协同的系统架构设计,这一设计使其兼具广泛的行业适用性与灵活的边端侧AI应用场景匹配能力。”

在基础设施领域,其支持CNN与大模型的混合加速,为边缘计算节点与加速卡提供核心算力,成为数据中心算力的重要补充;在智能汽车领域,“周易”X3既可以在ADAS系统中为自动泊车等辅助驾驶功能提供高性能AI算力支持,也可以在IVI(车载信息娱乐系统)中支持基于语音与车内外视频图像输入的智能互动;在移动终端方面,可在AI PC与AI手机上实现超分渲染与AI Agent应用,让端侧多模态交互更流畅;在智能物联网领域,通过本地AI推理提升智能网关、IPC等设备的响应速度,兼顾实时性与隐私保护。
从产品家族演进来看,“周易”系列已形成从Z1到X3的完整布局,覆盖从入门级AIoT到高端智能设备的全场景需求。现场展示的DeepSeek-R1-Distill-Qwen-1.5B文生文、Stable Diffusion v1.5文生图等Demo,直观呈现了端侧大模型的落地效果。
为帮助行业破解这一难题,国内领先的芯片IP设计与服务提供商安谋科技(中国)有限公司(以下简称“安谋科技Arm China”)于近日正式发布了新一代NPU IP——“周易”X3。该产品采用专为大模型打造的最新DSP+DSA架构,不仅聚焦硬件性能的飞跃,更通过软硬协同与生态开放,重新定义了端侧AI计算效率,为基础设施、智能汽车、移动终端、智能物联网四大领域带来前所未有的AI计算体验。
安谋科技Arm China产品研发副总裁刘浩表示:“在‘All in AI’产品战略的指引下,我们将持续加大投入,以前瞻性视野整合顶尖研发资源,秉持开放合作理念,为生态伙伴提供业界领先的从硬件、软件到服务的端到端解决方案,全力赋能伙伴的产品创新和商业化落地。”
安谋科技Arm China产品研发副总裁刘浩
技术突破:DSP+DSA架构实现端侧AI计算效能跃升
随着生成式AI(AIGC)和大模型技术的快速发展,智能手机、AI PC、智能汽车等端侧设备对AI能力的需求正呈爆发式增长。然而,端侧AI的核心痛点在于“有限资源承载复杂计算”。此外,在半导体IP领域,“面向未来5年的产品方向进行前瞻布局”已成为行业共识,这让IC设计人员在定义下一代端侧AI计算芯片时面临极大挑战。为解决这些产业难题,“周易”X3 NPU IP应运而生,旨在打造端侧AI计算效率的新标杆。“周易”X3采用专为大模型打造的DSP+DSA融合架构,突破了传统NPU架构的局限——纯DSA架构虽能高效处理固定算法,但面对大模型的灵活迭代易陷入“硬管道”困境,而DSP的加入有效弥补了通用计算的短板。同时,“周易”X3的架构也兼顾了CNN与Transformer的通用架构,支持全算力类型并增强浮点运算FLOPS,助力实现从定点到浮点计算的关键转变。
在架构创新方面,“周易”X3还集成了自研解压硬件WDC,通过软件无损压缩+硬件解压的方式,可额外获得15%-20%的等效带宽;配合W4A8/W4A16计算加速模式,有效破解了端侧大模型的带宽消耗难题;通过集成AI专属硬件引擎AIFF(AI Fixed-Function)与专用硬化调度器,将CPU负载压低至0.5%,确保多任务场景下的低延迟响应;支持int4/int8/int16/int32/fp4/fp8/fp16/bf16/fp32多精度融合计算及强浮点计算,可灵活适配智能手机边缘部署、AI PC推理、智能汽车等从传统CNN到前沿大模型的数据类型需求,实现性能与能效的平衡。
谈及W4A8/W4A16计算加速模式创新,安谋科技Arm China产品总监鲍敏祺形象地比喻道:“W4A8/W4A16是混合量化策略,旨在平衡模型精度与计算效率,通过降低权重的比特数来减少显存占用,同时保持激活值较高的精度以最小化推理误差。如果W4A16计算是1秒输出,那么到了W4A8就可能是600毫秒输出。因为在保证精度的前提下,‘A’(即Activation,激活值)的数值降低了,就相当于算力翻倍。当然,端侧需优先定义可用模型,再解决系统问题——早期端侧聚焦1B-3B模型,但7B模型才具备实用价值。当端侧要承载更大参数规模的AI模型(比如从3B扩大到7B),‘W’(即Weight,权重)也要随之降低,安谋科技Arm China也在协同合作伙伴着力优化W2A8,以支持7B模型在手机等终端部署,而保证精度是前提。”
安谋科技Arm China产品总监鲍敏祺
这些创新为“周易”X3带来了显著的性能提升:“周易”X3单Cluster支持8-80 FP8 TFLOPS算力灵活配置,单Core带宽高达256GB/s。相较于“周易”X2产品,“周易”X3的CNN模型性能提升30%~50%,多核算力线性度达到70%~80%;在同算力规格下,AIGC大模型能力较上一代产品实现10倍增长。实测数据显示,在Llama2 7B大模型中,Prefill阶段算力利用率达72%,Decode阶段在自研解压硬件WDC加持下,有效带宽利用率超100%。
创新亮点:软硬协同,破解端侧AI开发痛点
“周易”X3不仅在硬件上实现突破,还配套了完善易用的“周易”Compass AI软件平台。通过“软硬一体”的协同设计,让开发者从“能用”到“好用”,显著提升开发部署效率,破解端侧AI行业“适配难、周期长、门槛高”的痛点。对此,鲍敏祺指出:“‘周易’X3遵循‘软硬协同、全周期服务与成就客户’的产品准则,提供从硬件、软件到售后服务的全链路支持,以前瞻性设计、专业团队交付与深度服务投入,全面助力客户产品成功与商业化落地。”
Compass AI软件平台实现了从模型导入到部署的端到端支持,兼容TensorFlow、ONNX、PyTorch等主流AI框架,覆盖超160种算子与270多种模型,提供开箱即用的Model Zoo。其创新的Hugging Face模型“一键部署”功能,让开发者无需复杂适配即可实现大模型的端侧落地,大幅缩短开发周期。
针对大模型的动态特性,Compass AI平台具备业界领先的动态Shape支持能力,可高效处理任意长度输入序列;同时支持GPTQ等主流量化方案及Tensor/Channel/Token Level多样量化方式,配合Bit精度软件仿真平台,让开发者在平衡性能与精度时更具灵活性。丰富的调试工具与白盒部署能力,更满足了深度开发场景下的定制需求。
同时,安谋科技Arm China深知生态的核心在于“开放”,已将Compass AI平台的Parser、Optimizer、Linux Driver等核心组件开放,成为行业内少数开放量化能力的厂商。通过支持DSL算子编程语言,客户可自主开发自定义算子或打造专属模型编译器,实现差异化创新。这种“开放”的策略,既降低了中小开发者的入门门槛,也为大客户提供了深度定制的空间。
安谋科技Arm China NPU产品线负责人兼首席架构师舒浩博士总结道:“‘周易’X3的产品优势,源于通用、灵活、高效且软硬协同的系统架构设计,这一设计使其兼具广泛的行业适用性与灵活的边端侧AI应用场景匹配能力。”
安谋科技Arm China NPU产品线负责人兼首席架构师舒浩博士
应用场景:从“可用”到“好用”的端侧AI革命
“周易”X3的产品定位精准覆盖基础设施、智能汽车、移动终端、智能物联网四大核心领域,将算力转化为实实在在的应用价值。在基础设施领域,其支持CNN与大模型的混合加速,为边缘计算节点与加速卡提供核心算力,成为数据中心算力的重要补充;在智能汽车领域,“周易”X3既可以在ADAS系统中为自动泊车等辅助驾驶功能提供高性能AI算力支持,也可以在IVI(车载信息娱乐系统)中支持基于语音与车内外视频图像输入的智能互动;在移动终端方面,可在AI PC与AI手机上实现超分渲染与AI Agent应用,让端侧多模态交互更流畅;在智能物联网领域,通过本地AI推理提升智能网关、IPC等设备的响应速度,兼顾实时性与隐私保护。
从产品家族演进来看,“周易”系列已形成从Z1到X3的完整布局,覆盖从入门级AIoT到高端智能设备的全场景需求。现场展示的DeepSeek-R1-Distill-Qwen-1.5B文生文、Stable Diffusion v1.5文生图等Demo,直观呈现了端侧大模型的落地效果。
结语
“周易”X3 NPU IP的发布,不仅是安谋科技Arm China技术实力的体现,更是端侧AI规模化部署的关键一步。通过软硬协同、前瞻布局和生态开放,它有望推动端侧AI从“功能实现”走向“场景深化”,为智能汽车、移动终端等领域注入新动力。随着行业对算力、精度和易用性需求的持续演化,安谋科技Arm China的战略实践或将成为中国AI芯片IP发展的参考范式。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
算力
+关注
关注
2文章
1676浏览量
16833 -
安谋科技
+关注
关注
0文章
129浏览量
8441
发布评论请先 登录
相关推荐
热点推荐
国产RK182X算力协处理器 + RK3588实测,大模型“极速流畅”
是瑞芯微针对端侧AI大模型推出的算力协处理器,它在性能与成本之间取得了出色平衡。它采用先进3D堆叠封装技术,内嵌2.5GB/5GB高带宽DR

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
310P芯片的底层架构,深度剖析这款产品的技术细节、算力门槛及其在实际产业落地中的真实价值。
一、176TOPS的产业门槛:为何这是边缘算力
发表于 03-10 14:19
OrangePi RV2 深度技术评测:RISC-V AI融合架构的先行者
OrangePi RV2是香橙派推出的一款基于RISC-V架构的AI开发板,搭载KY X1八核处理器。该板以“CPU 融合AI”为核心理念,内置2TOPS
发表于 03-03 20:19
应对端侧AI算力、内存、功耗“三堵墙”困境,安谋科技Arm China “周易”X3给出技术锦囊
AI大模型正加速从云端向边缘与端侧渗透,然而,算力、内存、功耗等却成了制约其规模化落地的“高墙”。专为AI计算而生的神经网络处理器(NPU)

迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读
昆仑芯K200作为云端AI加速卡,在K100架构基础上全面升级。其INT8算力达256 TOPS,配备16GB HBM内存与512GB/s带

安谋科技:端侧NPU技术创新,拉动AI算力落地引擎
X3 NPU IP以及生态建设、NPU发展趋势等话题。 图:安谋科技产品总监鲍敏祺 周易X3 NPU IP正当时

安谋科技“AI Arm CHINA”战略,链接全球生态与本土创新
的如医疗领域,新癌症药物研发速度较以往提升数十倍。”在11月20日ICCAD-Expo 2025上,安谋科技Arm China CEO 陈锋在演讲中如是说。 当前中国
安谋发布“周易”X3 NPU,破局AI算力,智绘未来蓝图
2025年11月13日,国内领先的芯片IP设计与服务提供商安谋科技Arm China,正式揭开了新一代NPU IP“周易”

矢量计算性能提升200%,安谋STAR-MC3赋能端侧AI革命
日益增长,推动芯片设计向更高能效、更强AI算力的方向演进。 就在近期,芯片IP设计与服务提供商安谋科技(
AI+MCU新选择,安谋科技“星辰”STAR-MC3问世
日前,安谋科技Arm China发布“星辰”STAR-MC3 CPU IP解析长图,清晰展现了该产品的五大亮点、核心应用领域与“星辰”CPU

安谋科技发布“星辰”STAR-MC3,提升MCU AI处理能力
电子发烧友网综合报道 2025年9月25日,安谋科技正式推出自主研发的第三代高能效嵌入式芯片IP——“星辰”STAR-MC3。该产品基于Arm®v8.1-M
什么是AI算力模组?
未来,腾视科技将继续深耕AI算力模组领域,全力推动AI边缘计算行业的深度发展。随着AI技术的不断演进和物联网应用的持续拓展,腾视科技的

什么是AI算力模组?
未来,腾视科技将继续深耕AI算力模组领域,全力推动AI边缘计算行业的深度发展。随着AI技术的不断演进和物联网应用的持续拓展,腾视科技的

2025端侧AI芯片爆发:存算一体、非Transformer架构谁主浮沉?边缘计算如何选型?
各位技术大牛好!最近WAIC 2025上端侧AI芯片密集发布,彻底打破传统算力困局。各位大佬在实际项目中都是如何选型的呢?
发表于 07-28 14:40
端侧AI需求大爆发!安谋科技发布新一代NPU IP,赋能AI终端应用
,汽车自动驾驶的本地决策,都依赖算力提升,这对端侧AI SoC的性能带来挑战,上游IP厂商的新品可以给SoC厂商带来最新助力。 7月9日,在上海张江举办的端



评论