 CVPR 2018 上10篇最酷论文,渴望进步的人都在看
CVPR 2018 上10篇最酷论文,渴望进步的人都在看

▌前言
作为计算机视觉领域的顶级会议,2018年的计算机视觉和模式识别会议(CVPR) 上周在美国盐湖城举行。今年的 CVPR共收到3300份来稿并接收了其中的979份。超过6500人参加了今年的会议,这间容纳6500人的房间座无虚席,堪称是一届史诗般的盛会:
每年的 CVPR都会吸引众多优秀的人才和他们最新的研究成果,总可以看到学到新的东西。当然还有那些发表了最新并具有突破性成果的论文,为该领域带来很棒的新知识。这些论文经常在计算机视觉的许多子领域形成最新的技术。
最近,我们看到了一些开箱即用且富有创意的论文!随着最近深度学习在计算机视觉领域的突破性进展,我们仍然在探索并发现一切未知的可能性。许多论文展示了深度神经网络在计算机视觉领域中的全新应用。它们可能不是最根本的开创性作品,但就它们从新颖有趣的角度呈现出全新的想法,为相关领域提供了创造性和启发性的视角。总而言之,这些都是非常酷的作品!
在这里,我将展示我认为在本届 CVPR上最酷的10篇论文。我们将看到最近使用深度网络实现的一些新应用,以及如何进一步使用它们。你可以在阅读过程中根据自己的喜好选择性地进行阅读。让我们开始吧!
▌Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization(用合成数据训练深度网络:通过领域随机化来弥合现实差距)
这篇论文出自Nvidia团队的研究,使用合成数据来训练卷积神经网络(CNN)。 他们为虚幻引擎(Unreal Engine 4) 创建了一个插件用于生成合成的训练数据。这项研究的关键在于他们对训练数据进行了随机化,使其能够包含多种变量,包括:
目标的数量和类型
干扰物的数量,类型,颜色和尺度
感兴趣物体的纹理特征及图片的背景
虚拟摄像机相对于场景的位置
相机相对于场景的角度
光点的数量和位置
他们展示了一些非常有前途的实验结果,证明了合成数据预训练的有效性,这是先前研究从未实现过的结果。如果你之前并不了解这个重要知识的话,那么这项研究将会启发你如何生成并使用合成数据。
▌WESPE: Weakly Supervised Photo Enhancer for Digital Cameras(WESPE:用于数码相机的弱监督照片增强器)
这项研究通过训练生成对抗网络(GAN) 来从美学上自动化增强图片。该研究最酷的地方在于以一种弱监督的方式:你不需要输入-输出的图像对。训练网络时,你只需要一组“好看”的图像(用于输出基础事实) 和一组想要增强的“不好看”的图像(用于输入图像)。然后,通过训练GAN产生输入图像的增强版本,通常所生成的图像会极大地增强原图像的颜色和对比度。
由于不需要精确的图像对,因而你能够快捷方便地使用这个图像增强器。我喜欢这项研究的原因主要是因为它是一种弱监督的方法。虽然我们离无监督学习似乎还很遥远,但对计算机视觉的许多子领域而言,弱监督学习似乎是一个充满希望且值得研究的方向。
▌Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++(用Polygon-RNN ++对图像分割数据集进行高效地交互式标注)
深度神经网络之所以能够表现出如此强大性能的主要原因之一是大型且完全带标注的可用的数据集。然而,对于许多计算机视觉任务而言,这样的数据既费时又昂贵。特别对于图像分割任务而言,我们需要对图像中的每个像素进行类别标注,你可以想象其中的困难性有多大!
Polygon-RNN ++这项研究允许研究者只需在图像中每个目标周围设置粗糙的多边形点,然后该网络能够自动生成图像分割所需的标注信息!本文研究表明这种方法能够在实际应用中很好地推广,并可以用来为分段任务创建快速简便的数据标注!
▌Creating Capsule Wardrobes from Fashion Images
(从时尚配图中创造自己的衣柜)
“嗯,我今天应该穿什么?”如果有人能够每天早上为你解决这个问题,那将再好不过了。
本文研究中,作者设计了一种模型,基于给定的候选服装和配件清单,模型通过收集一组最小的项目集,提供最全面的服装混合搭配的方案。研究中模型使用目标函数进行训练,这些目标函数旨在捕获视觉兼容性,多功能性及特定用户的偏好等关键要素。有了这种衣柜 (Capsule Wardrobes),你可以轻松从衣橱中挑选最佳的服装搭配。
▌Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation (Super SloMo:视频插值中多个中间帧的高质量估计)
你曾经是否想过以超慢的动作拍摄超级酷炫的东西呢?Nvdia的这项研究 Super SloMo就能帮你实现!研究中他们使用 CNN估计视频的中间帧,并能将标准的30fps视频转换为240fps的慢动作!该模型估计视频中间帧之间的光流信息,并在这些信息中间插入视频帧,使慢动作的视频看起来也能清晰锐利。
▌Who Let The Dogs Out? Modeling Dog Behavior From Visual Data(用视觉数据构建狗的行为模型)
这可能是有史以来最酷的研究论文!这项研究的想法是试图模拟狗的思想和行为。研究人员将许多传感器连接到狗的四肢以收集其运动和行为数据;。此外,他们还在狗的头部安装一个摄像头,以便从狗的视角获取相应的运动信息。然后,将一组CNN特征提取器用于从视频帧获取图像特征,并将其与传感器数据一起传递给一组LSTM模型,以便学习并预测狗的动作和行为。这是一项非常新颖而富有创造性的应用研究,其整体的任务框架及独特的执行方式都是本文的亮点!希望这项研究能够为我们未来收集数据和应用深度学习技术的方式带来更多的创造力。
▌Learning to Segment Every Thing(学习分割一切)
在过去的几年里,何凯明团队 (以前在微软研究院,现就职于 Facebook AI Research) 提出了许多重大的计算机视觉研究成果。他们的研究最棒之处在于将创造力和简单性相结合,诸如将 ResNets和Mask R-CNN相结合的研究,这些都不是最疯狂或最复杂的研究思路,但是它们简单易行,并在实践中非常有效。
该团队最新的研究 Learning to Segment Every Thing是 Mask R-CNN研究的扩展,它使模型准确地分割训练期间未出现的类别目标!这对于获取快速且廉价的分割数据标注是非常有用的。事实上,该研究能够获得一些未知目标的基准分割效果(baseline segment),这对于在自然条件中部署这样的分割模型来说是至关重要的,因为在这样的环境下可能存在许多未知的目标。总的来说,这绝对是我们思考如何充分利用深层神经网络模型的正确方向。
▌Soccer on Your Tabletop(桌上足球)
本文的研究是在FIFA世界杯开幕时正式发表的,理应获得最佳时机奖!这的确是CVPR上在计算机视觉领域的“更酷”应用之一。简而言之,作者训练了一个模型,在给定足球比赛视频的情况下,该模型能够输出相应视频的动态3D重建,这意味着你可以利用增强现实技术在任何地方查看它!
本文最大的亮点是结合使用许多不同类型的信息。使用视频比赛数据训练网络,从而相当容易地提取3D网格信息。在测试时,提取运动员的边界框,姿势及跨越多个帧的运动轨迹以便分割运动员。接着你可以轻松地将这些3D片段投射到任何平面上。在这种情况下,你可以通过制作虚拟的足球场,以便在 AR条件下观看的足球比赛!在我看来,这是一种使用合成数据进行训练的方法。无论如何它都是一个有趣的应用程序!
▌LayoutNet: Reconstructing the 3D Room Layout from a Single RGBImage(LayoutNet:从单个RGB图像重建3D房间布局)
这是一个计算机视觉的应用程序,我们可能曾经想过:使用相机拍摄某些东西,然后用数字3D技术重建它。这也正是本文研究的目的,特别是重建 3D房间布局。研究人员使用全景图像作为网络的输入,以获得房间的完整视图。网络的输出是3D重建后的房间布局,具有相当高的准确性!该模型足够强大,可以推广到不同形状、包含许多不同家具的房间。这是一个有趣而好玩、又不需要投入太多研究人员就能实现的应用程序。
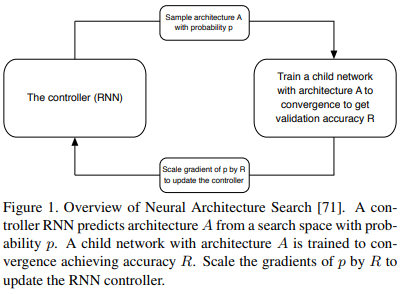
▌Learning Transferable Architectures for Scalable Image Recognition (学习可迁移的结构用于可扩展的图像识别任务)
最后要介绍的是一项许多人都认为是深度学习未来的研究:神经架构搜索(NAS)。NAS背后的基本思想是我们可以使用另一个网络来“搜索”最佳的模型结构,而不需要手动地设计网络结构。结构搜索过程是基于奖励函数进行的,通过奖励模型以使其在验证数据集上有良好的表现。此外,作者在论文中表明,这种模型结构比起手动设计的模型能够获得更高的精度。这将是未来巨大的研究方向,特别是对于设计特定的应用程序而言。因为我们真正关注的是设计好的NAS算法,而不是为我们特定的应用设计特定的网络。精心设计的NAS算法将足够灵活,并能够为任何任务找到良好的网络结构。
▌结束语
希望你能从中学到一些新的、有用的东西,甚至能够为你自己的研究与工作找到一些新的想法!
-
3D
+关注
关注
9文章
3023浏览量
115577 -
深度学习
+关注
关注
73文章
5608浏览量
124635 -
cnn
+关注
关注
3文章
356浏览量
23547
原文标题:CVPR 2018 上10篇最酷论文,圈儿里最Cool的人都在看
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
传音相关研究成果入选计算机视觉顶会CVPR 2026

地平线11篇论文强势入选CVPR 2026

Nullmax研发团队静态元素检测和拓扑推理新成果入选CVPR 2026
从CVPR 2019看事件相机步态识别:技术突破与产品应用

MediaTek多篇论文入选全球前沿国际学术会议
地平线五篇论文入选NeurIPS 2025与AAAI 2026

后摩智能六篇论文入选四大国际顶会

理想汽车12篇论文入选全球五大AI顶会
思必驰与上海交大联合实验室五篇论文入选NeurIPS 2025
理想汽车八篇论文入选ICCV 2025
传音多媒体团队揽获CVPR NTIRE 2025两项挑战赛冠亚军

NVIDIA荣获CVPR 2025辅助驾驶国际挑战赛冠军
后摩智能四篇论文入选三大国际顶会
云知声四篇论文入选自然语言处理顶会ACL 2025




评论