 格灵深瞳三项成果获得国际顶级学术会议认可
格灵深瞳三项成果获得国际顶级学术会议认可

以OpenAI CLIP为代表的多模态预训练模型,为安防、电商等应用场景提供了强大的跨模态理解基础,但也存在多种技术局限性。
格灵深瞳参与研究的3项最新技术成果,涵盖图文检索、高质量图文对数据集、组合概念理解等多模态研究关键领域,突破了现有CLIP框架的局限,多项任务性能达到最先进水平,有效提升多模态表达能力。
3篇论文已入选第33届ACM国际多媒体大会(ACM MM),获得国际顶级学术会议认可。以下是论文的核心内容:
图文互搜更精准!新框架UniME判别力up
对比语言-图像预训练框架CLIP已成为多模态领域的主流方法,广泛应用于“以图搜文”或“以文搜图”等任务中。但CLIP存在三个明显短板:无法处理过长的文本;图像和文本编码器各自独立,交互不足;组合推理能力不足,例如只能看懂单词,却读不懂句子。
尽管最近的多模态大型语言模型(MLLMs)在通用视觉-语言理解方面取得了显著进展,但在学习可迁移的多模态表征方面,潜力尚未充分发挥。
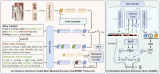
为此,研究团队提出了UniME(Universal Multimodal Embedding,通用多模态嵌入),一个新颖的两阶段训练框架,利用MLLMs学习判别性强、可应用到多样化下游任务的表征向量。在第一阶段,团队借助强大的基于LLM的教师模型,通过知识蒸馏技术,提升多模态大语言模型中的文本嵌入能力;在第二阶段,团队引入困难负样本增强指令微调,进一步增强判别性表示学习。
经过MMEB基准测试和在多个检索任务(包括短长标题检索和组合检索)上的大量实验,结果表明UniME在所有任务中均实现了稳定的性能提升,展现了卓越的判别能力和组合理解能力。
论文题目:Breaking the Modality Barrier:Universal Embedding Learning with Multimodal LLMs
研究团队:格灵深瞳、悉尼大学、通义实验室、帝国理工学院
报告链接:https://arxiv.org/abs/2504.17432
项目主页:https://garygutc.github.io/UniME/
多模态学习新范式:数据集RealSyn解锁海量未配对文档
在海量图文对上进行预训练后,CLIP在各种基准测试中表现出色。但现实中还存在大量非配对的多模态数据,例如图文交织的文档,它们蕴藏丰富的视觉-语言语义信息,尚未得到有效挖掘。
为了充分利用这些未配对文档,研究团队构建了RealSyn数据集——一种高效且可扩展的多模态文档转换新范式。团队首先建立了一套真实数据提取流程,能够从图文交错的文档中提取高质量的图像和文本。在此基础上,通过分层检索方法,高效地将每个图像与多个语义相关的现实文本关联起来。
为进一步增强视觉信息的细粒度表达,RealSyn还引入了图像语义增强生成模块,可生成与图像内容高度契合的合成文本。同时,借助语义均衡采样策略来提高数据集的多样性,让模型更好地学习长尾概念。
基于以上技术突破,团队构建了不同规模的RealSyn数据集(15M、30M 和 100M),融合了真实与合成文本。广泛的实验表明,RealSyn有效地提升了视觉-语言表示学习性能,并展现出强大的可扩展性。相较于现有大规模图文对数据集,模型在RealSyn上预训练后,在多项下游任务中达到了最先进的性能。
论文题目:RealSyn:An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
研究团队:格灵深瞳、悉尼大学、帝国理工学院
报告链接:https://arxiv.org/abs/2502.12513
项目主页:https://garygutc.github.io/RealSyn/
新框架DeGLA:既保留模型通用能力,又提升组合理解性能
通过对齐图像和文本模态,CLIP在多项下游任务中表现出色。然而,全局对比学习的特性限制了CLIP对于组合概念(例如关系和属性)的理解能力。尽管有研究采用困难负样本的方法来提高组合理解能力,但这类方法是在嵌入空间内强制使文本负样本远离图像,会显著损害模型已经掌握的通用能力。
为了解决这一矛盾,研究团队提出了一种名为“ 解耦全局-局部对齐(DeGLA)”的新训练框架,能够显著提升组合理解能力的同时,最大限度保留模型的通用能力。
首先,为保留模型的通用能力,团队在全局对齐过程中整合了自我蒸馏机制,能够有效减轻在微调过程中预训练知识的灾难性遗忘;接下来,为了提高组合理解能力,团队利用大语言模型的上下文学习能力,构建了约200万个高质量、涵盖五种类型的困难负样本,进而提出了基于图像的局部对比(IGC)损失和基于文本的局部对比(TGC)损失,以此增强视觉-语言组合理解能力。
广泛的实验结果证明了DeGLA框架的有效性。与先前的最先进方法相比,DeGLA在VALSE、SugarCrepe和ARO基准测试中平均提升了3.5%。同时,在11个数据集上的零样本分类任务中,性能平均提升了13.0%。
论文题目:Decoupled Global-Local Alignment for Improving Compositional Understanding
研究团队:格灵深瞳、北京理工大学、浙江大学
报告链接:https://arxiv.org/abs/2504.16801
项目主页:https://xiaoxing2001.github.io/DeGLA.github.io/
未来,格灵深瞳将在Glint Tech技术专栏分享更多前沿动态与创新成果,欢迎持续关注。
-
模型
+关注
关注
1文章
3811浏览量
52257 -
格灵深瞳
+关注
关注
1文章
95浏览量
6011
原文标题:格灵深瞳3项成果入选ACM MM25,聚焦多模态表征、图文对数据集及跨模态组合理解 | Glint Tech
文章出处:【微信号:shentongzhineng,微信公众号:格灵深瞳】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
格灵深瞳亮相2026 ITES深圳工业展
格灵深瞳2025年度关键词回顾
格科微电子荣膺三项权威认可
格灵深瞳邀您相约百度世界2025大会
格灵深瞳突破文本人物检索技术难题
格灵深瞳视觉基础模型Glint-MVT的发展脉络
格灵深瞳视觉基础模型Glint-MVT升级



评论