 NVMe高速传输之摆脱XDMA设计16:TLP读处理优化
NVMe高速传输之摆脱XDMA设计16:TLP读处理优化

在实际应用环境中,由于队列、PRP、数据的存储往往在不同的位置,因此完成读取过程的延时也不同,在本开发中,将队列管理与PRP都放置在了近PCIe端存储,因此读取队列与PRP的延时远远小于读取数据的延时。并且当大量不同的读请求交叉处理时,读处理模块的并行处理结构更能够充分利用PCIe的乱序传输能力来提高吞吐量。为了清晰的说明读处理模块对吞吐量的提升,设置如图3.15所示的简单时序样例,样例中PCIe TLP的tag最大为3。
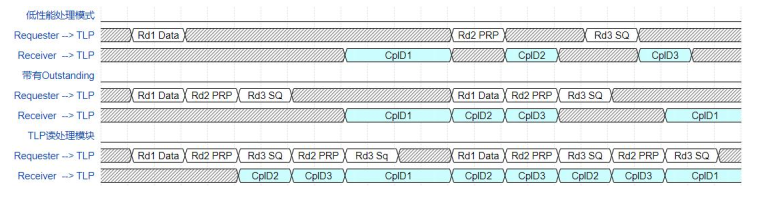
图1 TLP读处理优化时序样例图
在对应图1中第1、2行时序的低性能处理模式下,同一时间只能处理一个读事务,并且不带有outstanding能力,此时从接收到读请求到成功响应所经历的延时将会累积,造成axis_cq请求总线的阻塞。在对应图中第3、4行时序的仅带有outstanding能力的处理模式下,虽然可以连续接收多个读请求处理,但同一时间内只能处理一个事务,仍会由于较大的处理延时导致axis总线存在较多的空闲周期,实际的数据传输效率并不高。在对应图中第5、6行时序的读处理模块处理模式下,利用多个响应处理单元的并行处理能力和发送缓存,先行处理完成的CPLD可以优先发送,紧接着可以处理下一事务B站已给出相关性能的视频,使总线的传输效率和吞吐量明显提高。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
存储
+关注
关注
13文章
4935浏览量
90397 -
PCIe
+关注
关注
16文章
1503浏览量
89152 -
nvme
+关注
关注
0文章
304浏览量
23956
发布评论请先 登录
相关推荐
热点推荐
NVMe高速传输之摆脱XDMA设计42:DMA 读写功能验证与分析
事务, 数据通过 AXI 总线写入 BRAM 仿真模型。 DMA 结束后写数据计数寄存器为 256, 表示传输数据量为 256*16B 即 4KB。
图1 DMA 读测试仿真波形
NVMe
发表于 10-27 09:10
NVMe高速传输之摆脱XDMA设计30: NVMe 设备模型设计
, 不同的是在处理指令过程中, NVMe 写和读指令需要与主机进行更多的 TLP 事务交互, 包括读指令、 读写数据、
发表于 09-29 09:31
NVMe高速传输之摆脱XDMA设计27: 桥设备模型设计
Switch 上游虚拟 PCI 桥。 此外还包含一个 TYPE1 类型的配置空间封装类, 用来模拟配置空间寄存器组。 模型的每个端口的输入端对接一个 TLP事务处理程序, 该程序负责将接收到的 TLP 事务进行解析和路由转发。
发表于 09-18 09:11
NVMe高速传输之摆脱XDMA设计21:PCIe的TLP读处理
对于存储器读请求TLP,使用Non-Posted方式传输,即在接收到读请求后,不仅要进行处理,还需要通过axis_cc总线返回CPLD,这一
发表于 08-14 16:24
NVMe高速传输之摆脱XDMA设计20: PCIe应答模块设计
应答模块的具体任务是接收来自PCIe链路上的设备的TLP请求,并响应请求。由于基于PCIe协议的NVMe数据传输只使用PCIe协议的存储器读请求TL
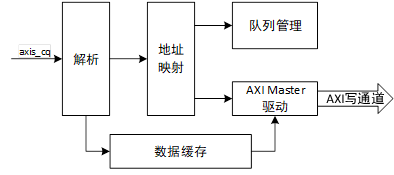
NVMe高速传输之摆脱XDMA设计20: PCIe应答模块设计
应答模块的具体任务是接收来自PCIe链路上的设备的TLP请求,并响应请求。由于基于PCIe协议的NVMe数据传输只使用PCIe协议的存储器读请求TL
发表于 08-12 16:04
NVMe高速传输之摆脱XDMA设计17:PCIe加速模块设计
PCIe加速模块负责实现PCIe传输层任务的处理,同时与NVMe层进行任务交互。如图1所示,PCIe加速模块按照请求发起方分为请求模块和应答模块。请求模块负责将内部请求事务转化为配置管理接口信号或
发表于 08-07 18:57
NVMe高速传输之摆脱XDMA设计15:PCIe的TLP读处理
对于存储器读请求TLP,使用Non-Posted方式传输,即在接收到读请求后,不仅要进行处理,还需要通过axis_cc总线返回CPLD,这一
发表于 08-04 16:54
NVMe高速传输之摆脱XDMA设计15:PCIe的TLP读处理
对于存储器读请求TLP,使用Non-Posted方式传输,即在接收到读请求后,不仅要进行处理,还需要通过axis_cc总线返回CPLD,这一
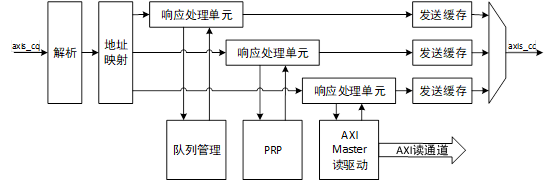
NVMe高速传输之摆脱XDMA设计14: PCIe应答模块设计
应答模块的具体任务是接收来自PCIe链路上的设备的TLP请求,并响应请求。由于基于PCIe协议的NVMe数据传输只使用PCIe协议的存储器读请求TL
NVMe高速传输之摆脱XDMA设计14: PCIe应答模块设计
应答模块的具体任务是接收来自PCIe链路上的设备的TLP请求,并响应请求。由于基于PCIe协议的NVMe数据传输只使用PCIe协议的存储器读请求TL
发表于 08-04 16:44
NVMe IP高速传输却不依赖XDMA设计之八:系统初始化
采用XDMA是许多人常用xilinx库实现NVMe或其他传输的方法。但是,XDMA介绍较少,在高速存储设计时,尤其是PCIe4.0模式下,较
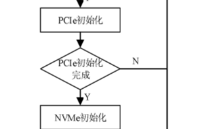
NVMe高速传输之摆脱XDMA设计之十:NVMe初始化状态机设计
在完成PCIe配置初始化后,PCIe总线域的地址空间都分配完毕,可以执行传出存储读写TLP,系统初始化进入NVMe配置初始化。NVMe配置初始化主要完成NVMe设备BAR空间的
发表于 07-05 22:03



评论