 MobileNetV2已经发布,它将为下一代移动视觉应用提供支持
MobileNetV2已经发布,它将为下一代移动视觉应用提供支持

去年,我们引入了面向移动设备设计的通用型计算机视觉神经网络系列MobileNetV1,支持分类和检测等功能。在个人移动设备上运行深度网络可以提升用户体验,允许随时随地访问,并且在安全性、隐私和能耗方面同样具有优势。随着可让用户与现实世界实时交互的新应用的出现,对更高效神经网络的需求也逐渐增加。
今天,我们很高兴地宣布,MobileNetV2已经发布,它将为下一代移动视觉应用提供支持。
MobileNetV2 在 MobileNetV1 的基础上进行了重大改进,并推动了移动视觉识别技术的发展,包括分类、对象检测和语义分割。MobileNetV2 作为TensorFlow-Slim 图像分类库的一部分发布,您也可以在Colaboratory中浏览 MobileNetV2。或者,也可以下载笔记本并在本地使用Jupyter操作。MobileNetV2 还将作为 TF-Hub 中的模块,预训练检查点位于github中。
MobileNetV2 以 MobileNetV1 [1] 的理念为基础,使用深度可分离卷积作为高效构建块。此外,V2 在架构中引入了两项新功能:1) 层之间的线性瓶颈,以及 2) 瓶颈之间的快捷连接。基本结构如下所示。
MobileNetV2 架构概览
蓝色块表示上面所示的复合卷积构建块
我们可以直观地理解为,瓶颈层对模型的中间输入和输出进行编码,而内层封装了让模型可以将低级概念(如像素)转换为高级描述符(如图像类别)的功能。最后,与传统的残差连接一样,快捷连接也可以提高训练速度和准确性。要详细了解技术细节,请参阅论文 “MobileNet V2:Inverted Residuals and Linear Bottlenecks”。
MobileNetV2 与第一代 MobileNet 相比有何不同?
总体而言,MobileNetV2 模型在整体延迟时间范围内可以更快实现相同的准确性。特别是在 Google Pixel 手机上,与 MobileNetV1 模型相比,新模型的运算数减少 2 倍,参数减少 30%,而速度提升 30-40%,同时准确性也得到提高。
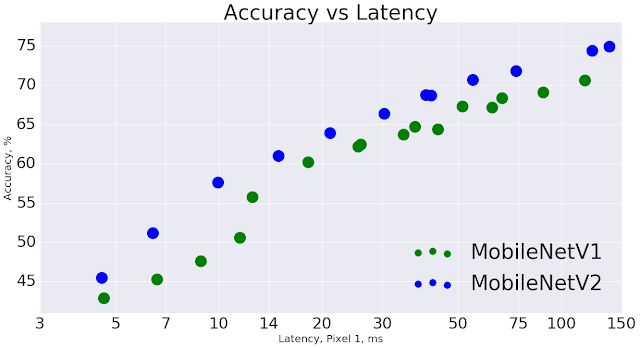
MobileNetV2 提高了速度(缩短了延迟时间)并提高了 ImageNet Top 1 的准确度
对于对象检测和分割而言,MobileNetV2 是非常有效的特征提取器。例如,在检测方面,与新引入的 SSDLite [2] 搭配使用时,在实现相同准确性的情况下,新模型的速度要比 MobileNetV1 快大约 35%。我们已在Tensorflow Object Detection API [4] 下开源该模型。

为了实现设备上语义分割,我们在近期宣布的 DeepLabv3 [3] 的简化版中采用 MobileNetV2 作为特征提取器。在采用语义分割基准PASCAL VOC 2012的条件下,新模型的性能与使用 MobileNetV1 作为特征提取器的性能相似,但前者的参数数量减少 5.3 倍,乘加运算数量减少 5.2 倍。

综上,MobileNetV2 提供了一个非常高效的面向移动设备的模型,可以用作许多视觉识别任务的基础。我们现将此模型与广大学术和开源社区分享,希望借此进一步推动研究和应用开发。
-
神经网络
+关注
关注
42文章
4842浏览量
108170 -
计算机视觉
+关注
关注
9文章
1715浏览量
47717
原文标题:MobileNetV2:下一代设备上计算机视觉网络
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
高通下一代顶级SoC骁龙855,以打造下一代5G设备
Supermicro将在 CES上发布下一代单路平台
小草带你体验 下一代LabVIEW 软件
支持更多功能的下一代汽车后座娱乐系统
为什么说射频前端的一体化设计决定下一代移动设备?
如何建设下一代蜂窝网络?
谷歌推出新的移动框架MobileNetV2提高多种计算机视觉任务
英国表示允许华为向该国提供下一代移动网络即5G网络建设
【R329开发板测评】全志 R329开发板跑 mobilenetv2




评论