 Hudi系列:Hudi核心概念之索引(Indexs)
Hudi系列:Hudi核心概念之索引(Indexs)

Hudi系列:Hudi核心概念(版本1.0)
•Hudi架构
◦一. 时间轴(TimeLine)s
▪1.1 时间轴(TimeLine)概念
▪1.2 Hudi的时间线由组成
▪1.3 时间线上的Instant action操作类型
▪1.4 时间线上State状态类型
▪1.5 时间线官网实例
◦二. 文件布局
◦三. 索引
3.1 简介
3.2 对比其它(Hive)没有索引的区别
3.2 多态索引
布隆过滤器
记录索引
表达索引
二级索引
3.3写入端的索引类型
3.4 全局索引与非全局索引
四. 表类型
4.1 COW:(Copy on Write)写时复制表
4.1.1 概念
4.1.2 COW工作原理
4.1.3 COW表对表的管理方式改进点
4.2 MOR:(Merge on Read)读时复制表
4.2.1 概念
4.2.2 MOR表工作原理
4.3 总结了两种表类型之间的权衡
五. 查询类型
5.1 Snapshot Queries
5.2 Incremental Queries
5.3 Read Optimized Query
简介
Hudi 中最基础的索引机制会一致地跟踪从给定键(记录键 + 可选分区路径)到文件 ID 的映射。其他类型的索引(如二级索引)都以此为基础构建。一旦将记录的第一个版本写入文件组,记录键和文件组/文件 ID 之间的映射就很少会发生变化。只有以删除 + 插入形式实现的集群或跨分区更新才会将记录键重新映射到不同的文件组。即便如此,给定的记录键在时间线上的任何完成时刻都只与一个文件组相关联。
对比其它(Hive)没有索引的区别
对于 Copy-On-Write表,索引可实现快速的插入/删除操作,因为无需与整个数据集连接来确定要重写哪些文件。对于Merge-On-Read 表,索引允许 Hudi 限制需要合并任何给定基础文件的更改记录数量。具体而言,给定基础文件仅需与属于该基础文件的记录的更新合并。相反,没有索引组件的Hive ACID需要将所有的基本文件与所有传入的更新/删除记录合并。
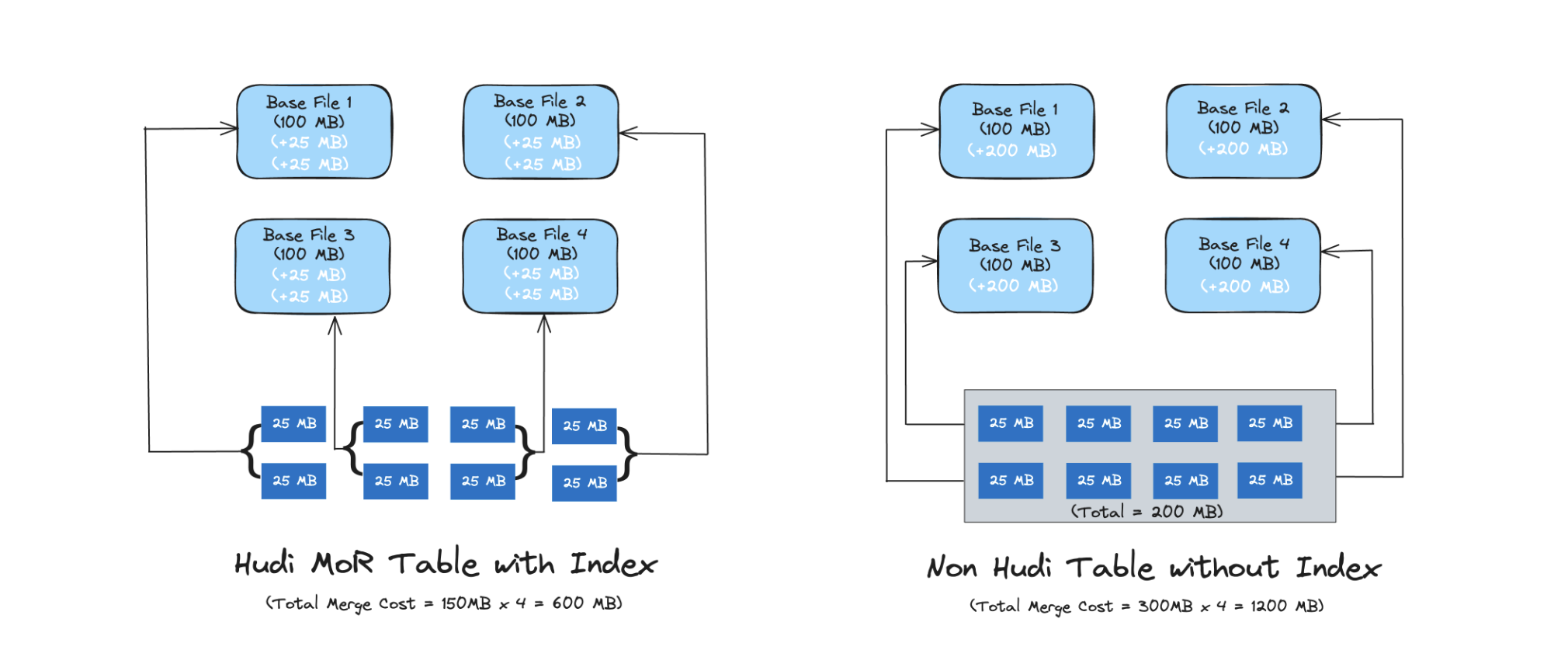
多态索引
Hudi 通过增强元数据表以合并新类型索引的能力来支持多模式索引,并辅以索引构建的异步机制。此增强功能支持元数据表中的一系列索引,从而显著提高了写入和读取表的效率。
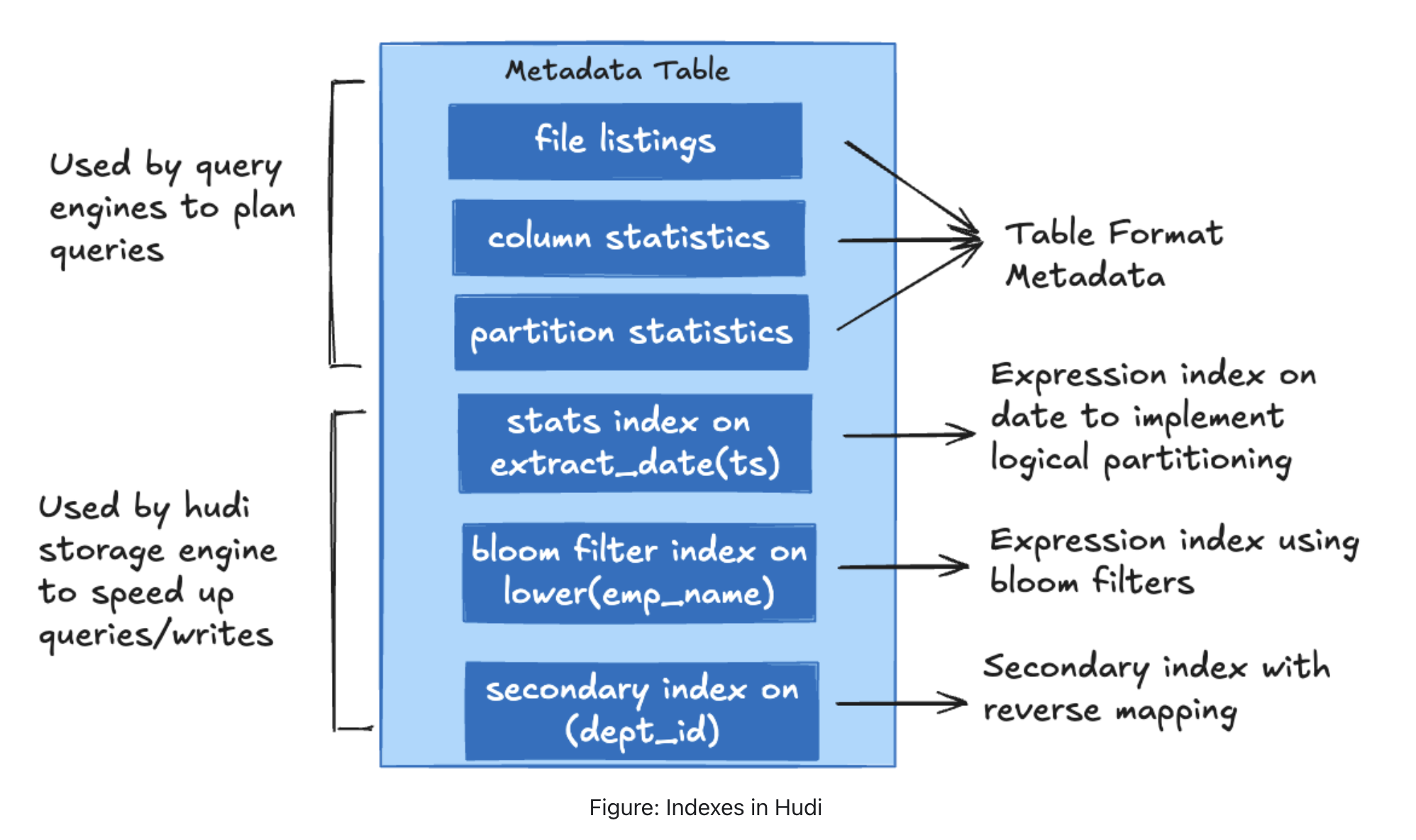
布隆过滤器Bloom Filters
Bloom filter 索引作为元数据表中的 bloom_filter 分区。此索引采用基于范围的修剪来修剪记录键的最小值和最大值,并采用基于 bloom 过滤器的查找来标记传入的记录。对于大型表,这涉及读取所有匹配数据文件的页脚以查找 bloom 过滤器,这在整个数据集随机更新的情况下成本可能很高。此索引集中存储所有数据文件的 bloom 过滤器,以避免直接从所有数据文件扫描页脚。
记录索引Record Indexes
记录索引作为元数据表中的 record_index 分区。包含记录键到位置的映射。记录索引是一个全局索引,在表的所有分区中强制键唯一性。此索引有助于比其他现有索引更快地定位记录,并且可以在索引查找主导写入延迟的大型部署中提供更快的加速。为了适应非常高的规模,它利用基于哈希的键空间分片。此外,在读取数据时,索引允许点查找,从而显着加快索引映射检索过程。
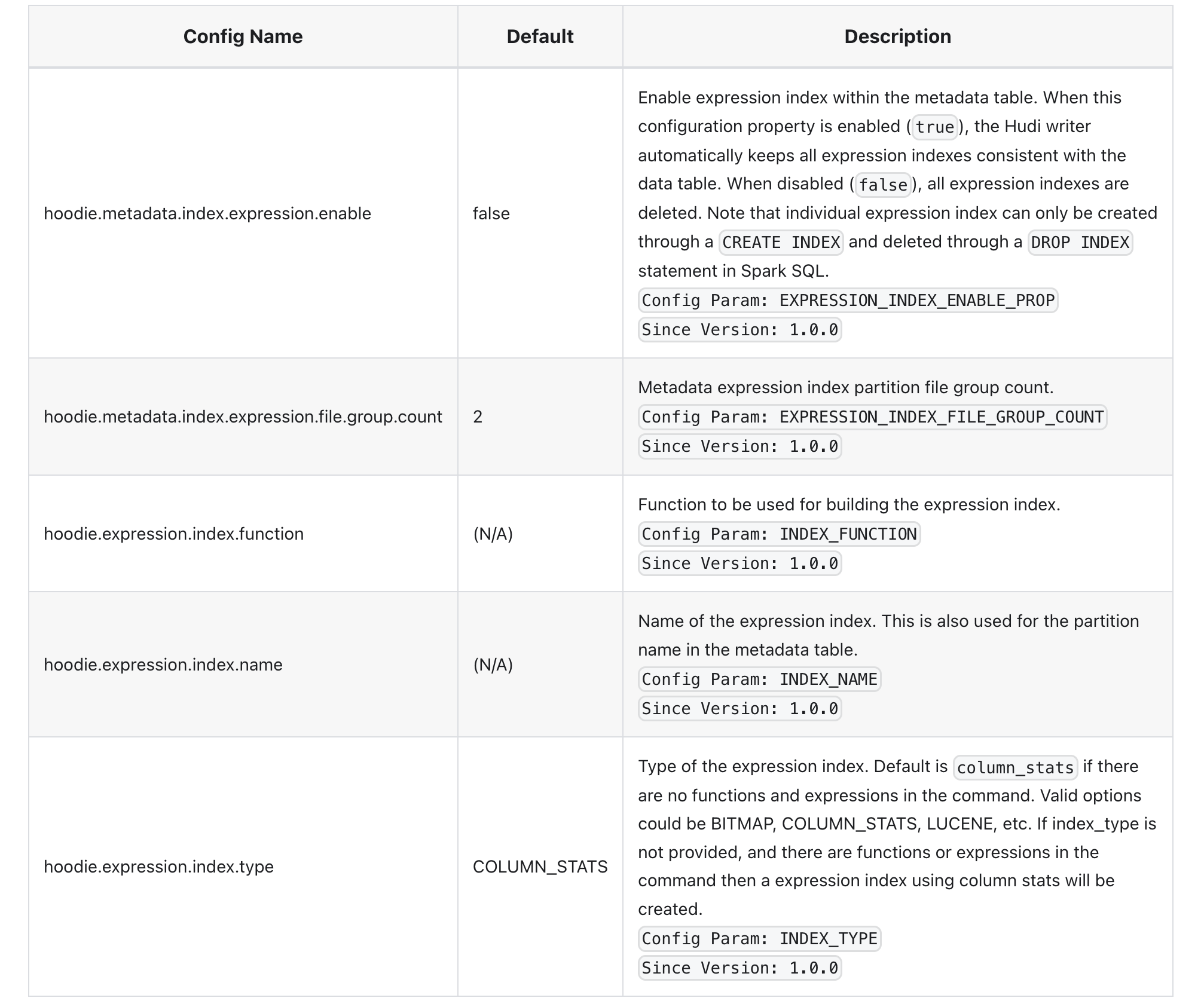
表达式索引Expression Index
Expression Index是列函数的索引。如果查询对列函数有谓词,则可以使用表达式索引来加速查询。表达式索引存储在元数据表下的 expr_index_ 前缀分区中(每个表达式索引一个)。可以使用 SQL 语法创建表达式索引。请在此处查看 SQL DDL 文档以了解更多详细信息。
以下是控制在写入器上启用表达式索引构建和维护的配置,后续会详细讲解,这个是1.0的新增的特性
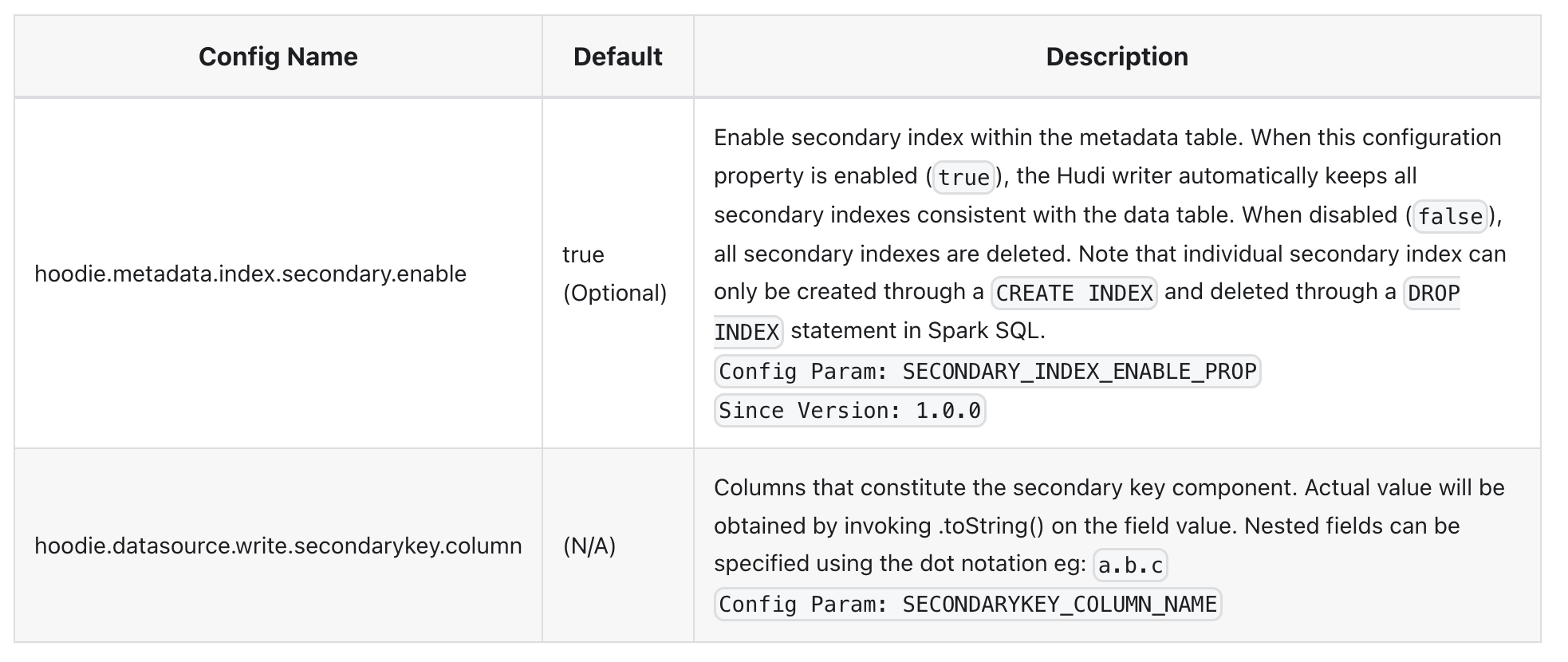
二级索引Secondary Index
Secondary Index允许用户在 Hudi 表中不属于记录键列的列上创建索引(对于记录键字段,Hudi 支持记录级索引)。二级索引可用于加速对记录键列以外的列使用谓词的查询。
以下是控制在写入器上启用二级索引构建和维护的配置,后续会详细讲解,这个是1.0的新增的特性
附加写入端索引 writer-side indexes
上面讨论的所有索引都可通过与元数据表集成供读取器/写入器使用。存储引擎还实现了索引机制,通过高效读取/连接/处理传入的输入记录,以对照存储在基础/日志文件本身中的信息(例如,存储在 parquet 文件页脚中的布隆过滤器)或智能数据布局(例如,存储桶索引)。
目前,Hudi 支持以下索引类型。Spark 引擎上的默认索引类型为 SIMPLE,Flink 和 Java 引擎上的默认索引类型为 INMEMORY。写入器可以使用 hoodie.index.type 配置选项选择其中一个选项。
| index类型 | 描述 |
|---|---|
| SIMPLE(Spark 引擎的默认索引类型) | 这是 Spark 引擎的标准索引类型。它执行传入记录与从存储在磁盘上的表中检索到的键的有效连接。它要求键在分区级别上是唯一的,这样它才能正常运行。 |
| RECORD_INDEX | 使用上一节中的记录索引作为写入端索引。 |
| BLOOM | 用由记录键生成的布隆过滤器,并可选择根据记录键的范围进一步缩小候选文件的范围。它要求键在分区级别上是唯一的,这样它才能正常工作。 |
| GLOBAL_BLOOM | 用由记录键创建的布隆过滤器,还可以通过使用记录键的范围来优化候选文件的选择。它要求键在表/全局级别上是唯一的,这样它才能正常工作。 |
| GLOBAL_SIMPLE | 对传入记录与从存储表中提取的键执行精益连接。它要求键在表/全局级别上是唯一的,这样它才能正常工作。 |
| HBASE | 通过 Apache HBase 中的外部表管理索引映射。 |
| INMEMORY(Flink 和 Java 的默认设置) | 使用 Spark 和 Java 引擎中的内存哈希图以及 Flink 中的 Flink 内存状态进行索引。 |
| BUCKET | 利用 bucket hashing 来识别存放记录的文件组,这在大规模情况下尤其有利。要选择 bucket 引擎的类型(即创建 bucket 的方法),请使用 hoodie.index.bucket.engine 配置选项。 |
| SIMPLE(默认) | 此索引为每个分区内的文件组使用固定数量的 bucket,这些 bucket 无法减小或增大大小。它适用于 COW 和 MOR 表。由于 bucket 数量不可改变,并且设计原则是将每个 bucket 映射到单个文件组,因此这种索引方法可能不适用于数据偏差较大的分区。 |
| CONSISTENT_HASHING | 此索引可容纳动态数量的 bucket,并具有调整 bucket 大小的功能,以确保每个 bucket 的大小合适。通过允许动态调整这些分区的大小,这解决了数据量大的分区中的数据偏差问题。因此,分区可以有多个大小合理的存储桶,这与 SIMPLE 存储桶引擎类型中每个分区的存储桶数量固定不同。此功能仅与 MOR 表兼容。 |
| 自带实现 | 您可以扩展此公共 API 并使用 hoodie.index.class 提供 SparkHoodieIndex 的子类(用于 Apache Spark 编写器)来实现自定义索引。 |
全局索引与非全局索引 Global and Non-Global Indexes
Bloom 和 simple index 都有全局选项,Base 索引本质上是一个全局索引
hoodie.index.type=GLOBAL_BLOOM
hoodie.index.type=GLOBAL_SIMPLE
1.全局索引:在全表的所有分区范围下强制要求键保持唯一,即确保对给定的键有且只有一个对应的记录。
2.非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依靠写入器为同一个记录的更删提供一致的分区路。
文献: https://hudi.apache.org/docs/overview
审核编辑 黄宇
-
索引
+关注
关注
0文章
60浏览量
10766
发布评论请先 登录




LV Nugget之数组索引的妙用
LabVIEW Nugget之数组索引的妙用
Hudi系列:Hudi核心概念之文件布局(Storage Layouts)





 工商网监
工商网监
评论